1. entendimiento del negociopegasus.javeriana.edu.co/.../archivos/crisp/crisp.docx · web viewa...
TRANSCRIPT

CRISP-DM
SENTINEL: Analítica sobre percepción de corrupción en Facebook
Trabajo de grado 2017-30
Ingeniería de Sistemas
Pontificia Universidad Javeriana
Manuela Forero Pedreros
Jeffrey Torres Arango
Sebastián Gracia Valderrama
Alexandra Pomares Quimbaya Ph.D.
Director Trabajo de grado
Contenido1. Entendimiento del negocio........................................................................................................................6

1.1 Contexto...............................................................................................................................................6
1.2 Objetivos del negocio utilizando minería de datos..............................................................................9
1.3 Evaluar la situación actual...................................................................................................................9
1.4 Determinar los objetivos de minería..................................................................................................18
1.5 Criterio de éxito de minería...............................................................................................................19
2. Entendimiento de datos............................................................................................................................19
2.1 Recopilar los datos iniciales...............................................................................................................19
2.2 Descripción inicial de datos...............................................................................................................20
2.3 Exploración inicial de datos...............................................................................................................23
2.4 Verificar calidad de los datos.............................................................................................................28
3. Preparación de datos................................................................................................................................29
3.1 Selección de datos..............................................................................................................................29
3.2 Limpieza de datos..............................................................................................................................29
3.3 Construcción de datos........................................................................................................................30
3.4 Integración de datos...........................................................................................................................30
3.5 Adecuación de datos..........................................................................................................................30
4. Modelo.....................................................................................................................................................31
4.1 Seleccionar técnicas de minería.........................................................................................................31
4.1.1 Técnicas Predictivas....................................................................................................................31
4.1.2 Técnicas Descriptivas.................................................................................................................32
4.2 Definir el diseño de pruebas para el modelo......................................................................................37
4.3 Construir el modelo............................................................................................................................38
4.3.1 Análisis de sentimientos.............................................................................................................38
4.3.2 Sesgo...........................................................................................................................................40
4.3.3 Asociación de palabras...............................................................................................................41
4.3.4 Funciones agregadas...................................................................................................................43
4.4 Evaluación de modelos......................................................................................................................47
4.4.1 Evaluación de análisis de sentimiento............................................................................................47
4.4.2 Evaluación de algoritmos descriptivos.......................................................................................55
5. Evaluación................................................................................................................................................56
5.1 Evaluación de resultados....................................................................................................................56
5.2 Encuesta TAM...................................................................................................................................59
5.2 Próximos pasos..................................................................................................................................63
2

6. Despliegue................................................................................................................................................63
6.1 Plan de despliegue..............................................................................................................................63
6.2 Plan de monitoreo y mantenimiento..................................................................................................66
6.3 Reporte final.......................................................................................................................................71
6.4 Revisión del proyecto........................................................................................................................71
6.4.1 Fortalezas....................................................................................................................................71
6.4.2 Debilidades.................................................................................................................................72
6.4.3 Trabajo futuro.............................................................................................................................72
7. Referencias...........................................................................................................................................73
Tabla de ilustraciones Ilustración 1 Logo observatorio.........................................................................................................6
Ilustración 2 Composición del Observatorio.......................................................................................7
Ilustración 3 Modelo de dominio.....................................................................................................15
Ilustración 4 Modelo de datos..........................................................................................................21
Ilustración 5 Publicación de Facebook..............................................................................................22
Ilustración 6 Cantidad de publicaciones que comparten los usuarios por página de noticias...................24
Ilustración 7 Reacciones 'wow'........................................................................................................25
Ilustración 8 Reacciones 'sad'..........................................................................................................25
Ilustración 9 Reacciones 'love'.........................................................................................................26
Ilustración 10 Reacciones 'haha'......................................................................................................26
Ilustración 11 Reacciones 'angry'.....................................................................................................27
Ilustración 12 Reacciones 'like'........................................................................................................27
Ilustración 13 Reacciones vs shares.................................................................................................28
Ilustración 14 Modelo de analítica...................................................................................................31
Ilustración 15 visualización análisis de sentimientos..........................................................................32
Ilustración 16 comparación de los medios.........................................................................................33
Ilustración 17 Visualización de todos los medios...............................................................................34
Ilustración 18 grafo........................................................................................................................35
Ilustración 19 Función agregada – Cantidad de publicaciones que realiza un medio sobre un caso.........36
Ilustración 20 Función agregada – Cantidad de publicaciones que realiza un medio sobre un partido
político..........................................................................................................................................37
Ilustración 21 Función agregada – Reacciones en noticias sobre un caso de corrupción........................37
Ilustración 22 Salida de algoritmo de análisis de sentimientos............................................................38
3

