aplicaciÓn prÁctica de la visiÓn artificial para el reconocimiento de...
TRANSCRIPT

APLICACIÓN PRÁCTICA DE LA VISIÓN ARTIFICIAL PARA EL
RECONOCIMIENTO DE ROSTROS EN UNA IMAGEN, UTILIZANDO REDES
NEURONALES Y ALGORITMOS DE RECONOCIMIENTO DE OBJETOS DE LA
BIBLIOTECA OPENCV
EDISON RENE CABALLERO BARRIGA
COD: 20162099033
GRUPO 2
GRUPO SEMINARIO: 24
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS
FACULTAD DE INGENIERIA
ESPECIALIZACIÓN EN INGENIERÍA DE SOFTWARE
BOGOTA D.C.
2017


APLICACIÓN PRÁCTICA DE LA VISIÓN ARTIFICIAL PARA EL
RECONOCIMIENTO DE ROSTROS EN UNA IMAGEN, UTILIZANDO REDES
NEURONALES Y ALGORITMOS DE RECONOCIMIENTO DE OBJETOS DE LA
BIBLIOTECA OPENCV
EDISON RENE CABALLERO BARRIGA
COD: 20162099033
GRUPO 2
GRUPO SEMINARIO: 24
DIRECTOR
ALEJANDRO PAOLO DAZA
REVISOR
JORGE MARIO CALVO
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS
FACULTAD DE INGENIERIA
ESPECIALIZACIÓN EN INGENIERÍA DE SOFTWARE
BOGOTA D.C.
2017


TABLA DE CONTENIDO
INTRODUCCIÓN .................................................................................................................. 7
PARTE 1. DESCRIPCIÓN DE LA INVESTIGACIÓN ........................................................ 8
CAPÍTULO 1. DESCRIPCIÓN DE LA INVESTIGACIÓN ...................................... 8
Objetivo general .................................................................................................................. 9
Objetivos específicos .......................................................................................................... 9
PARTE 2. DESARROLLO DE LA INVESTIGACIÓN ..................................................... 24
CAPÍTULO 2. RECONOCIMIENTO BIOMETRICO .............................................. 24
CAPÍTULO 3. DETECCIÓN Y RECONOCIMIENTO DE ROSTROS ................... 26
CAPÍTULO 4. DESARROLLO DE LA APLICACIÓN ........................................... 32
PARTE 3. CIERRE DE LA INVESTIGACIÓN .................................................................. 50
CAPÍTULO 5. RESULTADOS Y DISCUSIÓN ....................................................... 50
CAPÍTULO 6. CONCLUSIONES ............................................................................. 51
CAPÍTULO 7. PROSPECTIVA DEL TRABAJO DE GRADO ............................... 51
PARTE 4. BIBLIOGRAFIA ................................................................................................ 52
PARTE 5. ANEXOS ............................................................................................................ 57

IMAGENES
Imagen 1. Mapa de Conceptos para detección y Reconocimiento de Rostros en Imágenes.
Fuente: Realización Propia ................................................................................................... 13
Imagen 2. Características de Tipo Haar. (OpenCv O. , 2017) .............................................. 16
Imagen 3. Características de Tipo Haar aplicadas a la detección de un rostro. (OpenCv O. ,
2017) ..................................................................................................................................... 16
Imagen 8. Modelo de desarrollo iterativo-incremental. (Sommerville, Ingenieria del
Software, 2006) .................................................................................................................... 20
Imagen 9. Fases del desarrollo en cascada. (Pressman, 2005) ............................................. 21
Imagen 4. Etapas del método para detección de rostros de Viola-Jones. Fuente: Realización
propia. ................................................................................................................................... 27
Imagen 4. Calculo de la imagen integral de Viola-Jones. (OpenCv O. , 2017) ................... 28
Imagen 5. Filtros Haar rotados, trasladados y con cambios de escala. (OpenCv O. , 2017) 29
Imagen 6. Detección de rostros utilizando características Haar en cascada. (OpenCv O. ,
2017) ..................................................................................................................................... 29
Imagen 10. Vista del Negocio. Realización Propia. ............................................................. 42
Imagen 11. Vista de Aplicación. Realización Propia. .......................................................... 43
Imagen 12. Vista de Infraestructura. Realización Propia. .................................................... 43
Imagen 13. Vista de Capas. Realización Propia. .................................................................. 44
Imagen 14. Solución y proyecto Windows Forms en .Net. Realización Propia. .................. 45
Imagen 15. Formulario de la aplicación. Aplicación de Reconocimiento de Rostros.
Realización Propia. ............................................................................................................... 45
Imagen 16. Imagen con un rostro detectado por la aplicación. Aplicación de
Reconocimiento de Rostros. Realización Propia. ................................................................. 47
Imagen 17. Entrenamiento de la aplicación. Aplicación de Reconocimiento de Rostros.
Realización Propia. ............................................................................................................... 47
Imagen 18. Imágenes de entrenamiento. Aplicación de Reconocimiento de Rostros.
Realización Propia. ............................................................................................................... 48
Imagen 19. Imagen donde se indica el nombre de la persona. Realización Propia. ............. 48
Imagen 20. Imagen donde se indica el nombre dos personas diferentes. Realización Propia.
.............................................................................................................................................. 49

7
INTRODUCCIÓN
El estudio de los mecanismos de la visión humana es el objetivo de la Visión Artificial o
también llamada Visión por Computador. La visión computacional busca crear sistemas
que sean capaces de reconocer un objeto determinado en una imagen. Para los humanos
esta tarea es natural y es realizada constantemente sin preocuparse por el cómo; pero
cuando trasladamos esta tarea a una máquina, nos encontramos con varias dificultades que
resolver.
Para definir la visión computacional podemos optar por la definición de Marr (Marr D. ,
1982) en la cual hay aspectos importantes que nos llevan a entender la visión
computacional como el estudio de los procesos asociados a la visión natural, y que tiene
como fin entender estos procesos y construir maquinas con capacidades similares.
Uno de los campos con mayor proyección dentro de la Visión Artificial es el relacionado
con el Reconocimiento Biométrico Facial, el cual se centra en el mismo identificador que
utilizamos los humanos para distinguir una persona de otra: su rostro. Por tanto, uno de los
objetivos principales es comprender el complejo sistema visual humano y como se
representan los rostros para lograr discriminar identidades con exactitud.
La principal dificultad en el proceso de reconocimiento de rostros, radica en las enormes
variaciones que existen entre las distintas imágenes del rostro de un mismo individuo. Estas
diferencias son dadas por los gestos, la intensidad o ausencia de luz, diferentes peinados,
maquillaje y accesorios, por los cuales una misma persona puede parecer diferente en dos
imágenes.
Este proyecto se enfoca en estudiar los diferentes métodos y algoritmos que permiten
detectar un rostro en una imagen, y desarrollar una aplicación que pueda ser entrenada para
realizar el reconocimiento de una persona especifica dentro de la imagen.

8
PARTE 1. DESCRIPCIÓN DE LA INVESTIGACIÓN
CAPÍTULO 1. DESCRIPCIÓN DE LA INVESTIGACIÓN
1.1. PLANTEAMIENTO/IDENTIFICACIÓN DEL PROBLEMA
La visión artificial por computadora es una disciplina de gran crecimiento en los últimos
años, su futuro más prometedor se encuentra en la creación de máquinas autónomas
capaces de interactuar de forma inteligente con el entorno. Para lograr la interacción de las
maquinas con su entorno, es necesario desarrollar un sistema que tenga la capacidad de
percibirlo e interpretarlo (Branch & Olague, 2001).
El término Visión Artificial dentro del campo de la Inteligencia Artificial puede
considerarse como el conjunto de todas aquellas técnicas y modelos que nos permiten el
procesamiento, análisis y explicación de cualquier tipo de información espacial obtenida a
través de imágenes digitales (Pajares Martinsanz & Santos Peñas, 2006).
La visión artificial por computadora utiliza sensores ópticos, como cámaras fotográficas y
de video, para adquirir imágenes y luego procesarlas mediante algún tipo de procesador,
con el fin de extraer y analizar cierto tipo de propiedades de la imagen capturada (Múnera
Salazar & Manzano Herrera, 2012). De lo anterior, podemos concluir que la visión
computacional hace uso de computadoras y cámaras para adquirir, analizar e interpretar
imágenes de una forma equivalente a la inspección visual humana.
Dentro de la visión por computadora, la detección de objetos es el tópico donde se puede
encontrar mayores aplicaciones en la industria, la medicina, y la seguridad. La industria
automotriz es quizás aquella en la que se han realizado mayores aplicaciones en los últimos
años, utilizando la visión artificial para la creación de vehículos de conducción autónoma.
En la industria de dispositivos para la seguridad, la identificación biométrica y la identidad
digital se han convertido en uno de las técnicas más utilizadas en la autenticación de
identidad antifraudes y la seguridad en la protección de datos (Calle, 2005).

9
La detección automática de objetos en imágenes sigue siendo un reto y una fuente muy
interesante de oportunidades para el desarrollo de investigaciones y estudios dentro de la
visión por computadora. El presente trabajo, busca contribuir con el crecimiento de este
campo, presentando una forma sencilla de entrenar una red neuronal que permita reconocer
una persona, utilizando técnicas existentes y algoritmos propios de la visión artificial que
nos provee la biblioteca OpenCV (OpenCv, 2017).
1.2. OBJETIVOS
Objetivo general
Crear un prototipo de aplicación que permita entrenar una red neuronal, utilizando técnicas
de visión artificial y la biblioteca OpenCV, para reconocer el rostro de una persona en una
imagen.
Objetivos específicos
• Identificar, analizar y evaluar los diferentes algoritmos de la visión artificial, que
permitan realizar el reconocimiento de un objeto en una imagen.
• Analizar y evaluar las técnicas de visión artificial y de biometría que permitan la
identificación de una persona mediante sus características faciales, para utilizarlas
en el proceso de identificación de una persona mediante su rostro.
• Implementar una red neuronal que permitan reconocer el rostro de una persona en
una imagen, mediante técnicas y algoritmos de entrenamiento implementados por la
biblioteca de visión artificial - OpenCV.
1.3. JUSTIFICACIÓN DEL TRABAJO/INVESTIGACIÓN
En la actualidad los sistemas biométricos juegan un rol fundamental en los procesos de
reconocimiento de personas, enfocados a políticas de seguridad públicas y privadas. El
reconocimiento biométrico facial es muy utilizado en el control de acceso a edificios,
laboratorios y oficinas.
Los gobiernos también se apoyan en la biometría para identificar personas y reforzar la
seguridad en aeropuertos y ciudades, y así poder capturar personas sospechosas o con

10
pasado delictivo (Rodríguez Salavarría, 2009). La industria de reconocimiento facial
basado en computadoras ha hecho muchos adelantos útiles en la pasada década; sin
embargo, la necesidad de sistemas de mayor precisión persiste.
La biometría y en especial el reconocimiento facial ha recibido grandes aportes de parte de
la industria, en especial de la Industria Automotriz y los prototipos de vehículos
autónomos. Desde la informática y la ingeniería también se aborda el problema del
reconocimiento de un rostro en una imagen. Para lograr el reconocimiento se utilizan
técnicas de procesamiento de imágenes, visión por computador, reconocimiento de patrones
y redes neuronales.
A pesar de estos adelantos y los constantes estudios sobre el tema, el problema del
reconocimiento de rostros sigue vigente. Las principales dificultades del reconocimiento
están relacionadas con los diferentes factores externos que generan variaciones en el rostro
de una persona, estos están dados por las iluminación a la cual este expuesta la persona al
momento de capturar la imagen, los posibles accesorios que pueda llevar, como gafas o
sombreros y también las variaciones fisionómicas relacionadas con el paso del tiempo.
Teniendo en cuenta lo anterior, para abordar el reconocimiento facial es necesario
establecer ciertas restricciones contextuales y llevarlo a situaciones concretas donde se
tenga cierto control sobre los posibles factores de variación. De esta manera, resulta posible
obtener resultados satisfactorios en situaciones concretas y en entornos restringidos y muy
controlados.
El presente proyecto, está enmarcado dentro del ámbito de la visión artificial y pretende
aplicar las técnicas y procesos propios de esta disciplina para el procesamiento y
reconocimiento de entornos mediante imágenes digitales captadas por una cámara. La
información recibida en la imagen será interpretada utilizando los algoritmos propios de la
visión por computadora, con el fin de poder reconocer el rostro de una persona especifica
dentro de la imagen.