Ilustración 23 Análisis de sentimientos para Álvaro Uribe Vélez........................................................39
Ilustración 24 Noticia sobre Álvaro Uribe Vélez en noviembre 16 del 2016, El Tiempo........................39
Ilustración 25 Visualización del algoritmo de sesgo...........................................................................40
Ilustración 26 Algoritmo de sesgo para publicaciones sobre corrupción de un líder de opinión..............41
Ilustración 27 Grafo (asociación de palabras) para publicaciones........................................................42
Ilustración 28 Grafo (asociación de palabras) para comentarios..........................................................43
Ilustración 29 Función agregada - Reacciones en noticias sobre un caso de corrupción.........................44
Ilustración 30 Función agregada - número total de reacciones que han hecho en la página de un líder de
opinión..........................................................................................................................................44
Ilustración 31 Función agregada - Comentarios populares de un líder.................................................45
Ilustración 32 Función agregadas - Cantidad de publicaciones sobre el partido político vs cantidad de
publicaciones de corrupción que mencionan al partido.......................................................................46
Ilustración 33 Función agregada - Publicaciones de dos medios sobre un caso de corrupción................46
Ilustración 34 Función agregada - Nube de palabras de publicaciones en la página de un líder de opinión
.....................................................................................................................................................47
Ilustración 35 Variables externas: Involucrados................................................................................60
Ilustración 36 Facilidad de uso percibida..........................................................................................60
Ilustración 37 Utilidad percibida......................................................................................................61
Ilustración 38 Actitud hacia el uso...................................................................................................61
Ilustración 39 Nivel satisfacción Sentinel.........................................................................................62
Ilustración 40 Nivel satisfacción objetivo general..............................................................................62
Ilustración 41 Buscar ID de una página de Facebook.........................................................................71
Ilustración 42 ID de página de Facebook..........................................................................................71
Tabla de tablas Tabla 1 Datos del Observatorio Transparencia y Anticorrupción...........................................................9
Tabla 2 Datos de contacto del Observatorio Transparencia y Anticorrupción.........................................9
Tabla 3 Recursos provistos por diferentes entidades..........................................................................11
Tabla 4 Recursos humanos con los que cuenta el proyecto.................................................................12
Tabla 5 Herramientas de desarrollo con los que cuenta el proyecto.....................................................12
Tabla 6 Recursos físicos con los que cuenta el proyecto.....................................................................12
Tabla 7 Restricciones del proyecto en términos de minería de datos....................................................13
Tabla 8 Descripción del vocabulario del negocio...............................................................................14
Tabla 9 Preguntas relacionadas con entidad......................................................................................16
4

Tabla 10 Preguntas relacionadas con casos de corrupción..................................................................17
Tabla 11 Preguntas relacionadas con personas naturales.....................................................................17
Tabla 12 Preguntas relacionadas a publicaciones...............................................................................17
Tabla 13 Preguntas relacionadas con comentarios.............................................................................18
Tabla 14 Preguntas relacionadas con involucrados............................................................................18
Tabla 15 Descripción de elementos de Facebook..............................................................................20
Tabla 16 Publicación de Facebook...................................................................................................23
Tabla 17 Atributos nominales..........................................................................................................23
Tabla 18 Resultados algoritmo de análisis de sentimientos con diccionario político..............................48
Tabla 19 Resultados algoritmo de análisis de sentimientos con diccionario genérico............................48
Tabla 20 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.4.............................................49
Tabla 21 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.2.............................................50
Tabla 22 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.3.............................................51
Tabla 23 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.5.............................................51
Tabla 24 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.6............................................52
Tabla 25 Matriz de confusión Cloud Natural Language API, cutoff = 0.25..........................................53
Tabla 26 Matriz de confusión Cloud Natural Language API, cutoff = 0.2............................................53
Tabla 27 Matriz de confusión Cloud Natural Language API, cutoff = 0.3............................................54
Tabla 28 Matriz de confusión Cloud Natural Language API, cutoff = 0.4............................................55
Tabla 29 Encuesta escala de clasificación.........................................................................................60
Tabla 30 Especificaciones...............................................................................................................63
Tabla 31 Esquema..........................................................................................................................70
1. Entendimiento del negocio Sentinel es el nombre del proyecto cuyo principal objetivo es desarrollar un modelo de analítica que
permita enriquecer la información disponible para el Observatorio de Transparencia y Anticorrupción de
Colombia utilizando como fuente de datos la red social Facebook abierta.
5

Para poder llevar a cabo la realización de dicho proyecto planteado por el grupo de trabajo es necesario
contar con la ayuda de expertos y entidades que sepan de primera mano el problema del negocio y que
permitan proveer lineamientos y objetivos claros, así como un cliente final que pueda ser beneficiado del
producto a entregar.
Por esta razón, el grupo de trabajo contactó al Observatorio Nacional de Transparencia y
Anticorrupción colombiano debido a su iniciativa, su gran interés y alto de nivel de análisis del fenómeno
de la corrupción en Colombia (Observatorio de Transparencia y Anticorrupción, 2017).
Adicionalmente, los integrantes del grupo de trabajo asistieron a múltiples conversatorios los cuales
permitieron dar una vista general de la situación actual de Colombia y su lucha contra la corrupción y
cómo las tecnologías de la información hacen parte de este nuevo movimiento y la revolución tecnológica
en sectores públicos, como lo es el gobierno, y sector privado.
Dentro de los conversatorios se resaltan los siguientes:
1. "Big Data, ciudadanía inteligente y prevención de la corrupción", llevado a cabo el 9 de mayo de
2017 en la Universidad Externado de Colombia.
2. "Primer foro tecnologías para la lucha anticorrupción", llevado a cabo 16 de mayo de 2017 en el
Jockey Club de la Universidad del Rosario.
1.1 Contexto¿Qué es el Observatorio?
Ilustración 1 Logo observatorio
Logo observatorio
"El Observatorio de Transparencia y Anticorrupción es una herramienta para la medición y análisis del
fenómeno de la corrupción, a partir de la interacción entre entidades, ciudadanos, y organizaciones
públicas y privadas del orden nacional y territorial, para contribuir a elevar el nivel de transparencia en la
gestión pública" (Observatorio de Transparencia y Anticorrupción, 2017).
El trabajo del Observatorio gira en torno a tres ejes:
1. Observar: Recopilar, analizar y visibilizar indicadores sobre transparencia y anticorrupción.
6

2. Educar: Brindar herramientas para la promoción de la transparencia y la lucha contra la
corrupción.
3. Dialogar: Facilitar espacios para el diálogo entre ciudadanía, academia y servidores públicos.
¿Cómo opera el Observatorio?
El Observatorio es liderado por la Secretaría de Transparencia de la Presidencia de la República, con
el apoyo del Área de Información y Sistemas de la entidad. Para el proceso de formulación, cálculo,
análisis y presentación de indicadores, el Observatorio cuenta con una Mesa Técnica, convocada por la
Secretaría de Transparencia, en la que participan representantes de las distintas entidades integrantes de la
Comisión Nacional de Moralización. A través de estos encuentros se definen los protocolos para el
intercambio de la información necesaria para alimentar los indicadores, se revisan los resultados arrojados
por los indicadores existentes y se proponen nuevos frentes de trabajo (Observatorio de Transparencia y
Anticorrupción, 2017).
¿Quiénes componen el Observatorio?
El Observatorio fue concebido como una herramienta a disposición de la Comisión Nacional de
Moralización, y como nodo de articulación institucional y punto de convergencia de estas entidades con
la sociedad civil y la comunidad (Observatorio de Transparencia y Anticorrupción, 2017).
Ilustración 2 Composición del Observatorio
Comisión Nacional de Moralización
La Comisión es un organismo especial, creado mediante la Ley 1474 de 2011, encargado, entre otras
funciones, de:
Coordinar el intercambio de información en materia de lucha contra la corrupción.
7

Establecer los indicadores de eficacia, eficiencia y transparencia obligatorios para la
administración pública y los mecanismos de divulgación.
Orientar y coordinar la realización de actividades pedagógicas e informativas sobre temas
asociados con la ética y la moral públicas, los deberes y las responsabilidades en la función
pública.
La Comisión es liderada por el presidente de la República, y hacen parte de la misma el Procurador
General de la Nación, el Contralor General de la República, la Auditora General de la República, el Fiscal
General de la Nación, el Defensor del Pueblo, los presidentes del Senado de la República y la Cámara de
Representantes, los presidentes de la Corte Suprema de Justicia y del Consejo de Estado, el Ministro del
Interior, el Ministro de Justicia, y el Secretario de Transparencia (Observatorio de Transparencia y
Anticorrupción, 2017).
Misión del Observatorio
Generar insumos para que tanto las entidades del Estado, en lo nacional y territorial, como instancias
de la sociedad civil, el sector privado, el mundo académico, la comunidad internacional y la ciudadanía en
general, tengan mayores y mejores elementos para la toma de decisiones en materia de lucha contra la
corrupción y promoción de la transparencia.
Visión del Observatorio
El Observatorio Transparencia y Anticorrupción será reconocido a nivel territorial, a nivel nacional e
internacional como referente en la lucha contra la corrupción y promoción de la transparencia, además de
constituirse en la herramienta por excelencia para alimentar la toma de decisiones y el monitoreo de las
acciones de las entidades integrantes de la Comisión Nacional de Moralización, las Comisiones
Regionales de Moralización y la Comisión Nacional Ciudadana para la lucha contra la corrupción
(Observatorio de Transparencia y Anticorrupción, 2017).
Datos de la entidadNombre Observatorio de Transparencia y Anticorrupción
Ubicación Carrera 8 # 12B - 61 Piso 10 Edificio BIC - Bogotá D.C
Tabla 1 Datos del Observatorio Transparencia y Anticorrupción
Punto de contactoPaula Castañeda [email protected]
Tabla 2 Datos de contacto del Observatorio Transparencia y Anticorrupción
8