11
1.4. HIPÓTESIS
La visión artificial provee conceptos y técnicas que, aplicadas mediante algoritmos y redes
neuronales, permiten detectar un objeto especifico presente en una imagen. Una de las
bibliotecas de visión artificial que implementa y nos permite realizar este trabajo es
OpenCV (Geeky, 2011), esta biblioteca implementa algoritmos para la detección de objetos
y también para la detección de rostros en imágenes y video.
OpenCV nos facilita la terea de detectar rostros, ya que cuenta con clasificadores
entrenados para esta tarea, además tiene implementado el algoritmo de Viola-Jones (Viola
& Jones, Rapid object detection using a boosted cascade of simple features, 2001), el cual
permite realizar este proceso de detección de rostros de forma sencilla y a muy bajo costo
computacional. En caso de que lo necesitemos podemos crear nuestros propios
clasificadores, OpenCv nos permite entrenar nuestros propios clasificadores utilizando
AdaBoost (OpenCv O. , 2017).
La biblioteca OpenCV puede ser integrada con diferentes lenguajes de programación como:
C++, Java, Python y los lenguajes de la plataforma .Net; por lo cual, es posible utilizarla
para crear una aplicación para entornos web o de escritorio, que permita la detección de
rostros dentro de una imagen tomada mediante una cámara.
1.5. MARCO REFERENCIAL
1.5.1. MARCO TEÓRICO
La visión artificial o visión por computador, pretende reproducir artificialmente el sentido
de la vista humana mediante el procesamiento e interpretación de imágenes captadas desde
diferentes dispositivos, como cámaras y utilizando computadores para su procesamiento.
El sistema de visión artificial requiere de dos elementos fundamentales, el primero es el
hardware encargado de la percepción de las imágenes y el segundo el software encargado
del procesamiento de la información (Pajares & De La Cruz, 2004).

12
Debido a la complejidad del proceso, la visión artificial se ha dividido en varias etapas o
procesos. En cada una de ellas, las imágenes y la cantidad de información se va refinando
hasta lograr el reconocimiento del objeto buscado. Generalmente se consideran cuatro
procesos (Sánchez, 2002):
• Captura: Consiste en la captura de las imágenes por medio de un sensor.
• Análisis (Tratamiento digital): Mediante la aplicación de filtros se descartan partes
de la imagen y se enfoca en las partes con mayor probabilidad de coincidencia con
lo buscado.
• Segmentación: Consiste en aislar los elementos de la imagen que se desean analizar,
La segmentación permite comprender la imagen individualizando sus elementos.
• Reconocimiento (Clasificación): En ella se distinguen los objetos segmentados,
mediante al análisis de ciertas características, que se establecen previamente para
diferenciarlos.
Siguiendo estos procesos e implementándolos mediante algoritmos de procesamiento y
apoyándose en redes neuronales, es posible identificar el objeto buscado dentro de una
imagen.
1.5.2. MARCO CONCEPTUAL
El reconocimiento automático de rostro busca extraer los rasgos significativos de un rostro
presente en una imagen, ponerlos en una representación útil, realizar algún tipo de
clasificación en ellos y lograr, mediante algoritmos de detección y patrones, la ubicación de
un rostro en la imagen.
El reconocimiento facial basado en características fisiológicas y geométricas, es
probablemente el método más intuitivo y utilizado para el reconocimiento de un rostro. Uno
de los primeros sistemas automáticos de reconocimiento facial utilizó posición de los ojos,
oídos y nariz, para construir un vector de características (distancia entre los puntos, el
ángulo entre ellos) (PHILLIPS & et al., 2005).

13
Para lograr el reconocimiento de un rostro en una imagen se realizan dos etapas de
procesamiento con sus respectivas técnicas y algoritmos. En la primera etapa se utilizan
clasificadores en cascada y el algoritmo de Viola-Jones para lograr detectar un rostro dentro
de la imagen (Viola & Jones, Robust real-time face detection, 2004). Viola-Jones utiliza
clasificadores en cascada los cuales se entrenan utilizando el algoritmo de AdaBoost
(Mayhua-Lopez, Gómez-Verdejo, & Figueiras-Vidal, 2012), con el cual se logra crear
clasificadores fuertes a partir de clasificadores débiles.
En la segunda etapa se realiza el reconocimiento del rostro de una persona, comparando el
rostro detectado en la imagen con una seria de imágenes guardadas llamadas imágenes de
muestra. Para este reconocimiento, se utiliza el algoritmo de Eigenfaces (Turk & Pentland,
Eigenfaces for recognition, 1991), el cual realiza la comparación de las imágenes de
muestra con la del rostro detectado, e indica si existe concordancia.
Para observar la relación de estos conceptos con las etapas realizadas para la detección y
reconocimiento, se elaboró el siguiente mapa conceptual. En él se observan los conceptos
más relevantes en el proceso y su relación con el proceso general que permite el
reconocimiento de rostros utilizando la librería de visión artificial OpenCV (OpenCv,
2017).
Imagen 1. Mapa de Conceptos para detección y Reconocimiento de Rostros en Imágenes. Fuente: Realización
Propia

14
1.5.2.1. Machine Learning
El aprendizaje automático (ML), es un tipo de inteligencia artificial (IA) que proporciona a
los ordenadores la capacidad de aprender sin ser explícitamente programados (Michalski,
Carbonell, & Mitchell, 2013). El aprendizaje automático se centra en el desarrollo de
programas informáticos que pueden cambiar cuando se exponen a nuevos datos.
El proceso de aprendizaje automático es similar al de la minería de datos. Ambos sistemas
buscan a través de datos para encontrar patrones. Sin embargo, en lugar de extraer datos
para la comprensión humana, como es el caso de las aplicaciones de minería de datos, el
aprendizaje automático utiliza esos datos para detectar patrones en los datos y ajustar las
acciones del programa en consecuencia (Pedregosa, Varoquaux, & Gramfort, 2011).
Los algoritmos de aprendizaje automático se clasifican a menudo como supervisados o no
supervisados. Los algoritmos supervisados pueden aplicar lo que se ha aprendido en el
pasado a los nuevos datos. El aprendizaje supervisado busca realizar predicciones a futuro
basándose en características y comportamientos que se han detectado y clasificado en datos
almacenados, datos históricos o conocimiento previo en el que nos podemos apoyar para
hacer predicciones o tomar decisiones (Sebastiani, 2002).
Los algoritmos no supervisados pueden extraer inferencias de conjuntos de datos. El
aprendizaje no supervisado a diferencia del supervisado, usa datos históricos que no estén
etiquetados ni clasificados, con el fin de explorarlos y encontrar una estructura para
relacionarlos y para organizarlos.
1.5.2.2. Algoritmo de Boosting
Boosting se refiere a un método general y probablemente el más eficaz para producir una
Regla de predicción muy precisa, por la combinación de reglas débiles y moderadamente
imprecisas (Kearns & Valiant, 1994). El Boosting consiste en tomar una serie de
clasificadores débiles y combinarlos para construir un clasificador fuerte con la precisión
deseada. La idea se basa en que varios clasificadores sencillos, cada uno con una precisión

15
muy baja, se combinan para formar un clasificador de mayor precisión (Gómez-Verdejo,
Ortega-Moral, Arenas-García, & Figueiras-Vidal, 2006).
El Boosting tiene sus raíces en un marco teórico para el estudio del aprendizaje de máquina
(Machine Learning), llamado "PAC" (Probably Approximately Correct) Learning Model,
expuesto en 1984 por Leslie Valiant (Valiant, 1984). Convirtiéndose en el modelo más
importante en la teoría del aprendizaje computacional.
Kearns y Valiant fueron los primeros en plantear la cuestión de si un algoritmo de
aprendizaje "débil" puede ser "Impulsado", utilizando PAC, en un algoritmo más preciso
"fuerte" (Kearns & Valiant, 1994). Los primeros experimentos con estos primeros
Algoritmos de impulsos fueron llevados a cabo en una tarea OCR (Optical Character
Recognition).
Entre los diferentes algoritmos de impulso (Boosting), tres de los más importantes son:
• AdaBoost (Adaptive Boosting)
• Gradient Tree Boosting
• XGBoost
AdaBoost, como se mencionó anteriormente este es el algoritmo utilizado por Viola-Jones
para realizar el entrenamiento de los clasificadores en cascada que se utilizan en el
reconocimiento de rostros en imágenes (Viola & Jones, Rapid object detection using a
boosted cascade of simple features, 2001).
1.5.2.3. Características Haar
Las características Haar-Like, son las características utilizadas en la visión artificial para la
detección de objetos en imágenes digitales. Estas características son utilizadas por el
método de la Viola y Jones (Viola & Jones, Robust real-time face detection, 2004). Una
simple característica rectangular de tipo Haar puede definirse como la diferencia de la suma
de píxeles de las áreas dentro del rectángulo, que puede estar en cualquier posición y escala
dentro de la imagen original (Papageorgiou, Oren, & Poggio, 1998).

16
Imagen 2. Características de Tipo Haar. (OpenCv O. , 2017)
Por ejemplo, considere la siguiente imagen. La fila superior muestra dos características
Haar, aplicadas a una imagen.
Imagen 3. Características de Tipo Haar aplicadas a la detección de un rostro. (OpenCv O. , 2017)
La primera característica seleccionada se basa en la propiedad de que la región de los ojos
es a menudo más oscura que la región de la nariz y las mejillas. La segunda característica
seleccionada se basa en la propiedad de que los ojos son más oscuros que el puente de la
nariz.
1.5.2.4. Clasificador Débil
Viola y Jones utilizan un algoritmo que busca entre una gran cantidad y variedad de
características Haar de la imagen, un clasificador débil o sencillo se encarga de buscar en la
imagen características sencillas que correspondan con un posible rostro. Se llama débil

17
porque solo no puede clasificar la imagen, pero junto con otros clasificadores forma un
clasificador fuerte.
1.5.2.5. Clasificador Fuerte
Un clasificador fuerte, está formado por varios clasificadores débiles. Este clasificador
busca características de mayor complejidad en la imagen. El clasificador fuerte es una suma
ponderada de estos clasificadores débiles.
1.5.2.6. AdaBoost
AdaBoost (Adaptive Boosting), propone entrenar iterativamente una serie de clasificadores
base, de tal modo que cada nuevo clasificador preste mayor atención a los datos
clasificados erróneamente por los clasificadores anteriores, y combinarlos de tal modo que
se obtenga un clasificador con elevadas prestaciones (Mayhua-Lopez, Gómez-Verdejo, &
Figueiras-Vidal, 2012).
Para ello, durante una serie de iteraciones entrena un clasificador que implementa una
función asignándole un peso de salida, y lo añade al conjunto de modo que la salida global
del sistema se obtenga como combinación lineal ponderada de todos los clasificadores base
(Muñoz-Romero, Arenas-García, & Gómez-Verdejo, 2009).
Para conseguir que cada nuevo clasificador preste mayor atención a los datos más erróneos
se emplea una función de énfasis que pondera la importancia de cada dato durante el
entrenamiento del clasificador.
1.5.2.7. Clasificador Haar en Cascada
El Clasificador Haar en cascada, es un método desarrollado por Viola-Jones (Viola &
Jones, Rapid object detection using a boosted cascade of simple features, 2001) y es una
versión del algoritmo Adaboost (Freund & Schapire, 1997). Es un clasificador basado en
árboles de decisión con entrenamiento supervisado. Estos clasificadores se utilizan para
realizar el reconocimiento de un rostro en una imagen, utilizando clasificadores débiles
para cada una de las características que se desea detectar.

18
En el análisis de una imagen en busca de un rostro, se debe recorrer la imagen
completamente, esto se realiza tomando pequeñas ventanas de la imagen original. La mayor
parte de las ventanas que se analizan corresponden con porciones de la imagen donde no se
encuentran rostros, por lo tanto, un método rápido y sencillo, es analizar la pequeña ventana
de la imagen, si no es un rostro, desecharla y no procesarla de nuevo. De esta manera, se
optimiza el tiempo necesario para comprobar una posible región de un rostro en la imagen
completa.
Para realizar el proceso mencionado anteriormente, Viola-Jones utiliza la Cascada de
Clasificadores. En lugar de aplicar todas las características, en una ventana, agrupa las
características en diferentes etapas de los clasificadores y aplica una por una.
(Normalmente las primeras etapas contendrán un número muy reducido de características a
usar). Si una ventana falla en la primera etapa se desecha y no se evalúan las características
restantes en la ventana. Si pasa, se aplica la segunda etapa de funciones y se continua el
proceso. La ventana que pasa por todas las etapas es una región donde se encuentra un
rostro.
1.5.2.8. Lenguaje C# de .Net
El lenguaje C#, (See Sharp), es un híbrido de C y C ++, es un lenguaje de programación de
Microsoft (Microsoft, 2017). C # es un lenguaje de programación orientado a objetos
utilizado con servicios Web basados en XML en la plataforma .NET y diseñado para
mejorar la productividad en el desarrollo de aplicaciones web.
C# cuenta con seguridad de tipos, la recolección de basura, declaraciones de tipo
simplificados, control de versiones y soporte escalabilidad, y otras características que hacen
que las soluciones de desarrollo más rápido y más fácil, especialmente para COM + y
servicios Web. Los críticos de Microsoft han señalado las similitudes entre C # y Java.