1.2 Objetivos del negocio utilizando minería de datos Los objetivos principales de negocio del observatorio con el análisis que se va a realizar son:
Objetivo general
Crear un instrumento capaz de monitorear los casos de corrupción, la actividad de los medios y de los
usuarios de Facebook frente a estos sucesos, donde se ven involucradas diferentes entidades, para brindar
los insumos necesarios que permitan hacer un diagnóstico de la corrupción en esta red social.
Objetivos específicos
El instrumento debe permitir mejorar la forma de hacer monitoreo de medios en la red social
Facebook.
El instrumento debe permitir contrastar la percepción de la corrupción en la red social Facebook
contra las encuestas realizadas en Colombia (LAPOP) para poder determinar si se debe tratar cada
una de forma diferente.
1.3 Evaluar la situación actual El Observatorio Nacional de Transparencia y Anticorrupción cuenta con una caja de herramientas que
consolida los instrumentos que se deben tener en cuenta para luchar la corrupción y promover la
transparencia. A continuación, se mencionan algunas de esos instrumentos y cómo estos llegan a
diferentes regiones del país (Observatorio de Transparencia y Anticorrupción, 2017):
1. Mejorar el acceso y la calidad de la información para los ciudadanos
a. Departamento Nacional de planeación (Programa Nacional de Servicio al Ciudadano).
b. Función pública (Política Anti trámites).
c. Ley 1712 de 2014 (Ley de Transparencia).
2. Fortalecer las herramientas de gestión pública para la prevención de la corrupción
a. Procuraduría General de la Nación (Índice de Gobierno Abierto IGA).
b. Guía de Auditoria para Entidades Públicas (Departamento Administrativo de la Función
Pública).
3. Incrementar la incidencia del control social
a. Elefantes Blancos.
b. CiudadanosActivos.com
c. Termómetro de precios de medicamentos.
4. Promover la cultura de la integridad en los sectores público, privado y en la sociedad civil.
a. Rutas pedagógicas para una Cultura de Integridad.
5. Desarrollar herramientas para luchar contra la impunidad en actos de corrupción
9

a. Observatorio Nacional de Transparencia y Anticorrupción.
b. Ley 1778 de 2016 (Ley anti soborno).
Una vez evaluada la situación actual del Observatorio Nacional de Transparencia y Anticorrupción el
grupo de trabajo identificó la oportunidad de proveer una percepción social frente a la corrupción y de
esta manera apoyar la toma de decisiones para poder crear propuestas, alternativas y ser agentes de
cambio en un ambiente virtual y social frente a la corrupción en Colombia.
El Observatorio Nacional de Transparencia y Anticorrupción decide entonces apoyar al grupo de
trabajo con información y lineamentos para llevar a cabo un trabajo de calidad y con impacto social, con
ánimos de enriquecer y fortalecer su valor, para así poder contar con una perspectiva social y directa con
la ciudadanía.
A continuación, se listarán los recursos humanos y físicos con los que cuenta el proyecto para su
elaboración y ejecución.
NOTA: Algunos recursos listados a continuación provienen de diferentes fuentes, por esta razón se
especifica el nombre del recurso, la descripción y el dueño.
RecursosNombre Descripción Dueño
Lexicones de sentimientos (CAOBA, 2017)
Desarrollado por la Alianza CAOBA.
Alianza CAOBA
Casos representativos de corrupción (2000-2015) (Ortiz,
2017)
Es una colección de los casos más representativos de corrupción colombianos identificado por el Observatorio Nacional de Transparencia y Anticorrupción.
Observatorio Nacional de Transparencia y Anticorrupción – Secretaria de Transparencia
Análisis del sentimiento político mediante la aplicación de
herramientas de minería de datos a través del uso de redes
sociales (Caicedo, Carrillo, Forero, & Ureña, 2017)
Fue un trabajo de grado realizado por estudiantes de Ingeniería industrial bajo la asesoría de Jorge Alvarado. En este trabajo se desarrolla un análisis de sentimiento enfocado a las redes sociales y enfocado a la política.
Luis Eduardo Caicedo Ortiz, Angie Carrillo Chappe, Catalina
Forero Arévalo, Julián David Urueña García, Juan Camilo
Urueña.Director TG: Alvarado Valencia, Jorge Andrés
RART 2.0 (Facebook Extractor) Basado en el trabajo de grado RART desarrollado por el grupo de trabajo, este extractor de datos está desarrollado e implementado en Python y
Grupo de trabajo.
10

permite extraer constantemente los datos de Facebook (Calambás Marin & Mendoza, 2016).
Tabla 3 Recursos provistos por diferentes entidades
Recurso HumanoNombre Descripción Rol Institución
Jeffrey Torres Integrante del equipo de trabajo de grado
SENTINEL
Desarrollador del proyecto SENTINEL.
Grupo de trabajo de grado Sentinel.
Pontificia Universidad Javeriana
Manuela Forero Integrante del equipo de trabajo de grado
SENTINEL
Desarrollador del proyecto SENTINEL.
Grupo de trabajo de grado Sentinel.
Pontificia Universidad Javeriana
Sebastián Gracia Integrante del equipo de trabajo de grado
SENTINEL
Desarrollador del proyecto SENTINEL.
Grupo de trabajo de grado Sentinel.
Pontificia Universidad Javeriana
Mauricio Ortiz Coronado
Politólogo y Abogado. Profesional del Observatorio de Transparencia y Anticorrupción –
Secretaria de Transparencia
Colaborador y asesor. Observatorio Nacional de Transparencia y Anticorrupción –
Secretaría de Transparencia
Paula Andrea Castañeda Aldana
Politóloga. Profesional especializada de la
línea de innovación. Secretaria
de Transparencia.
Colaborador y asesor. Observatorio Nacional de Transparencia y Anticorrupción –
Secretaría de Transparencia
Sebastián Pérez Mora Filósofo y magister en política pública.
Asesor del Observatorio de Transparencia y Anticorrupción –
Secretaria de Transparencia
Colaborador y asesor. Observatorio Nacional de Transparencia y Anticorrupción –
Secretaría de Transparencia
Alexandra Pomares Profesora Asociada.Ingeniera de Sistemas.
PhD en Ingeniería, Universidad de los Andes. Doctora en
Informática, Universidad de
Grenoble
Directora del trabajo de grado y asesor.
Departamento de Ingeniería de Sistemas - Pontificia Universidad
Javeriana
Tabla 4 Recursos humanos con los que cuenta el proyecto.
Herramientas
11

Para llevar a cabo el desarrollo de la plataforma y su correspondiente implementación y despliegue, se
necesitan de una serie de herramientas para llevar a cabo dicha tarea.
HerramientasNombre RazónPython Debido a su gran variedad de
librerías y paquetes, Python será usado para la implementación y desarrollo del módulo de analítica.
Ubuntu Será utilizado para ejecutar scripts, programas y desarrollos del grupo de trabajo, ya sea para el módulo de analítica o la extracción de datos.
R Por su facilidad y potencia, es el lenguaje de programación preferido para desarrollar proyectos de analítica y minería de datos y hará parte del desarrollo de módulo de analítica.
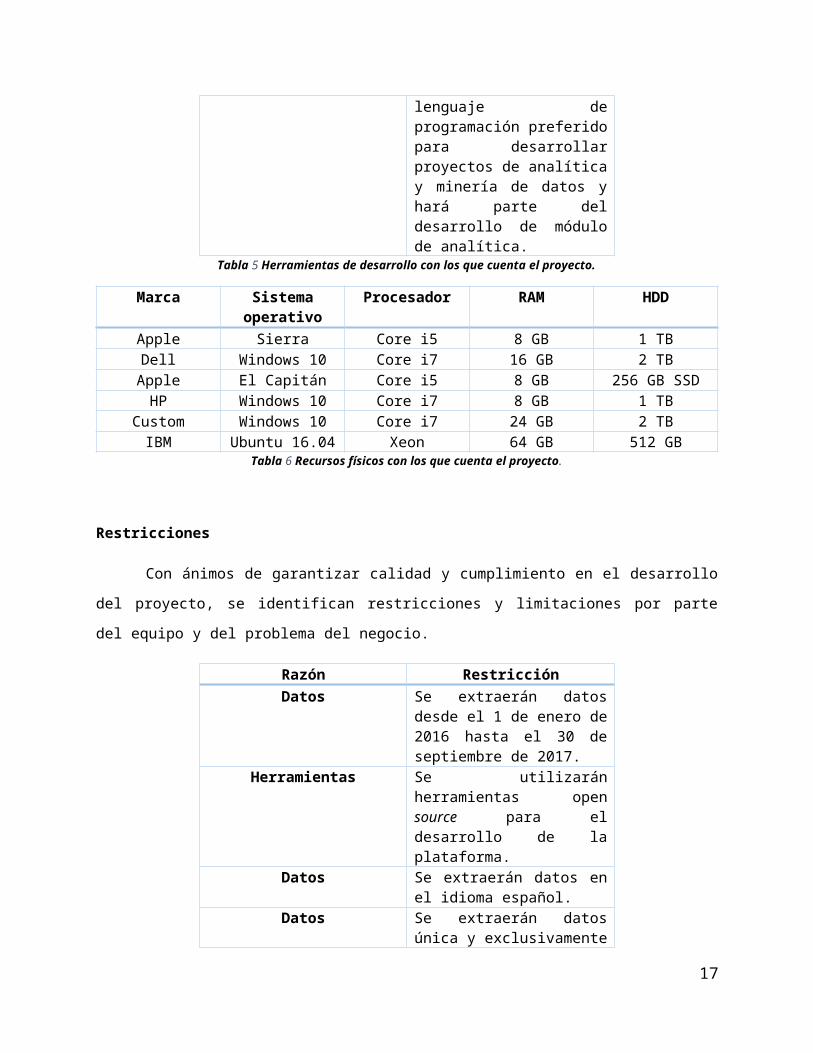
Tabla 5 Herramientas de desarrollo con los que cuenta el proyecto.
Marca Sistema operativo
Procesador RAM HDD
Apple Sierra Core i5 8 GB 1 TBDell Windows 10 Core i7 16 GB 2 TB
Apple El Capitán Core i5 8 GB 256 GB SSDHP Windows 10 Core i7 8 GB 1 TB
Custom Windows 10 Core i7 24 GB 2 TBIBM Ubuntu 16.04 Xeon 64 GB 512 GB
Tabla 6 Recursos físicos con los que cuenta el proyecto.
Restricciones
Con ánimos de garantizar calidad y cumplimiento en el desarrollo del proyecto, se identifican
restricciones y limitaciones por parte del equipo y del problema del negocio.
Razón RestricciónDatos Se extraerán datos desde el 1 de
enero de 2016 hasta el 30 de septiembre de 2017.
Herramientas Se utilizarán herramientas open source para el desarrollo de la plataforma.
Datos Se extraerán datos en el idioma
12