19
Microsoft define c#, como: C # es un lenguaje orientado a objetos elegante y de tipo seguro
que permite a los desarrolladores crear una variedad de aplicaciones seguras y robustas que
se ejecutan en .NET Framework (Microsoft, 2017).
1.5.3. MARCO HISTÓRICO
En el siglo XVI se desarrolla la teoría de la perspectiva, las Máquinas de Perspectiva
ayudan a los pintores a reproducir en una imagen, exactamente la perspectiva de un objeto
observado, sin tener que hacer cálculos matemáticos.
En el siglo XIX el químico francés Joseph Nicéphore Niépce, considerado el inventor de la
fotografía, logra fijar una imagen en una superficie fotosensible ubicada dentro de una
cámara obscura (BATCHEN, 2004). Posteriormente, en 1838 el químico francés Daguerre
hizo el primer proceso fotográfico práctico. Daguerre utilizó una placa fotográfica que era
revelada con vapor de mercurio y fijada con trisulfuro de sodio, este se emplea sobre todo
como fijador en la fotografía (Mery, 2004).
Un hito importante en el inicio de la formulación de un enfoque para la visión artificial, fue
acotado por Larry Roberts (Roberts, 1963), que trabajo ampliamente en los inicios del
internet desde el proyecto ARPA, el cual, en 1961 creo un software que podía ver una
estructura de bloques, analizar y crear una versión de la misma utilizando otra perspectiva.
Esto lo realizo con una cámara conectada a un computador (Bidgoli, 2004).
El trabajo que aporta las bases conceptuales y teóricas sobre visión artificial es publicado
en 1982 por David Marr (Marr D. , 1982), este trabajo presenta por primera vez una
metodología completa para el análisis de imágenes a través de un computador. A partir de
este trabajo de Marr, la visión artificial se establece como como una línea principal de
investigación en muchas universidades. Por ello se considera que la década de los ochenta,
marca un hito en el desarrollo de la Visión Artificial por computadora.

20
1.6. METODOLOGÍA DE LA INVESTIGACIÓN
Ian Sommerville (Sommerville, Ingenieria del Software, 2006), define modelo de proceso
de software, como "Una representación simplificada de un proceso de software,
representada desde una perspectiva específica. Por su naturaleza los modelos son
simplificados, por lo tanto; un modelo de procesos de software es una abstracción de un
proceso real."
El modelo de desarrollo elegido para el presente trabajo es un modelo incremental, en este
modelo las actividades del proceso de desarrollo de software se llevan a cabo en secuencias
lineales, en forma escalonada a medida que avanza el calendario de actividades. Este
modelo es muy útil cuando los requerimientos iniciales del software están bien definidos,
pero se desea tener de forma temprana una versión con funcionalidad limitada del software
y aumentarla en incrementos posteriores (Pressman, 2005).
El primer incremento de este modelo de desarrollo, generalmente es el producto
fundamental, en el cual se abordan los requerimientos básicos, y se dejan para próximos
incrementos las características suplementarias. Este modelo fue propuesto por Harlan D.
Mills en 1980 (Basili, DeMarco, & Mili, 1999), y surge con la necesidad de poder probar el
software de forma temprana y poder tomar mejor experiencia en los requerimientos a
medida que se adquiría experiencia en el sistema.
Imagen 4. Modelo de desarrollo iterativo-incremental. (Sommerville, Ingenieria del Software, 2006)
Para el desarrollo de cada uno de los incrementos, se puede utilizar un modelo clásico en
cascada, si los requerimientos a desarrollar como parte del incremento son lo
suficientemente claros y se pueden considerar estables. El modelo en cascada es el modelo
No se puede mostrar la imagen. Puede que su equipo no tenga suficiente memoria para abrir la imagen o que ésta esté dañada. Reinicie el equipo y, a continuación, abra el archivo de nuevo. Si sigue apareciendo la x roja, puede que tenga que borrar la imagen e insertarla de nuevo.

21
de desarrollo de mayor uso en la industria del software, en este modelo cada fase debe
seguirse en orden y debe terminar para poder continuar con la siguiente.
En el modelo en Cascada las actividades fundamentales, según define Pressman (Pressman,
2005), son:
• Definición de los requisitos: Los servicios, restricciones y objetivos son
establecidos con los usuarios del sistema. Se busca hacer esta definición en detalle.
• Diseño de software: Se divide el sistema en sistemas de software o hardware. Se
establece la arquitectura total del sistema. Se identifican y describen las
abstracciones y relaciones de los componentes del sistema.
• Implementación y pruebas unitarias: Construcción de los módulos y unidades de
software. Se realizan pruebas de cada unidad.
• Integración y pruebas del sistema: Se integran todas las unidades. Se prueban en
conjunto. Se entrega el conjunto probado al cliente.
• Operación y mantenimiento: Generalmente es la fase más larga. El sistema es
puesto en marcha y se realiza la corrección de errores descubiertos. Se realizan
mejoras de implementación. Se identifican nuevos requisitos.
En este modelo una fase no puede iniciar, si la fase anterior no se ha terminado, esto es un
principio del modelo y debe ser respetado, ya que la salida de cada fase alimenta a la fase
siguiente.
Imagen 5. Fases del desarrollo en cascada. (Pressman, 2005)
No se puede mostrar la imagen. Puede que su equipo no tenga suficiente memoria para abrir la imagen o que ésta esté dañada. Reinicie el equipo y, a continuación, abra el archivo de nuevo. Si sigue apareciendo la x roja, puede que tenga que borrar la imagen e insertarla de nuevo.

22
1.7. ESTUDIO DE SISTEMAS PREVIOS
El MIT junto con la Universidad de Stanford se perfilan como los centros más
sobresalientes en los estudios de visión artificial, dentro de sus trabajos más relevantes se
pueden mencionar la visión aplicada a robótica bajo el proyecto Hand-Eye (Estados Unidos
Patente nº 7151853, 2005) y el llamado proyecto UIS (Nakano & Yasuaki, 1988), este
último proyecto marca el comienzo del uso de estas técnicas en aplicaciones de tipo militar.
Por otra parte, países como Japón desarrollaron el llamado proyecto PIPS (Pattern-
Information Processing System) (Nishino, 1978), el cual impulsó el desarrollo del análisis
de imágenes (Ken-ichi, Masatsugu, & Hidenori, 1978).
Los siguientes trabajos presenta aplicaciones de las técnicas de visión y reconocimiento
artificial, estos trabajos ya se están probando y utilizando en ambientes reales y los
mencionamos debido a su gran contribución en la visión artificial.
1.7.1. CARE-O-BOT
En 1999 en la universidad de Stuttgart Alemania, los médicos Schaeffer y May (Schraft,
Schaeffer, & May, 1998), desarrollaron el sistema Care-O-bot™, este sistema intenta
contribuir a las soluciones tecnológicas necesarias una plataforma de demostración de un
sistema móvil de atención en el hogar.
El Care-O-bot™ es un robot de servicio móvil que tiene la capacidad de realizar diversas
tareas de apoyo en el hogar, como llevar y traer objetos. El énfasis principal está puesto en
la integración de las tareas de comunicación y sociales, como llamadas automáticas de
emergencia y comunicación interactiva.
1.7.2. PHOTOFACE
En el 2011 durante la conferencia Information Forensics and Security de la IEEE, se
presenta la base de datos PhotoFace (Zafeiriou, 2013), en este trabajo se presenta una base
de datos adecuado para el reconocimiento facial 2D y 3D, basado en estéreo fotométrico.
La base de datos PhotoFace se creó mediante una medida de cuatro dispositivos estéreo
fotométricos, estos pueden ser fácilmente utilizados en entornos comerciales. A diferencia

23
de otras bases de datos a disposición del público el nivel de cooperación entre los sujetos y
el mecanismo de captura fue mínimo. El dispositivo propuesto también se puede usar, para
capturar en 3D caras expresivas.
1.7.3. LUNABOT
Un grupo de estudiantes de la Universidad Pedagógica Nacional participaron en la
competencia NASA's Third Annual Lunabotics Mining Competition, en el que participaron
un total de 70 equipos de universidades de diferentes países a nivel mundial. El desafío de
los estudiantes era diseñar y construir un robot excavador, llamado Lunabot, que pudiera
extraer y depositar un mínimo de 10 kilógramos de un compuesto similar a la arena lunar,
en 10 minutos en un lugar cerrado, desplazándose de un punto a otro (Ministerio de
Educación Nacional, 2013).
Como podemos darnos cuenta los trabajos sobre Visión Artificial no son solo interés de
instituciones o universidades extranjeras, en Colombia también existen trabajos interesantes
sobre este tema y que han generado aportes importantes de aplicación en diferentes campos
de la industria y la ciencia.
1.8. ORGANIZACIÓN DEL TRABAJO DE GRADO
El presente documento se ha organizado en tres partes cada una a su vez, organizada en
capítulos.
• En la primera parte se realiza la descripción del problema de investigación y los
objetivos, que motivaron el desarrollo del proyecto.
• En la segunda parte se desarrollan los conceptos relacionados con la detección y el
reconocimiento de rostros en imágenes.
• En la tercera parte se presentan los resultados obtenidos del proyecto y los trabajos
futuros que se pueden desarrollar.

24
PARTE 2. DESARROLLO DE LA INVESTIGACIÓN
CAPÍTULO 2. RECONOCIMIENTO BIOMETRICO
2.1. BIOMETRÍA
La Biometría es la ciencia que busca establecer la identidad de un Individuo basado en
atributos físicos o de comportamiento (Jain, Bolle, & Pankanti, Biometrics: personal
identification in networked society, 2006). El concepto de biometría proviene de la palabra
bio (vida) y metría (medida), por lo tanto, un equipo biométrico mide e identifica alguna
característica propia de una persona.
El objetivo de los sistemas biométricos es la identificación, entendida como el
reconocimiento de una persona; o la autenticación, verificación de un individuo en una base
de datos de características. En los sistemas biométricos es muy importante definir su
objetivo, ya que algunas características son mejores para aplicaciones donde se busque
identificar y otras características funcionan mejor si el objetivo es autenticar (Pankanti,
Bolle, & Jain, 2002).
Las características anatómicas suelen permanecen estables al paso del tiempo, por ejemplo,
la huella dactilar; por el contrario, las características de comportamiento, pueden variar con
los años o con el estado anímico de la persona. Por ejemplo, la firma es considerada una
característica de comportamiento, que puede variar con el paso del tiempo.
No cualquier característica anatómica puede ser utilizada con éxito por un sistema
biométrico. Para que una característica pueda ser considerada como válida para un sistema
biométrico se debe considerar los siguientes aspectos (Jain, Flynn, & Ross, Handbook of
biometric, 2007):
• Universalidad: Que cualquier persona del mundo posea esta característica.
• Unicidad: Que la probabilidad que dos personas tengan esta característica idéntica
sea muy pequeña.
• Permanencia: Que la característica perdure en el tiempo.