español.Datos Se extraerán datos única y
exclusivamente de los perfiles y páginas públicas de Facebook.
Herramientas Se utilizará R, Python para el desarrollo del módulo de analítica.
Herramientas/Datos Se utilizará una base de datos no relacional para modelar los datos extraídos de Facebook.
Herramientas Se utilizarán los siguientes sistemas operativos: Windows 10.Ubuntu 14.04.macOS Sierra.
Tabla 7 Restricciones del proyecto en términos de minería de datos.
Vocabulario
Basándose en los lineamientos, información recopilada por el grupo de trabajo y con la asistencia del
Observatorio Nacional de Transparencia y anticorrupción, fue posible identificar un vocabulario propio
del negocio en donde se describen entidades y su detalle, esto con el objetivo propio de poder diagramar y
representar por medio de un modelo de dominio el mundo de la corrupción sobre el cual el trabajo de
grado desarrollará el proyecto.
Vocabulario (Concepto) DescripciónReacción Identifica las reacciones que los diferentes tipos
de cuenta, perfil o página, de Facebook pueden dar a una publicación o comentario; Like, Love, Angry, Sad.
Opinión Representa el punto de vista propuesto por una persona sobre una publicación. En Sentinel, la opinión puede ser positiva, negativa o neutral.
Comentario Representa una cadena de caracteres la cual contiene el comentario hecho por un perfil o página.
Persona Natural Representa a aquella persona que no es una entidad.
Caso de Corrupción Representa los casos de corrupción más notables en el país; estos casos de corrupción fueron propuestos por el Observatorio Nacional de Transparencia y Anticorrupción y deben poder ser configurables.
Entidad Representa la asociación de personas de cualquier tipo; mayor nivel de abstracción.
Página Representa una posible herencia del concepto Cuenta; identifica una Fan Page en Facebook.
Publicación Representa la publicación de una página o perfil;
13

puede ser un texto, imagen, link, entre otros.Partido Representa una posible herencia del concepto
Entidad; esta identifica a los partidos políticos Pública Representa una posible categorización del
concepto Entidad; instituciones públicas o del estado.
Privada Representa una posible categorización del concepto Entidad; instituciones privadas o compañías.
Tiempo Representa el tiempo; periodos de tiempo, momentos puntuales en un año, meses, semanas, días. Este concepto se ve involucrado y relacionado en todo el modelo y es de vital importancia.
Involucrado Representa el involucrado en uno o varios casos de corrupción. Este involucrado se representa como una Entidad.
Cuenta Representa el tipo de cuenta en Facebook, puede ser Perfil o Página.
Perfil Representa una posible herencia del concepto Cuenta; identifica un perfil de una persona natural.
Tabla 8 Descripción del vocabulario del negocio.
Modelo de dominio
Una vez identificado y descrito el vocabulario se procede a realizar por medio de un diagrama de
clases el modelo de dominio, en donde se identifican los conceptos clave en el dominio de la corrupción
en el ámbito colombiano, su rol y su comportamiento entre ellos. El grupo de trabajo hace un mapeo de
los conceptos propios del negocio y los componentes de la red social Facebook que Sentinel va a utilizar.
14

Ilustración 3 Modelo de dominio.
El modelo de dominio fue revisado por la Secretaría de Transparencia, la cual recalcó que la entidad
Partido se debería considerar diferente a una entidad privada y/o pública (antes el grupo la consideraba
como una entidad pública). Esto debido a que los partidos políticos se financian de manera privada, pero
ejercen una función pública. La ilustración 3 representa el modelo de dominio final.
En el modelo de dominio se visualiza la relación entre las diferentes entidades (privadas, públicas,
partidos), personas, casos de corrupción y usuarios de Facebook, así como toda su actividad (comentarios,
publicaciones, reacciones). El tiempo es algo transversal al modelo, razón por la cual se extiende a lo
largo del modelo de dominio. Por organización del modelo no se muestran las asociaciones de Tiempo
con todas las entidades. El concepto de tiempo es de especial importancia debido a que al Observatorio le
15