25
• Cuantificación: Que la característica pueda ser medida de forma cuantitativa.
• Rendimiento: Que tan preciso, veloz y robusto es el proceso de identificación
• Aceptabilidad – Que tanta aprobación tiene por parte de las personas
• Fiabilidad - ¿Qué tan fácil engañar al sistema mediante técnicas fraudulentas?
La Biometría hace posible que una característica física de nuestro cuerpo pueda ser
utilizada como identificación y clave de acceso. Actualmente los sistemas Biométricos
tienen un futuro muy prometedor en lo relacionado a la autenticación digital, y se están
realizando muchos estudios para llevarla a sectores específicos como los pagos bancarios.
2.2. BIOMETRÍA POR RASGOS FACIALES
La biometría busca desarrollar sistemas de seguridad y de autenticación confiables y
rápidos, basados en la identificación de las características propias de la persona, con lo cual
se logra que la suplantación sea prácticamente imposible (Woodward Jr, Horn, Gatune, &
Thomas, 2003). La técnica de reconocimiento basadas en los rasgos del rostro es conocida
como biometría facial, y se basa en las diferencias que existen entre el rostro de una
persona, con respecto a las demás.
El reconocimiento facial se utiliza principalmente para el control y seguridad, en este
campo se cuenta con dos categorías (Xiao, 2007):
• Verificación biométrica: consiste en usar una determinada tecnología para asegurar
que el individuo que debemos reconocer es quien dice ser.
• Identificación biométrica: en este caso no queremos confirmar que un usuario es
quien asegura ser, sino que tratamos de aplicar la tecnología para conocer la
identidad de un individuo.
Un sistema de biometría facial consta de tres componentes fundamentales:
• Cámara: Se encarga de registrar la imagen

26
• Software de Detección de rostros: Se encarga de verificar si en la imagen está
presente un rostro.
• Software de reconocimiento: Se encarga de diferenciar los rostros que se encuentran
en la imagen, para diferenciar entre las personas presentes.
El reconocimiento facial tiene su principal complicación relacionada con la luz, ya que
dependiendo de la iluminación puede cambiar el color del rostro y generar sombras que
pueden afectar la detección y el reconocimiento. Otro factor es el envejecimiento, ya que
con el paso del tiempo las facciones del rostro cambian, y el contorno de los ojos cambia
debido a las arrugas.
Este campo a tenido gran desarrollo en los últimos veinte años, y sigue evolucionando,
financiado principalmente por la industria militar, los bancos y la de seguridad.
CAPÍTULO 3. DETECCIÓN Y RECONOCIMIENTO DE ROSTROS
3.1. ALGORITMO DE VIOLA-JONES
El método de reconocimiento de objetos en imágenes digitales conocido como Viola-Jones,
fue propuesto por los investigadores Paul Viola y Michael Jones en el año 2001 (Viola &
Jones, Rapid object detection using a boosted cascade of simple features, 2001). Es uno de
los primeros métodos que logra detectar eficazmente objetos en tiempo real en una imagen.
Este método originalmente fue desarrollado para realizar la detección de rostros, pero
puede ser usado para detectar cualquier objeto dentro de una imagen. Actualmente es uno
de los métodos más utilizados en la industria, por su velocidad y su alto porcentaje de
acierto.
Viola-Jones utiliza clasificadores de características para lograr el reconocimiento de los
objetos. Basándose en estas características Haar (Papageorgiou, Oren, & Poggio, 1998), se
logra obtener un detector de objetos robusto (Viola & Jones, Rapid object detection using a

27
boosted cascade of simple features, 2001). También se denominan estos clasificadores
mediante el nombre de cascada, ya que el resultado del clasificador es el fruto de varios
clasificadores más simples utilizados en conjunto. Una porción de la imagen donde se
presume está el objeto buscado, debe superar todas las etapas del clasificador en cascada
para ser aceptado.
El método de Viola-Jones, se divide en tres etapas. En la primera se realiza una
transformación de la imagen generando una nueva llamada imagen integral, en la segunda
etapa se realiza la extracción de características usando filtros con base Haar (Viola & Jones,
Robust real-time face detection, 2004), y por último se usa Boosting (Mayhua-Lopez,
Gómez-Verdejo, & Figueiras-Vidal, 2012) para la construcción de clasificadores en
cascada.
Etapas de procesamiento de Viola-Jones
Este algoritmo realiza tres etapas para realizar la detección de un rostro, cada una de las
etapas se describe a continuación:
Imagen 6. Etapas del método para detección de rostros de Viola-Jones. Fuente: Realización propia.

28
a) Imagen Integral
La suma de todos los pixeles de un rectángulo, puede ser calculada empleando una
representación intermedia llamada imagen integral. Esta imagen intermedia permite extraer
de forma rápida características a diferentes escalas. Los autores definen la imagen integral
como aquella en la cual cada punto contiene el resultado de la suma de los valores de todos
los puntos situados por encima y a su izquierda en la imagen original.
Imagen 7. Calculo de la imagen integral de Viola-Jones. (OpenCv O. , 2017)
La imagen integral es utilizada por el algoritmo como una forma rápida de calcular la suma
de los valores del rectángulo de una característica de tipo Haar (Papageorgiou, Oren, &
Poggio, 1998). Esta imagen integral es la suma de los pixeles del rectángulo desde la
esquina superior izquierda hasta un punto elegido dentro de la imagen. Para el cálculo de la
imagen integral, la imagen original debe estar en escala de grises.
b) Extracción de características
En imágenes las características de cada objeto se extraen al aplicar ciertas funciones que
permitan la representación y descripción de los objetos de interés de la imagen (patrones).

29
Imagen 8. Filtros Haar rotados, trasladados y con cambios de escala. (OpenCv O. , 2017)
La extracción de características es un paso en el reconocimiento de patrones en el cuál las
medidas u observaciones son procesadas para encontrar a tributos que puedan ser usados
para asignar los objetos a determinada clase. En la metodología de Viola-Jones, la
extracción de características es realizada aplicando a la imagen filtros con bases Haar
(Viola & Jones, Rapid object detection using a boosted cascade of simple features, 2001).
Imagen 9. Detección de rostros utilizando características Haar en cascada. (OpenCv O. , 2017)

30
c) Clasificación
Esta etapa se encarga de seleccionar un conjunto de características de tipo Haar
(Papageorgiou, Oren, & Poggio, 1998) y aplicarlos dentro de la imagen que se está
analizando. Para llevar a cabo la clasificación es necesarios realizar un proceso de
entrenamiento para crear un clasificador en cascada. Este proceso se realiza mediante el
algoritmo de AdaBoots (Sirovich & Kirby, 1987). La aplicación de clasificadores en
cascada ha permitido obtener muy buenos resultados y es uno de los grandes aportes de este
algoritmo.
La utilización de un clasificador en cascada y la introducción del algoritmo de aprendizaje
AdaBoots, además del gran aporte conceptual, son los motivos principales para que el
método de Viola-Jones sea considerado como uno de los métodos más importantes
desarrollados en este campo. La idea de Paul Viola y Michael Jones de utilizar
clasificadores débiles para formar clasificadores fuertes, denominados clasificadores en
cascada, ha sido utilizado por otros investigadores para el reconocimiento de objetos en
visión por computador.
3.2. EIGENFACES
Los sistemas de reconocimiento de rostros se basan en la idea de que cada persona tiene
una estructura de rostro particular y, utilizando la simetría facial, es posible la comparación
computarizada de las imágenes del rostro. El rostro y sus propiedades estructurales deben
ser identificadas cuidadosamente, y la imagen resultante debe convertirse en datos digitales
bidimensionales.
El enfoque de Eigenface (Sirovich & Kirby, 1987) es considerado por muchos como la
primera tecnología de reconocimiento facial de alto desempeño, y sirvió como base para
uno de los principales productos comerciales de tecnología de reconocimiento facial en
biometría (Heseltine, Pears, & Austin, 2002). Desde su desarrollo inicial y publicación, ha
habido muchas extensiones al método original y muchos nuevos desarrollos en sistemas
automáticos de reconocimiento facial.

31
La idea de utilizar los componentes principales para representar los rostros humanos fue
desarrollada por Sirovich y Kirby (Sirovich & Kirby, 1987) y utilizada por Turk y Pentland
(Turk & Pentland, Eigenfaces for recognition, 1991) para la detección y reconocimiento de
rostros. La motivación de las Eigenfaces es doble:
• Extraer la información facial pertinente, que puede o no estar directamente
relacionada con la intuición humana de rasgos faciales como los ojos, la nariz y los
labios. Una manera de hacerlo es capturar la variación estadística entre las imágenes
de un mismo rostro.
• Representar imágenes de rostros eficientemente. Para reducir el cómputo y la
complejidad del espacio, cada imagen de un rostro se puede representar usando un
pequeño número de parámetros.
Los Eigenfaces pueden ser considerados como un conjunto de características que
representan la variación global entre las imágenes de un rostro. Cada Eigenface representa
un rasgo característico de las imágenes faciales siguiendo un patrón obtenido del estudio de
muchos rostros.
El funcionamiento de este método es el siguiente:
• Por cada imagen del set de entrenamiento (imágenes de prueba) se concatenan sus
filas de pixeles, transformándola en un vector en el que cada valor se corresponde
con el valor del pixel correspondiente.
• Tras esto, se obtiene una matriz de vectores, siendo cada vector una imagen.
• A este vector se le aplica el método PCA (Principal Component Analysis) (Peason,
1901), para obtener los componentes principales y reducir la dimensionalidad.
A partir de estos Eigenfaces, cada imagen del set de entrenamiento se puede reconstruir de
una forma muy aproximada. Se calcula la distancia entre el vector de valores de la imagen
de entrada con el resto de las imágenes del set de entrenamiento, y se selecciona la que
produce la distancia mínima. Si dicha distancia se encuentra dentro de un umbral

32
establecido, se selecciona como valor aceptado. Si no está dentro del umbral, se considerará
un rostro desconocido.
Este método es muy aceptado debido a su fácil implementación y a que, bajo unas buenas
condiciones, tiene un buen porcentaje de aciertos. Por el contrario, un inconveniente de este
enfoque es que no solo se maximiza la dispersión entre imágenes producida en mayor parte
por las condiciones de iluminación y por la expresión facial, lo cual dificulta la
clasificación.
CAPÍTULO 4. DESARROLLO DE LA APLICACIÓN
En este capítulo se realizará la descripción de los componentes utilizados para el desarrollo
de la aplicación para el reconocimiento de rostros. Se describe como mediante una librería
de Visión Artificial como OpenCv y un lenguaje orientado a objetos como c#, es posible
realizar el desarrollo de la aplicación, logrando muy buenos resultados.
También se describe la metodología de desarrollo utilizada, y los diferentes artefactos
generados como parte del proceso de diseño y desarrollo.
4.1. OPENCV
Para el desarrollo de la aplicación utilizaremos el módulo de “Object Detection” del Core
de la librería OpenCV. Este detector de objetos utiliza los conceptos propuesto por Paul
Viola. (Viola & Jones, Rapid object detection using a boosted cascade of simple features,
2001)
La librería OpenCV (Open Source Computer Vision) es biblioteca de visión artificial
iniciada por Intel en 1999 (OpenCv, 2017). Esta biblioteca multiplataforma se centra en el
procesamiento de imágenes en tiempo real e incluye implementaciones libres de patentes de
los últimos algoritmos de visión computarizada.

33
Esta librería está escrita en C y C++ y cuenta con aproximadamente quinientas funciones
que abarcan diferentes procesos de la visión artificial. OpenCV fue diseñado para la
eficiencia computacional y con un fuerte enfoque en aplicaciones en tiempo real. La librería
permite el manejo eficiente de imágenes y matrices, reconocimiento de objetos y análisis de
imágenes utilizando la técnica de Eigenfaces y el algoritmo AdaBoost (OpenCv O. , 2017).
OpenCv se encuentra actualmente en su versión 3.2.0, liberada el 23 de diciembre de 2016,
en esta versión se cuenta con la clase de FaceRecognizer para el reconocimiento facial, Los
algoritmos actualmente disponibles son:
• Eigenfaces
• Fisherfaces
• Local Binary Patterns Histograms
OpenCv nos permite detectar un rostro mediante el uso de clasificadores en cascada, y
realizar el reconocimiento de un rostro especifico utilizando Eigenfaces. Por lo anterior se
eligió esta librería para el desarrollo de la aplicación para el reconocimiento de una
persona, la cual es el producto final esperado del presente trabajo.
El módulo de reconocimiento de objetos de OpenCv nos provee las siguientes clases:
Clases
class cv::BaseCascadeClassifier
class cv::CascadeClassifier
Cascade classifier class for object detection.
struct cv::DetectionROI
struct for detection region of interest (ROI)

34
struct cv::HOGDescriptor
class cv::SimilarRects
Tabla 1. Lista de Clases del módulo de reconocimiento de objetos de OpenCv. (OpenCv O. , 2017)
Para el reconocimiento especifico de rostros OpenCv suministra las clases y métodos:
Clases
class cv::face::BasicFaceRecognizer
class cv::face::FaceRecognizer
Abstract base class for all face recognition models. More...
class cv::face::LBPHFaceRecognizer
class cv::face::PredictCollector
Abstract base class for all strategies of prediction result handling. More...
class cv::face::StandardCollector
Default predict collector. More...
Metodos
Ptr< BasicFaceRecognizer > cv::face::createEigenFaceRecognizer (int
num_components=0, double threshold=DBL_MAX)
Ptr< BasicFaceRecognizer > cv::face::createFisherFaceRecognizer (int
num_components=0, double threshold=DBL_MAX)
Ptr< LBPHFaceRecognizer > cv::face::createLBPHFaceRecognizer (int radius=1, int
neighbors=8, int grid_x=8, int grid_y=8,
double threshold=DBL_MAX)

35
Tabla 2. Clases y métodos del Módulo de reconocimiento facial de OpenCV. (OpenCv, 2017)
4.1. EMGUCV
Emgu CV es un contenedor para la plataforma .Net de la biblioteca de procesamiento de
imágenes de OpenCV (EmguCV, 2017). Permitir que las funciones de OpenCV sean
llamadas desde los lenguajes compatibles con .NET, tales como C #, VB, VC ++ etc. El
contenedor puede ser compilado por Visual Studio, Xamarin Studio y Unity, puede
ejecutarse en Windows, Linux, Mac OS X, iOS, Android y Windows para teléfonos
móviles.
EmguCV permite usar OpenCV en la plataforma .net con lenguajes como C #. El algoritmo
de Viola-Jones hace parte de EmguCV. Al usar este algoritmo, estaríamos haciendo uso de
un detector de rostros que ha sido entrenado con miles y miles de rostros humanos. Los
datos de entrenamiento generados a partir de los rostros se almacenan en archivos Xml que
vienen por defecto con el paquete EmguCV que se almacenan en [EnguCV Root Folder] \
opencv \ data \ haarcascades.
4.2. IMPLEMENTACIÓN DEL MODELO DE DESARROLLO
Para el desarrollo de la aplicación para el reconocimiento de rostros se eligió el modelo
Incremental. Esta elección se basó en el hecho de que los requerimientos de la aplicación
son los suficientemente estables, ya que estos fueron definidos con anticipación y formaron
parte del anteproyecto presentado como parte de la investigación, y de esta forma poder
realizar el desarrollo en iteraciones; al final de cada iteración se cuenta con una versión de
la aplicación que cuenta con funcionalidad lista para ser probada.
El modelo Incremental permite tener de forma temprana un prototipo de la aplicación, en la
cual se implemente la funcionalidad relacionada a la detección de rostros. Un segundo
incremento con la funcionalidad relacionada con el entrenamiento y el reconocimiento de
una persona. Un tercer incremento estará relacionado a la parte de usabilidad e interface de
usuario.

36
Con este modelo es posible probar cada módulo de la aplicación, detectar las fallas
corregirlas y seguir con el siguiente modulo, sin necesidad de esperar a tener toda la
funcionalidad implementada para iniciar con las pruebas. Esto permite una
retroalimentación temprana y la posibilidad de realizar ajustes específicos, sin tener que
realizar cambios a todo el desarrollo realizado.
A continuación, se detalla el proceso que se realizara para cada uno de los incrementos:
PRIMER INCREMENTO
• Definición de los requisitos: Se desarrollan los requerimientos relacionados con la
detección de un rostro en una imagen.
• Diseño de software: Se diseñan los casos de uso.
• Implementación y pruebas unitarias: Se realiza el desarrollo y las pruebas.
SEGUNDO INCREMENTO
• Definición de los requisitos: Se desarrollan los requerimientos relacionados con el
reconocimiento del rostro de una persona.
• Diseño de software: Se diseñan los casos de uso. Se diseña la arquitectura del
sistema.
• Implementación y pruebas unitarias: Se realiza el desarrollo y las pruebas.
• Integración y pruebas del sistema: Se realizan las pruebas de integración del
sistema, realizando pruebas de detección y reconocimiento de un rostro
TERCER INCREMENTO
• Integración y pruebas del sistema: Se realizan casos de prueba para el sistema. Estos
casos de prueba estarán relacionados con el entrenamiento y el reconocimiento de
un rostro.
• Operación y mantenimiento: Se realiza la operación de la aplicación en un ambiente
controlado.

37
El resultado final será la aplicación funcionando, los casos de uso, los diagramas de
arquitectura del sistema y la aplicación desarrollada con el lenguaje C#.
4.3. DEFINICIÓN DE LOS REQUISITOS
4.3.1. ALCANCE
Desarrollar un sistema de visión artificial, utilizando la librería de Visión Artificial
OpenCV, que pueda ser entrenado para reconocer el rostro de una persona en una imagen
de video. El entrenamiento se realizará utilizando fotografías del rostro de la persona
tomadas de forma frontal.
La aplicación realizará el proceso de reconocimiento facial, utilizando una cámara web
conectada al sistema. Cuando la persona, con la cual se realizó el entrenamiento, este
dentro del espacio capturado por la cámara, el sistema la reconocerá e indicará en la
pantalla la ubicación de la persona dentro de la imagen y el nombre de la persona.
4.3.2. LIMITACIONES
• El sistema solo reconocerá una persona dentro de la imagen
• Para el entrenamiento y reconocimiento del rostro de la persona, esta no debe llevar
accesorios como lentes, sombreros u otro tipo de elementos que interfieran en el
reconocimiento.
• El clasificador para el reconocimiento de la persona, requiere de fotografías con
ciertos parámetros de iluminación y fondo.
• El sistema solo mostrara en pantalla el nombre de la persona cuando la reconozca
dentro de la imagen.
4.3.3. RESULTADOS ESPERADOS
El sistema de visión artificial desarrollado, será capaz de analizar un flujo de video que
recibe de una cámara web, y por medio de los algoritmos para reconocimiento de rostros,
proporcionados por la librería OpenCV, localiza el rostro en la imagen y lo resalta mediante
un rectángulo.
38
El sistema reconocerá el rostro de una persona en particular, para lo cual se debe realizar
con anterioridad el entrenamiento utilizando imágenes del rostro de la persona tomadas de
forma frontal. Cuando el sistema reconozca la persona dentro de la imagen, se indicara en
pantalla encerrando el rostro de la persona en un rectángulo e imprimiendo su nombre.
4.4. DISEÑO DE SOFTWARE
Los requerimientos para la aplicación de visión artificial están relacionados con la
interacción del usuario con el sistema y con los diferentes subsistemas que lo componen, ya
que este depende de la información de otros procesos automáticos que están en continua
ejecución.
4.4.1. REQUERIMIENTOS
Requerimientos funcionales:
Numero Tipo Descripción
RF1 Funcional El sistema debe poder reconocer un objetivo dentro de su
campo visual, para ello debe estar analizando continuamente
el flujo de video recibido por una cámara.
RF2 Funcional El objetivo que deberá reconocer el sistema será único, el
sistema no reconocerá varios objetos de diferentes tipos, para
este trabajo se decidió que el objetivo sería una persona que
esté dentro del campo de visión del sistema.
RF3 Funcional El sistema debe ser capaz de detectar un rostro cuando este
dentro de su campo de visión.
RF4 Funcional Cuando el sistema detecte un rostro este debe indicarlo en
pantalla dibujando una señal que indique que se reconoció el
objetivo.
RF5 Funcional Cuando el sistema haya reconocido el objetivo debe indicar el
nombre de la persona que concuerda con el rostro detectado.

39
Requerimientos no funcionales:
Numero Tipo Descripción
RNF1 No funcional Se necesita un sistema de entrenamiento para definir el
objeto a buscar.
RNF2 No funcional Se necesita un sistema portable con la capacidad de
capturar video y enviar la información al PC para su
procesamiento.
RNF3 No funcional El sistema debe desarrollarse con software libre
4.4.2. DISEÑO DE CASOS DE USO
Identificador caso de uso:
CU–01
Nombre:
Reconocimiento de objetivo
Propósito
El sistema debe poder reconocer un objetivo dentro de su campo visual, para ello debe estar
analizando continuamente el flujo de video recibido por una cámara.
Identificador caso de uso:
CU–02
Nombre:
Reconocer objetivo en campo visual
Propósito

40
Requerimiento funcional 2: El objetivo que deberá reconocer el sistema será único, el
sistema no reconocerá varios objetos de diferentes tipos, para este trabajo se decidió que el
objetivo sería una persona que esté dentro del campo de visión del sistema.
Requerimiento funcional 4: El sistema debe ser capaz de detectar un rostro cuando este
dentro de su campo de visión.
IDENTIFICADOR CASO DE USO:
CU–04
NOMBRE:
Indicar en pantalla que se encontró el objetivo
PROPÓSITO
Cuando el sistema detecte un rostro este debe indicarlo en pantalla dibujando una señal que
indique que se reconoció el objetivo.

41
4.4.3. ARQUITECTURA
Para la diseñar los modelos de la arquitectura de la aplicación, se utilizó la especificación
Archimate 2.0 y Architecture Development Method (AMD) (Group, 2012), con la cual se
generaron las tres capas de la Arquitectura: Negocio, Aplicación e Infraestructura. Para la
elaboración de los diagramas de utilizó el software ArchiTools.
4.4.3.1. Vista de Negocio
La Vista de arquitectura de negocio considera los aspectos funcionales del sistema, es decir,
lo que el nuevo sistema tiene la intención de hacer. Esto puede ser construido a partir de un
análisis del entorno existente y de los requisitos y limitaciones que afectan al nuevo sistema
(Blevins, Spencer, Tower, & Waskiewi, 2004).
La aplicación para detección de rostros, debe realizar el proceso de identificación de una
persona, la identificación busca responder la pregunta de: ¿quién es usted?, para ello se
debe comparar la imagen del rostro de la persona detectada en la imagen, con todos los
rostros de personas conocidas que tenga en su repositorio de datos para determinar su
identidad.