interesa ver tendencias sobre las diferentes entendidas, para así ver en qué períodos hay más actividad de
los usuarios o publicaciones por parte de medios.
Gracias a la construcción del modelo de dominio, fue posible identificar con los expertos del negocio,
las preguntas a nivel de negocio que concretan el cumplimiento de los objetivos del proyecto (ver sección
1.2). Estas preguntas fueron validadas por el Observatorio Nacional de Transparencia y Anticorrupción y
el grupo de trabajo. A continuación, se listan las preguntas que cuales fueron categorizadas por concepto
del modelo de dominio:
Entidad
1. ¿Cuáles son las entidades asociadas a un caso de corrupción?2. ¿Cuántas son las entidades asociadas a un caso de corrupción? 3. ¿Cuántas entidades privadas están asociadas a un caso de corrupción? 4. ¿Cuáles entidades privadas están asociadas a un caso de corrupción?5. ¿Cuántas entidades públicas están asociadas a un caso de corrupción?6. ¿Cuáles entidades públicas están asociadas a un caso de corrupción?7. ¿Cuál es el porcentaje por reacción de una publicación hecha por un tipo de entidad
Privada/Publica?8. ¿Qué tipo de entidades publican más sobre casos de corrupción?9. ¿Cuál es el sector (privado-publico) más involucrado en casos de corrupción? 10. ¿Cuál es la entidad con más seguidores?11. ¿Cuál es la entidad que más ha tenido actividad (Publicaciones, opinión) durante un periodo de
tiempo sobre un caso de corrupción?12. ¿Cuál es la entidad más ha se ha visto involucrada en publicaciones durante un periodo de
tiempo? 13. ¿Cuál es la entidad más ha se ha visto involucrada en publicaciones respecto a un caso de
corrupción? 14. ¿Existen relaciones entre los dos sectores respecto a un caso de corrupción?15. ¿Es posible detectar el sesgo de los medios de comunicación respecto a los casos de
corrupción? 16. ¿Es posible detectar el sesgo de los medios de comunicación respecto a las publicaciones que
hacen?
Tabla 9 Preguntas relacionadas con entidad.
Caso de corrupción
1. ¿Cuál es el caso de corrupción que recibe más reacciones (like-dislike) y opiniones?2. ¿Dado un caso de corrupción, es posible comparar dos líderes de opinión basándose en like-
dislike?3. ¿Cuál es el caso de corrupción que más ha tenido actividad (Publicaciones, opinión) durante un
periodo de tiempo? 4. ¿Cuál caso de corrupción genera el mayor malestar (dislike) en los usuarios?5. ¿Cuál es el número promedio de involucrados en un caso de corrupción?6. ¿Cuál es el número promedio de publicaciones respecto a un caso de corrupción en particular?7. ¿Cuánto tiempo toma un caso de corrupción en ser 'olvidado' por los medios de comunicación?8. ¿Cuánto tiempo toma un caso de corrupción en ser viral en un periodo de tiempo?
16
9. ¿Cuántas veces es mencionado un caso de corrupción en un periodo de tiempo?10. ¿Es posible comparar los casos de corrupción? (Basándose en criterios; mas mencionados, más
involucrados, más like-dislike, entre otros.) 11. ¿Es posible comparar los casos de corrupción dado un periodo de tiempo? (Basándose en
criterios; mas mencionados, más involucrados, mas like-dislike, entre otros.)12. ¿Qué palabras se suelen mencionar cuando se habla de casos de corrupción? (Asociación de
palabras)
Tabla 10 Preguntas relacionadas con casos de corrupción.
Personas naturales
1. ¿Cuáles son los líderes de opinión que más comentan sobre corrupción?2. ¿Cuántas reacciones positivas y negativas tienen los usuarios a las publicaciones de los líderes?3. ¿Cuáles líderes de opinión están más involucrados con corrupción?4. ¿En las publicaciones sobre corrupción los comentarios hechos por los usuarios, cuántas
líderes de opinión son nombrados con más frecuencia en esos comentarios? 5. ¿Cuánto tiempo nombran a un líder de opinión política después de ser involucrado en un caso
de corrupción en comentarios y publicaciones?6. ¿Qué tienen en común los comentarios hechos por los usuarios con más likes?7. ¿Cuál es la reacción de los líderes de opinión ante noticias de corrupción?8. ¿Cuáles líderes políticos están nombrados en organizaciones involucradas en corrupción?9. ¿Cuáles líderes están más nombrados en los comentarios sobre noticias de corrupción? 10. ¿Cuáles son los sentimientos de los usuarios sobre los líderes políticos?
Tabla 11 Preguntas relacionadas con personas naturales.
Publicación
1. ¿Cuáles páginas publican más sobre corrupción?2. ¿Cuál es la opinión de las páginas (positivo/negativo/neutral) acerca de los líderes políticos y
entidades?3. ¿Cuáles son las páginas cuyas publicaciones sobre un líder político o entidad se comparten
más?4. ¿Cuáles son las páginas cuyas publicaciones de corrupción se comparten más?5. ¿Cuáles publicaciones de corrupción (ejemplo: Odebrecht, Reficar, etc) generan más
reacciones (like/angry/sad/etc)? 6. ¿Cuáles publicaciones de corrupción generan más comentarios? 7. ¿Cuáles son los casos de corrupción que más se publican? 8. Comportamiento de publicación de casos de corrupción a través del tiempo 9. Del total de publicaciones de una página, ¿cuál es la proporción de noticias de corrupción? 10. ¿Cuántas publicaciones de corrupción son del sector privado/público? 11. ¿Qué palabras se suelen mencionar cuando se habla de corrupción? (Asociación de palabras) 12. ¿Qué región del país está más involucrada en noticias de corrupción? 13. ¿De dónde son los corruptos que se mencionan en noticias?
Tabla 12 Preguntas relacionadas a publicaciones.
17