42
En la aplicación interactúan, el sistema y la persona que se desea identificar. A
continuación, se muestra el diagrama de negocio para la aplicación.
Imagen 10. Vista del Negocio. Realización Propia.
4.4.3.2. Vista de aplicación
La vista de aplicación es útil para diseñar o comprender la estructura principal de
aplicaciones o componentes y los datos asociados. La capa de aplicación comprende
aplicaciones de software que apoyan los componentes del negocio (Group, 2012).
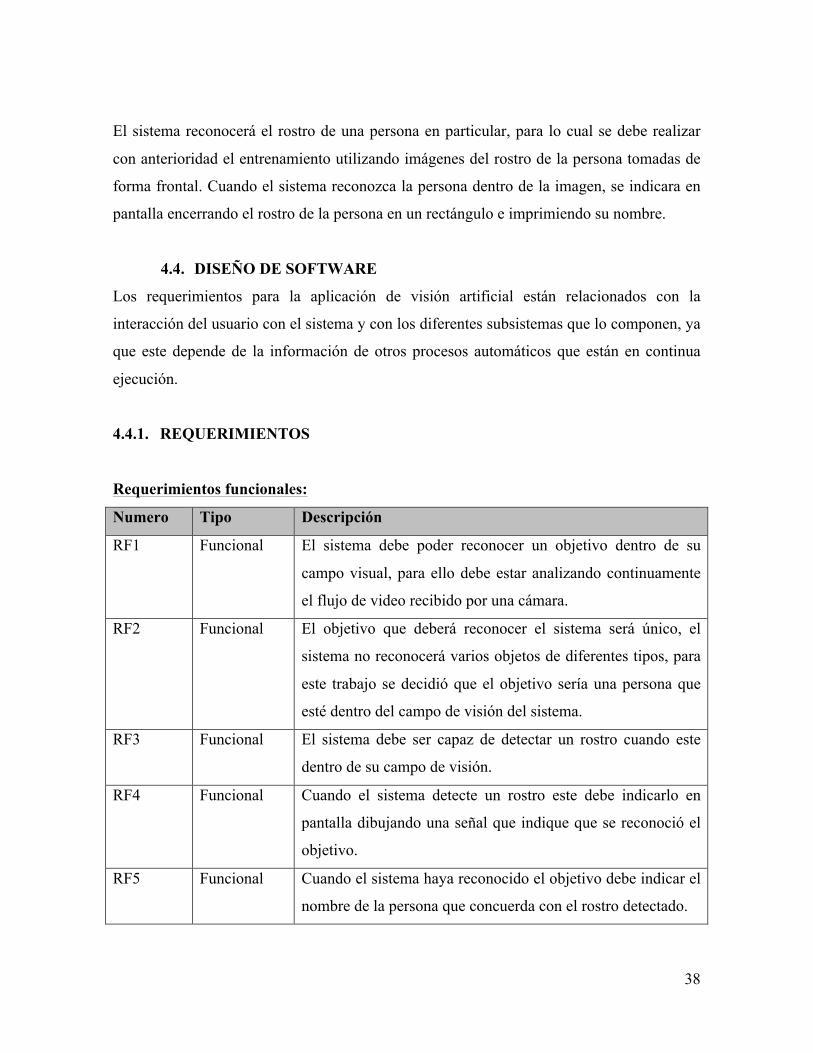
La capa de aplicación da soporte a la capa de negocio, en esta capa se manifiestan el
dominio de datos y los componentes de la aplicación (Lankhorst, Proper, & Jonkers,
2009). Para la aplicación de reconocimiento de rostros se identifican tres componentes
principales: Autenticación, Detección y Reconocimiento.
La librería OpenCV también es un componente, pero para este caso es un componente de
apoyo, ya que provee servicios a los otros componentes de la aplicación, pero no va a ser
desarrollado o modificado.
43
Como objeto de datos, se encuentran las imágenes del entrenamiento, las cuales se
encuentran alojadas en un directorio y su metadato está en un XML.
Imagen 11. Vista de Aplicación. Realización Propia.
4.4.3.3. Vista de Infraestructura
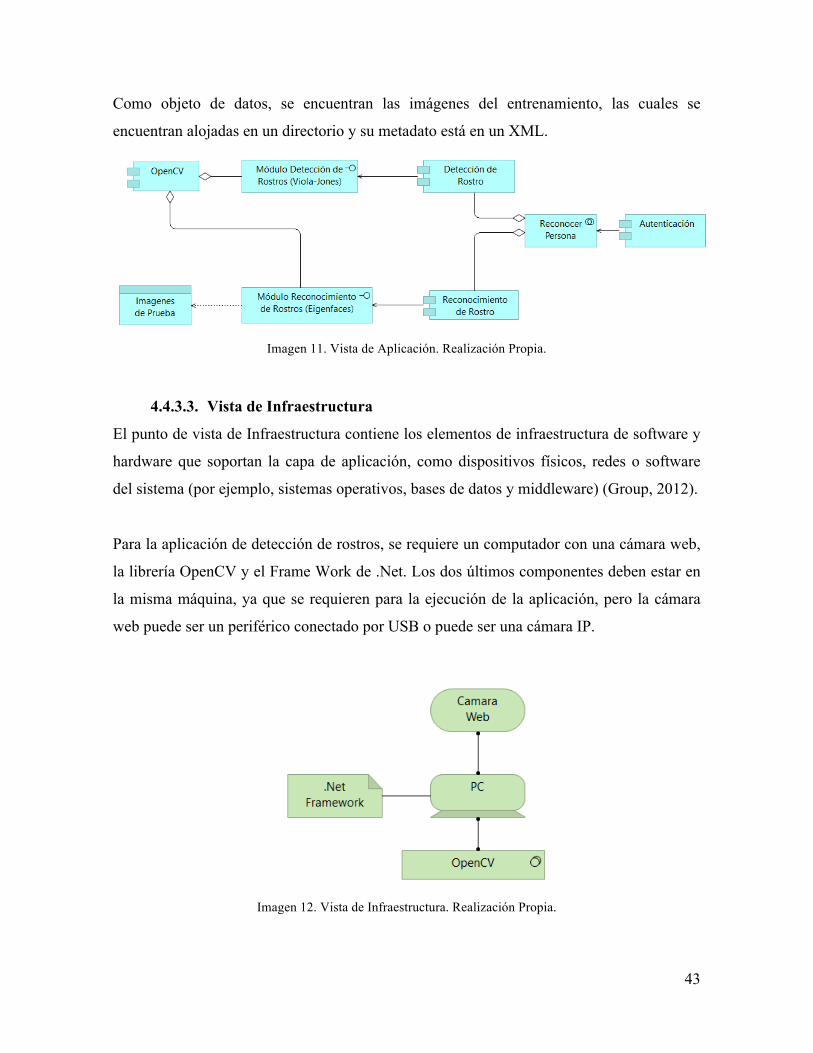
El punto de vista de Infraestructura contiene los elementos de infraestructura de software y
hardware que soportan la capa de aplicación, como dispositivos físicos, redes o software
del sistema (por ejemplo, sistemas operativos, bases de datos y middleware) (Group, 2012).
Para la aplicación de detección de rostros, se requiere un computador con una cámara web,
la librería OpenCV y el Frame Work de .Net. Los dos últimos componentes deben estar en
la misma máquina, ya que se requieren para la ejecución de la aplicación, pero la cámara
web puede ser un periférico conectado por USB o puede ser una cámara IP.
Imagen 12. Vista de Infraestructura. Realización Propia.
44
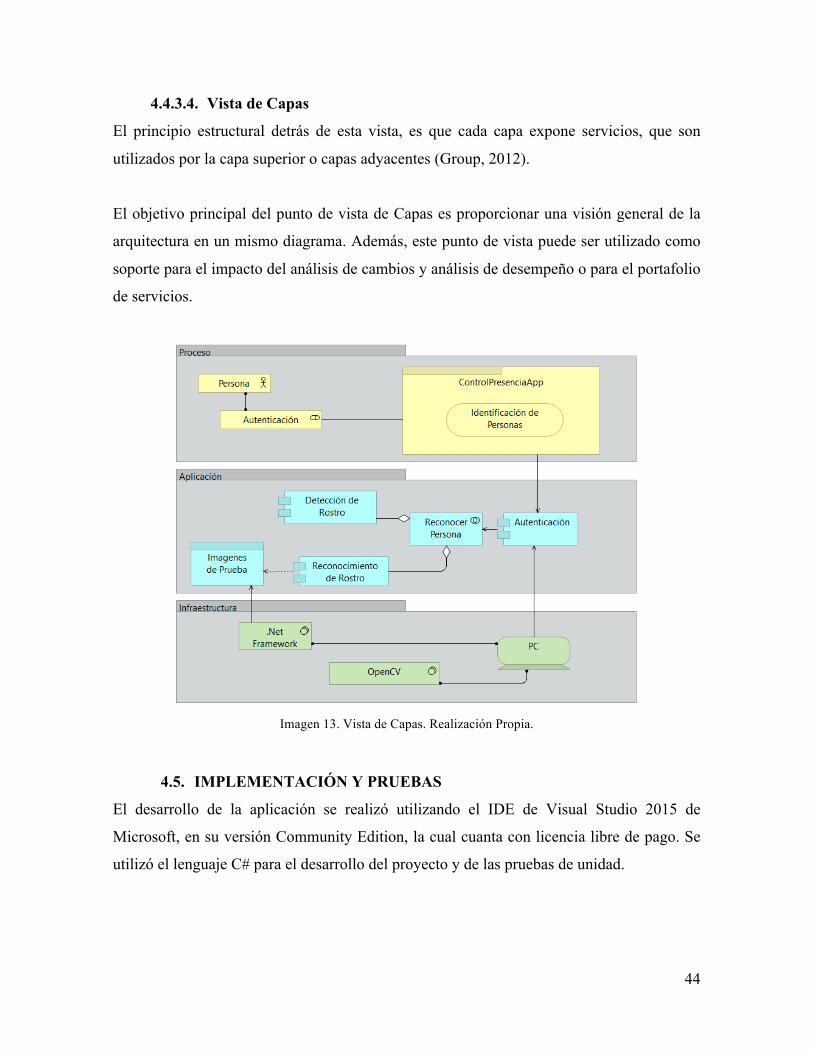
4.4.3.4. Vista de Capas
El principio estructural detrás de esta vista, es que cada capa expone servicios, que son
utilizados por la capa superior o capas adyacentes (Group, 2012).
El objetivo principal del punto de vista de Capas es proporcionar una visión general de la
arquitectura en un mismo diagrama. Además, este punto de vista puede ser utilizado como
soporte para el impacto del análisis de cambios y análisis de desempeño o para el portafolio
de servicios.
Imagen 13. Vista de Capas. Realización Propia.
4.5. IMPLEMENTACIÓN Y PRUEBAS
El desarrollo de la aplicación se realizó utilizando el IDE de Visual Studio 2015 de
Microsoft, en su versión Community Edition, la cual cuanta con licencia libre de pago. Se
utilizó el lenguaje C# para el desarrollo del proyecto y de las pruebas de unidad.

45
C# es un lenguaje orientado a objetos, basado en C++, por lo cual resulta muy fácil de
aprender. Este lenguaje permite la conexión con OpenCV, y con bases de datos no
relacionales.
La solución para el desarrollo de la aplicación cuenta con un proyecto de tipo Windows
Forms, en el cual se encuentra el desarrollo de los formularios y los eventos asociados a los
controles dentro de los formularios.
Imagen 14. Solución y proyecto Windows Forms en .Net. Realización Propia.
Las imágenes de prueba con las cuales se realiza el entrenamiento, se guardan en un
directorio dentro de la aplicación, esto con el fin de que se tengan los permisos suficientes
para crear y leer archivos.
Imagen 15. Formulario de la aplicación. Aplicación de Reconocimiento de Rostros. Realización Propia.

46
4.6. INTEGRACIÓN Y PRUEBAS DEL SISTEMA
Para realizar las pruebas de integración del sistema, se crearon escenarios de prueba, con
diferentes flujos y resultados esperados.
Prueba Resultado Esperado
Detectar el rostro de una persona, ubicada
de frente a la cámara
Se debe resaltar el rostro en un recuadro.
Detectar el rostro de una persona ubicada
sobre una margen de la cámara.
Se debe resaltar el rostro en un recuadro.
Detectar el rostro de una persona que tiene
gafas oscuras.
No se debe detectar un rostro.
Detectar el rostro de una persona con una
gorra
No se debe detectar un rostro.
Detectar un rostro que no exista en las
imágenes de prueba
Se debe resaltar el rostro en un recuadro. Se
debe etiquetar como desconocido.
Detectar un rostro que se encuentre en las
imágenes de pruebas
Se debe resaltar el rostro en un recuadro. Se
debe etiquetar con el nombre de la persona
a la que pertenece el rostro.
Detectar el rostro de dos personas Se debe resaltar el rostro en un recuadro. Se
debe etiquetar con el nombre de la persona
a la que pertenece el rostro.
4.7. OPERACIÓN Y MANTENIMIENTO
La aplicación para el reconocimiento de rostros, debe instalarse en un computador que
cuente con una cámara web integrada, o con una conectada como periférico. La aplicación
inicia la captura de video tomando la cámara web por defecto que se encuentre configurada.
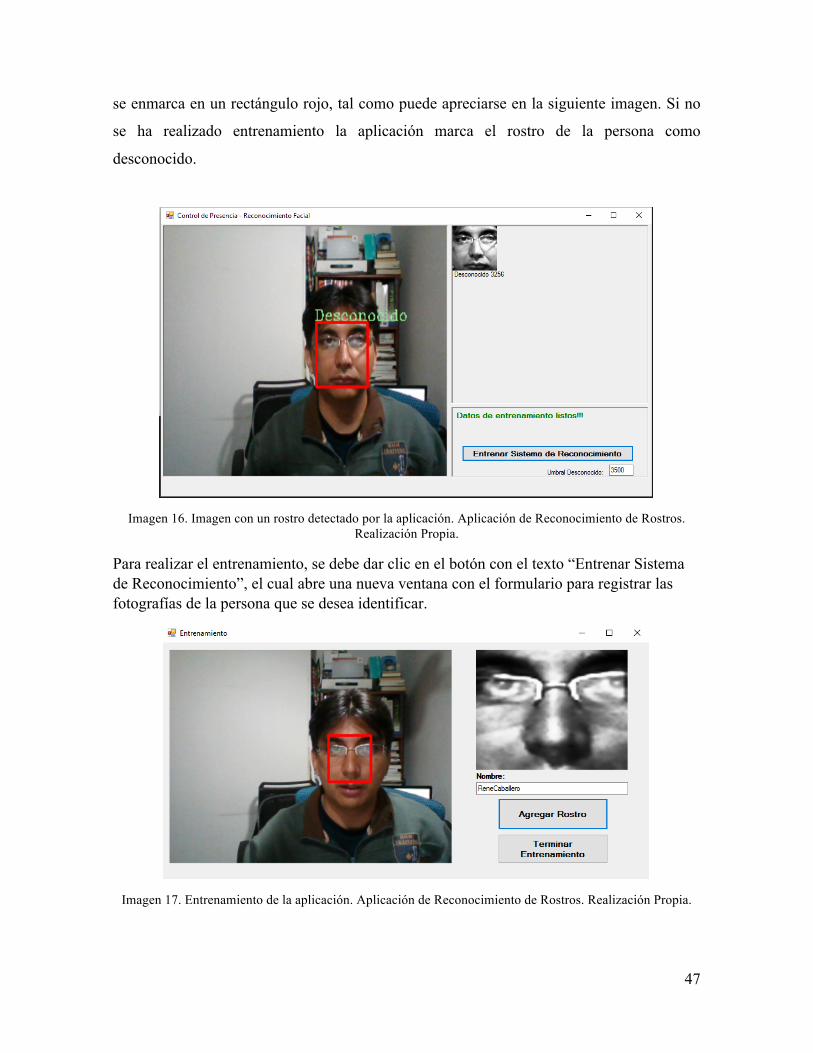
Cuando se inicia la aplicación y se inicia el reconocimiento de rostros, el sistema analiza
constantemente el flujo de video de la cámara en busca de rostros. Al detectar un rostro este
47
se enmarca en un rectángulo rojo, tal como puede apreciarse en la siguiente imagen. Si no
se ha realizado entrenamiento la aplicación marca el rostro de la persona como
desconocido.
Imagen 16. Imagen con un rostro detectado por la aplicación. Aplicación de Reconocimiento de Rostros.
Realización Propia.
Para realizar el entrenamiento, se debe dar clic en el botón con el texto “Entrenar Sistema de Reconocimiento”, el cual abre una nueva ventana con el formulario para registrar las fotografías de la persona que se desea identificar.
Imagen 17. Entrenamiento de la aplicación. Aplicación de Reconocimiento de Rostros. Realización Propia.

48
Las imágenes se guardan en un directorio local, la aplicación guarda cada imagen con el nombre de la persona a la cual pertenece, de esta forma cuando se realiza el proceso de reconocimiento se toma el nombre de la fotografía y se imprime en pantalla.
Imagen 18. Imágenes de entrenamiento. Aplicación de Reconocimiento de Rostros. Realización Propia.
Cuando el rostro detectado, coincide con el de una de las personas que se han registrado en
la aplicación, el sistema muestra el nombre de la persona en la parte superior del recuadro
rojo. En la siguiente imagen puede observarse que la aplicación logro reconocer el rostro
correspondiente a las imágenes de prueba.
Imagen 19. Imagen donde se indica el nombre de la persona. Realización Propia.

49
En la parte derecha del formulario se muestran las imágenes con las cuales se está
realizando la comparación. Estas son las imágenes que se guardaron durante el
entrenamiento. Con mayor cantidad de imágenes, es mejor el resultado del reconocimiento.
Imagen 20. Imagen donde se indica el nombre dos personas diferentes. Realización Propia.
La aplicación puede reconocer varias personas en la imagen, para ello solo es necesario realizar el entrenamiento, de las personas que se desean reconocer.

50
PARTE 3. CIERRE DE LA INVESTIGACIÓN
CAPÍTULO 5. RESULTADOS Y DISCUSIÓN
Como resultado de la presente investigación se logró desarrollar una aplicación que,
utilizando una librería de visión artificial, es capaz de reconocer el rostro de una persona en
una imagen. La aplicación puede ser entrenada para reconocer una o varias personas.
El proceso de reconocimiento inicia con la etapa de detección de rostros, en este proceso se
utilizó el algoritmo de Viola-Jones, que hace parte de la librería OpenCV, y que utiliza
clasificadores en cascada ya entrenados, en donde se utilizaron bases de datos como la de
AT&T Laboratories Cambridge (Cambridge, 1994), la cual cuenta con diez imágenes
diferentes del rostro de cuarenta personas.
Para el reconocimiento se utiliza Eigenfaces, que también viene implementado en OpenCV,
El cual realiza la comparación de la imagen del rostro detectado con las imágenes
guardadas, si encuentra una imagen que se acerqué mucho a la detectada, se indica la
correspondencia.
El reconocimiento facial implementado en la aplicación, es muy utilizado en la biometría,
para la autenticación y la verificación de personas. Utilizando la librería OpenCV, y un
lenguaje de programación es posible realizar aplicaciones de esta técnica orientadas a la
seguridad o al control de personas en oficinas, aulas de clase o para la presentación de
pruebas supervisadas de forma remota.
Aunque existen aún varias complicaciones con estas técnicas ya que son susceptibles a la
luz y a factores como los accesorios que lleve la persona, vemos que, dentro de condiciones
controladas, su desempeño es muy alto y no requieren de computadores con gran capacidad
de procesamiento.
El campo del reconocimiento facial y de objetos, sigue desarrollándose y en el futuro será
el estándar para la autenticación de personas en bancos y tramites gubernamentales.

51
También harán parte de nuestros hogares, ya que esta tecnología se combina actualmente
con el Internet de las Cosas.
CAPÍTULO 6. CONCLUSIONES
De los resultados de la presente investigación, podemos concluir que es posible crear un
sistema de visión artificial con las tecnologías disponibles en el momento. Se logró
comprobar la hipótesis inicial, ya que utilizando OpenCv y un lenguaje de programación
orientado a objetos como C#, fue posible desarrollar una aplicación capaz de reconocer el
rostro de una persona, analizando el flujo de video capturado por una cámara web.
OpenCv nos provee grandes herramientas para aquellos que quieren iniciar se en el estudio
de la visión artificial y del reconocimiento de objetos en imágenes y video. Los sistemas de
cómputo actuales, los precios de los procesadores y discos duros, hacen ahora que sea
posible tener estos sistemas de visión artificial en equipos de cómputo de bajo costo o
incluso en celulares.
CAPÍTULO 7. PROSPECTIVA DEL TRABAJO DE GRADO
La aplicación desarrollada en la presente investigación, puede ser utilizada en control de
presencia o control de acceso en diferentes ámbitos educativos y empresariales.
Como trabajos futuros se puede integrar con una base de datos no relacional distribuida,
con el fin de poder tener varios nodos de consulta, que puedan ser utilizados por diferentes
cámaras, y un nodo de registro, el cual permitirá autorizar una persona, que luego se
replicara a todos los nodos de lectura. Esto con el fin de poder ganar velocidad y
desempeño al momento del reconocimiento.

52
PARTE 4. BIBLIOGRAFIA
Angulo Usategui, J. (1986). Visión Artificial por Computador. Madrid: Thomson Paraninfo S.A. Association Federation of International. (2006). Robots in Education, Entertainment and Service.
FIRA RoboWorld Congress 2006.
Basili, V., DeMarco, T., & Mili, A. (1999). Science and engineering for software development: a
recognition of Harlan D. Mills' legacy. In Proceedings of the 21st international conference
on Software engineering, 710-711.
BATCHEN, G. (2004). Arder en deseos.: La concepción de la fotografía. Barcelona: Editorial
Gustavo Gili, S.L.
Bidgoli, H. (2004). The Internet Encyclopedia, Volume 2. Bakersfield, California: John Wiley and
Sons.
Branch, J., & Olague, G. (2001). La visión por computador: Una aproximación al estado del arte.
Revista Dyna, 133.
Bristol Robotics Laboratory, T. P. (2010). staffwww.dcs.shef.ac.uk. Recuperado el 2013, de
http://staffwww.dcs.shef.ac.uk/people/C.Fox/Prescott_et_al_RISE2010r.pdf
Cáceres, T. J. (2002). La visión artificial y las operaciones morfológicas en imágenes binarias.
Alcalá, España.
Calle, A. S. (2005). Aplicaciones de la vision artificial y la biometria informatica. Madrid: Dykinson.
Cambridge, A. L. (1994). The Database of Faces. Obtenido de AT&T Laboratories Cambridge:
http://face-rec.org/databases/
Cubas, G., & Consuegra, P. (2001). Dispositivos autómatas para navegación, detección
Recoleccion de pelotas de tenis en ambientes conocidos. Revista Científica Ingeniería y
Desarrollo, http://rcientificas.uninorte.edu.co/index.php/ingenieria/article/view/2281/1490.
EmguCV, L. (02 de 2017). Emgu CV Docs. Obtenido de Emgu CV:
http://www.emgu.com/wiki/index.php/Main_Page
Feigenbaum, E. A. (1984). The fifth generation : artificial intelligence and Japan's computer
challenge to the world. New York: New American Library.
Freund, Y., & Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning. Journal
of Computer and System Sciences, 119–139.
Geeky, T. (01 de 01 de 2011). Opencv. Recuperado el 19 de 08 de 2013, de OpenCV: opencv.org
Gómez-Verdejo, V., Ortega-Moral, M., Arenas-García, J., & Figueiras-Vidal, A. R. (2006). Boosting
by weighting critical and erroneous samples. Neurocomputing, 679-685.
Group, T. (2012). Archimate 2.0 Specification. Obtenido de http://pubs.opengroup.org:
http://pubs.opengroup.org/architecture/archimate2-doc/
HERNANDEZ, E., CABRERA SARMIENTO, A., & SANCHEZ SOLANO, S. (2012). Implementación
híbrida hardware software del algoritmo de detección de rostros de Viola-Jones sobre
FPGA. Recuperado el 10 de 2016, de

53
http://www.scielo.org.ve/scielo.php?script=sci_arttext&pid=S1316-
48212012000200005&lng=es&nrm=iso
Heseltine, T., Pears, N., & Austin, J. (2002). Evaluation of image preprocessing techniques for
eigenface-based face recognition. In Second International Conference on Image and
Graphics, 677-685.
Hurtado, J., & Granados, A. (2007). Detección de flujo vehicular basado en visión artificial. Scientia
Et Technica.
Jain, A., Bolle, R., & Pankanti, S. (2006). Biometrics: personal identification in networked society.
New York: Springer Science & Business Media.
Jain, A., Flynn, P., & Ross, A. A. (2007). Handbook of biometric. New York: Springer Science &
Business Media.
Kearns, M., & Valiant, L. (1994). Cryptographic limitations on learning Boolean formulae and finite
automata. Journal of the ACM (JACM), 67-95.
Kearns, M., & Valiant, L. G. (1994). Learning Boolean formulae or finite automata is as hard as
factoring. Technical Report TR-14-88, Harvard University Aiken Computation Laboratory,
Technical Report TR-14-88.
Ken-ichi, M., Masatsugu, K., & Hidenori, S. (1978). Design of local parallel pattern processor for
image processing. Proceedings of the National Computer Conference, (págs. 1025, 1978).
ANAHEIM.
KIRBY, M., & SIROVICH, L. (1990). Application of the Karhunen-Loeve procedure for the
characterization of human faces. IEEE Transactions on Pattern analysis and Machine
intelligence, 103-108.
Kyoung-sig, R., Young, S., & Joo-young, K. (2005). Estados Unidos Patente nº 7151853.
Lankhorst, M. M., Proper, H. A., & Jonkers, H. (2009). The architecture of the archimate language.
Enterprise, Business-Process and Information Systems Modeling, 367-380.
López Beltrán, R., & Paternina Arboleda, C. D. (2001). Análisis cinemático de un robot autónomo
con ruedas. Revista Científica Ingeniería y Desarrollo.
López Beltrán, R., Sotter Solano, E., & Zurek Varela, E. (2001). Aplicación del sistema Robot Vision
PRO para operaciones automáticas de control de calidad. Revista Científica Ingeniería y
Desarrollo.
Marr, D. (1982). Vision - A computational investigation into the human representation and
processing of visual information. San Francisco: W. H. Freeman.
Marr, D. (1982). Vision: A Computational Investigation into the Human Representation and
Processing of Visual Information. San Francisco: W. H. Freeman.
Mayhua-Lopez, E., Gómez-Verdejo, V., & Figueiras-Vidal, A. R. (2012). Real Adaboost with gate
controlled fusion. IEEE transactions on neural networks and learning systems, 2003-2009.
Mery, D. (2004). Apuntes de Visión por computador. Obtenido de Visión por computador:
http://dmery.sitios.ing.uc.cl/Prints/Books/2004-ApuntesVision.pdf

54
Michalski, R. S., Carbonell, J. G., & Mitchell, T. (2013). Machine learning: An artificial intelligence
approach. Springer Science & Business Media.
Microsoft. (02 de 2017). Introduction to the C# Language and the .NET Framework. Obtenido de
Visual Studio 2015 - Getting Started with C#: https://msdn.microsoft.com/en-
us/library/z1zx9t92.aspx
Ministerio de Educación Nacional. (15 de 05 de 2013). MEN. Recuperado el 03 de 07 de 2013, de
Robot colombiano en la NASA: http://www.mineducacion.gov.co/cvn/1665/w3-article-
322402.html
Múnera Salazar, L. E., & Manzano Herrera, D. A. (2012). Sistema de visión artificial para conteo de
objetos en movimiento. El Hombre y la Máquina - Facultad de Ingeniería, Universidad
Autónoma de Occidente, 87-101.
Muñoz-Romero, S., Arenas-García, J., & Gómez-Verdejo, V. (2009). Real Adaboost ensembles
with emphasized subsampling. Bio-Inspired Systems: Computational and Ambient
Intelligence, 440-447.
Nakano, & Yasuaki. (1988). Optical character reader. Tokio: Hitachi Ltda.
Navas, E. (2013). OpenCV. Obtenido de Clasificador Haar: opencv.org
Nishino, H. (1978). PIPS (Pattern Information Processing System). Proc. 4th Int. Joint Conf. Pattern
Recognition, 1152–1161.
OpenCv. (03 de 2017). Face Recognition with OpenCV. Obtenido de Open Source Computer
Vision: http://docs.opencv.org/3.2.0/da/d60/tutorial_face_main.html
OpenCv, O. (Enero de 2017). Face Detection using Haar Cascades. Obtenido de OpenCV Docs:
http://docs.opencv.org/trunk/d7/d8b/tutorial_py_face_detection.html
Pajares Martinsanz, G., & Santos Peñas, M. (2006). Inteligencia artificial e ingeniería del
conocimiento. México: Alfaomega Grupo Editor.
Pajares, G., & De La Cruz, J. M. (2004). A wavelet-based image fusion tutorial. Pattern recognition,
1855-1872.
Pankanti, S., Bolle, R. M., & Jain, A. (2002). Biometrics: The future of identification . Computer, 46-
49.
Papageorgiou, C. P., Oren, M., & Poggio, T. (1998). A general framework for object detection. .
Sixth international conference In Computer vision. IEEE., 555-562.
Peason, K. (1901). On lines and planes of closest fit to systems of point in space. Philosophical
Magazine, 559-572.
Pedregosa, F., Varoquaux, G., & Gramfort, A. (2011). Scikit-learn: Machine learning in Python.
Journal of Machine Learning Research, 2825-2830.
PHILLIPS, P. J., & et al. (25 de Julio de 2005). Overview of the face recognition grand challenge.
Obtenido de IEEE Computer Society Conference on Computer Vision and Pattern
Recognition:
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1467368&isnumber=31472

55
Pressman, R. S. (2005). Software engineering: a practitioner's approach. Palgrave Macmillan.
Roberts, L. G. (1963). Machine Perception of Three-Dimensional Solids. InOptical and
Electrooptical Information Processing. 159-197.
Rocha, C. A., & Escorcia, J. R. (2010). Sistema de Visión Artificial para la Detección y el
Reconocimiento de Señales de Tráfico basado en Redes Neuronales. Obtenido de Eighth
LACCEI Latin American and Caribbean Conference for Engineering and Technology:
http://www.laccei.org/
Rodríguez Salavarría, J. P. (Octubre de 2009). Sistema de control de acceso basado en el perfil
lateral de una persona utilizando visión artificial. Obtenido de Escuela Politécnica Nacional:
http://bibdigital.epn.edu.ec/handle/15000/1906
Sánchez, J. S. (2002). Avances en robótica y visión por computador. Castilla: Univ de Castilla La
Mancha.
Schraft, R. D., Schaeffer, C., & May, T. (1998). Care-O-botTM: the concept of a system for assisting
elderly or disabled persons in home environments. Recuperado el 2013, de Industrial
Electronics Society:
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=724115&isnumber=15649
Sebastiani, F. (2002). Machine learning in automated text categorization. ACM computing surveys
(CSUR), 1-47.
Sirovich, L., & Kirby, M. (1987). Low-dimensional procedure for the characterization of human
faces. 519-524.
Sommerville, I. (1996). Software process models. Acm Computing Surveys (Csur).
Sommerville, I. (2006). Ingenieria del Software. Madrid: Pearson.
Stephen Gould, J. A. (2007). http://www.aaai.org. Recuperado el 2013, de
http://www.aaai.org/Papers/IJCAI/2007/IJCAI07-341.pdf
Sucar, L. E. (2002). Procesamiento de Imagenes y Vision Computacional.
Turk, M. (1997). Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE
Transactions on Pattern Analysis and Machine Intelligence.
Turk, M., & Pentland, A. (1991). Eigenfaces for recognition. Journal of cognitive neuroscience, 71-
86.
Valiant, L. G. (1984). A theory of the learnable. Communications of the ACM, 1134-1142.
Viola, P., & Jones, M. (2001). Rapid object detection using a boosted cascade of simple features.
Obtenido de Proceedings of the 2001 IEEE Computer Society Conference on Computer
Vision and Pattern Recognition:
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=990517&isnumber=21353
Viola, P., & Jones, M. J. (2004). Robust real-time face detection. International Journal of Computer
Vision., 57, 137-154.
Woodward Jr, J. D., Horn, C., Gatune, J., & Thomas, A. (2003). Biometrics: A look at facial
recognition. SANTA MONICA CA: RAND CORP.

56
Xiao, Q. (2007). Technology review-biometrics-technology, application, challenge, and
computational intelligence solutions. IEEE Computational Intelligence Magazine, 5-25.
Zafeiriou, S. (2013). Face Recognition and Verification Using Photometric Stereo: The Photoface
Database and a Comprehensive Evaluation. Information Forensics and Security, IEEE
Transactions, 121 - 135.

57
PARTE 5. ANEXOS
5.1. RECONOCIMIENTO DE ROSTROS
Para realizar el reconocimiento de rostros, se utiliza un clasificador en cascada que ya está
entrenado por OpenCV. Este clasificador tiene el nombre de:
haarcascade_frontalface_default.xml.
public CascadeClassifier Face = new CascadeClassifier(Application.StartupPath +
"/Cascades/haarcascade_frontalface_default.xml");
Para la detección se utiliza el método de OpnCV: DetectMultiScale, el cual usa el
clasificador en cascada, y recibe la imagen en tonos de grises.
//DetectorderostrosRectangle[] facesDetected = Face.DetectMultiScale(gray_frame, 1.2, 10, new Size(50, 50),
Size.Empty);
La aplicción realiza un analisis constant del flujo de video, para ello se utiliza un ciclo for
que recorre los rostros detectados y los compara con las imágenes de muestra utilizando
EigenFaces.
//Rostrosdetectadosfor(inti=0;i<facesDetected.Length;i++){//SecalculanlospuntosparaelrectangulofacesDetected[i].X+=(int)(facesDetected[i].Height*0.15);facesDetected[i].Y+=(int)(facesDetected[i].Width*0.22);facesDetected[i].Height-=(int)(facesDetected[i].Height*0.3);facesDetected[i].Width-=(int)(facesDetected[i].Width*0.35);result=currentFrame.Copy(facesDetected[i]).Convert<Gray,byte>().Resize(100,100,Emgu.CV.CvEnum.INTER.CV_INTER_CUBIC);result._EqualizeHist();currentFrame.Draw(facesDetected[i],newBgr(Color.Red),2);if(Eigen_Recog.IsTrained){stringname=Eigen_Recog.Recognise(result);intmatch_value=(int)Eigen_Recog.Get_Eigen_Distance;//SedibujaelrecuadroencerrandoelrostrodetectadocurrentFrame.Draw(name+"",reffont,newPoint(facesDetected[i].X-2,facesDetected[i].Y-2),newBgr(Color.LightGreen));ADD_Face_Found(result,name,match_value);}}

58
5.2. CLASE PRINCIPAL DE LA APLICACIÓN
La Clase ControlPresencia, se encarga de controlar el flujo de la aplicación, esta clase
corresponde al formulario principal de la aplicación en la cual se inicia el flujo de video
desde la cámara web y se analiza en busca de rostros.
Para la detección del rostro se utiliza el método:
Rectangle[]facesDetected=Face.DetectMultiScale(gray_frame,1.2,10,newSize(50,50),Size.Empty);
El código complete de la clase es el siguiente: #regionvariablesImage<Bgr,Byte>currentFrame;//ImagentomadaporlacamaraImage<Gray,byte>result,TrainedFace=null;//VariableparaguardarelentrenamientoImage<Gray,byte>gray_frame=null;//ImagenenescaladegrisesCapturegrabber;//Variabledecapturadevideostringpath=Application.StartupPath;//Metododedetección,seusaelcalsificador:haarcascade_frontalface_defaultpublicCascadeClassifierFace=newCascadeClassifier(Application.StartupPath+"/Cascades/haarcascade_frontalface_default.xml");MCvFontfont=newMCvFont(FONT.CV_FONT_HERSHEY_COMPLEX,0.5,0.5);intNumLabels;//EntrenamientoporEigenfacesClassifier_TrainEigen_Recog=newClassifier_Train();#endregionpublicControlPresencia(){InitializeComponent();//Loadofpreviustrainnedfacesandlabelsforeachimageif(Eigen_Recog.IsTrained){message_bar.ForeColor=Color.Green;message_bar.Text="Datosdeentrenamientolistos!!!";}else{message_bar.ForeColor=Color.Red;message_bar.Text="Noexistendatosdeentrenamiento.Deberealizarelentrenamiento.";}initialise_capture();}//CamaraStartStoppublicvoidinitialise_capture(){try{

59
grabber=newCapture();grabber.QueryFrame();//InitializetheFrameGrabereventApplication.Idle+=newEventHandler(FrameGrabber_Standard);}catch(Exceptionex){MessageBox.Show("Error",ex.Message,MessageBoxButtons.OK,MessageBoxIcon.Error);}}privatevoidstop_capture(){Application.Idle-=newEventHandler(FrameGrabber_Standard);if(grabber!=null){grabber.Dispose();}}voidFrameGrabber_Standard(objectsender,EventArgse){//SetomalaimagenactualqueestarecibiendolacamarawebcurrentFrame=grabber.QueryFrame().Resize(320,240,Emgu.CV.CvEnum.INTER.CV_INTER_CUBIC);//Seconvierteagrisesif(currentFrame!=null){gray_frame=currentFrame.Convert<Gray,Byte>();//DetectorderostrosRectangle[]facesDetected=Face.DetectMultiScale(gray_frame,1.2,10,newSize(50,50),Size.Empty);//Rostrosdetectadosfor(inti=0;i<facesDetected.Length;i++){//SecalculanlospuntosparaelrectangulofacesDetected[i].X+=(int)(facesDetected[i].Height*0.15);facesDetected[i].Y+=(int)(facesDetected[i].Width*0.22);facesDetected[i].Height-=(int)(facesDetected[i].Height*0.3);facesDetected[i].Width-=(int)(facesDetected[i].Width*0.35);result=currentFrame.Copy(facesDetected[i]).Convert<Gray,byte>().Resize(100,100,Emgu.CV.CvEnum.INTER.CV_INTER_CUBIC);result._EqualizeHist();currentFrame.Draw(facesDetected[i],newBgr(Color.Red),2);if(Eigen_Recog.IsTrained){stringname=Eigen_Recog.Recognise(result);intmatch_value=(int)Eigen_Recog.Get_Eigen_Distance;//SedibujaelrecuadroencerrandoelrostrodetectadocurrentFrame.Draw(name+"",reffont,newPoint(facesDetected[i].X-2,facesDetected[i].Y-2),newBgr(Color.LightGreen));ADD_Face_Found(result,name,match_value);}}//Semuestraelrectanguloenpantallaimage_PICBX.Image=currentFrame.ToBitmap();}}

60
5.1. METODO DE EIGENFACES
El reconocimiento del rostro se realiza mediante Eigenfaces, el siguiente método que
implementa OpenCV, permite realizar la comparación con Eigenfaces, el cual retorna un
valor de distancia calculada entre las imagenes de entrenamiento y la imagen actual.
El valor de Eigen_threshold, permite ajustar el umbral para indicar si se ha encontrado
concordancia o si se marca como desconocido.
///<summary>///RecogniseaGrayscaleImageusingthetrainedEigenRecogniser///</summary>///<paramname="Input_image"></param>///<returns></returns>publicstringRecognise(Image<Gray,byte>Input_image,intEigen_Thresh=-1){if(_IsTrained){FaceRecognizer.PredictionResultER=recognizer.Predict(Input_image);if(ER.Label==-1){Eigen_label="Desconocido";Eigen_Distance=0;returnEigen_label;}else{Eigen_label=Names_List[ER.Label];Eigen_Distance=(float)ER.Distance;if(Eigen_Thresh>-1)Eigen_threshold=Eigen_Thresh;//OnlyusethepostthresholdruleifweareusinganEigenRecognizer//sinceFisherandLBHPthresholdsetduringtheconstructorwillworkcorrectlyif(Eigen_Distance>Eigen_threshold)returnEigen_label;elsereturn"Desconocido";}}elsereturn"";}