Comentarios
1. ¿Los comentarios sobre corrupción son un reflejo de la realidad (comparar con encuestas)? 2. ¿Cuáles son las instituciones del Estado más atacadas por corrupción en los comentarios? 3. ¿Cuál es la opinión (positiva/negativa/neutral) de los usuarios sobre líderes políticos y
entidades?
Tabla 13 Preguntas relacionadas con comentarios.
Involucrados
1. ¿Cuáles son las personas o entidades más involucradas en casos de corrupción? 2. ¿Del total de entidades involucradas en un caso de corrupción, cuántas son Entidades públicas
y privadas? 3. ¿Del total de entidades involucradas en un caso de corrupción, cuántas son entidades públicas
reguladoras? 4. ¿Del total de entidades involucradas en un caso de corrupción, cuántas son entidades públicas,
partidos? 5. ¿Del total de entidades involucradas en un caso de corrupción, cuántas son entidades privadas?
Tabla 14 Preguntas relacionadas con involucrados.
Este conjunto de preguntas permitió identificar el tipo de resultado esperado y, por lo tanto, qué
técnica debía ser incorporada al modelo global de analítica. La trazabilidad entre pregunta, resultado y
componente del modelo de analítica se encuentran en el anexo "Trazabilidad.xlsx".
1.4 Determinar los objetivos de mineríaConsiderando los objetivos de negocio se plantearon cuatro objetivos de minería:
Describir el nivel de agrado y desagrado de los usuarios en Facebook por medio de algoritmos de
análisis de sentimientos.
Hacer un monitoreo de los casos de corrupción más relevantes en Colombia por medio sus
publicaciones a lo largo de un periodo de tiempo definido.
Utilizar algoritmos descriptivos (correlación) para encontrar los temas más relacionados a la
corrupción.
Desarrollar un componente de analítica de datos, compuesto por diferentes módulos (algoritmos)
enfocados a aplicar las siguientes técnicas:
o Análisis de sentimientos
o Asociación de palabras
o Funciones agregadas
o Funciones compuestas
18

Desarrollar un componente que permita visualizar e interpretar los resultados obtenidos al aplicar
las técnicas de analítica seleccionadas.
1.5 Criterio de éxito de mineríaSe establecen dos criterios de éxito para considerar que el proyecto Sentinel fue satisfactorio:
1. Se logran responder las preguntas con prioridad 2 y 3 (ver SRS).
3 es la prioridad más alta, y esta prioridad la tienen las preguntas que más les interesa conocer al
Observatorio de Transparencia y Anticorrupción, por lo cual son las primeras en desarrollarse en
los componentes de analítica y visualización.
2. El sistema se valida con las personas que han apoyado al grupo de trabajo en la elaboración del
proyecto. Esta validación se hace con la encuesta TAM. El proyecto se considera exitoso si se
obtiene un promedio mínimo de 3.0 en cada eje evaluado por la encuesta TAM.
2. Entendimiento de datos
2.1 Recopilar los datos iniciales Los datos serán extraídos de la red social Facebook y para esto es necesario llevar a cabo una serie de
procesos para extraer dichos datos.
Para llevar a cabo la extracción es necesario primero entender qué tipo de datos se necesitan, su
relación y naturaleza dentro la red social Facebook.
Inicialmente se requieren de unos pre-requisitos antes de llevar a cabo el proceso de extracción:
1. Creación de una aplicación en Facebook Developer https://developers.facebook.com/
2. Solicitar un Access Token Tool para poder autenticarse con Facebook y validar la identidad.
Una vez cumplidos los requisitos previamente mencionados, se procede entonces a utilizar la
herramienta de extracción seleccionada. Para el caso del proyecto, el grupo de trabajo cuenta con un
código desarrollado en Python que por medio de un protocolo HTTPS/REST consume la API de
Facebook, conocida como Graph API, para obtener estados y publicaciones junto con otro conjunto de
atributos descritos más adelante.
Todos los datos serán extraídos únicamente de Facebook y por esta razón no es necesario realizar
ninguna integración adicional con otros datos u otros recursos. Estos datos son extraídos en formato
JSON (Facebook, 2017) y son posteriormente almacenados en una base de datos no relacional, conocida
como MongoDB (MongoDB, 2017), en donde los documentos, conocidos como datos en formato JSON,
son ubicados en grandes colecciones.
19

A continuación, se describen los elementos generales de Facebook, con ánimos de entender la anatomía
de la red social y su manera de representar los datos que la componen.
Elemento DescripciónFan Page Página pública de Facebook que ha sido diseñada
con ánimos de compartir información sobre un interés mutuo y captan la atención de varios usuarios (Comunitarios, 2014).
Comentario Un comentario es una apreciación sobre cualquier tema puesto en análisis (Comunitarios, 2014).
Publicación Es la idea de hacer que una información se conozca y salga del ámbito de lo privado a lo público (Comunitarios, 2014).
Reacción Es la respuesta a una publicación; se conocen como emociones: positiva, negativa, humor, furor (Comunitarios, 2014).
Like/Dislike Reacción positiva o negativa de publicaciones y/o comentarios (Comunitarios, 2014).
Tabla 15 Descripción de elementos de Facebook.
Por otro lado, el sistema debe tener la capacidad de extraer las publicaciones y comentarios que hablen
de corrupción, por esta razón el grupo de trabajo utilizará expresiones regulares para poder identificar las
publicaciones adecuadas.
Para ver la base de conocimiento, ir a: https://github.com/sentinelanalytics/analytics/tree/master/base-
conocimiento
2.2 Descripción inicial de datos El sistema extraerá publicaciones y comentarios de los medios de comunicación, líderes de opinión y
demás figuras cuya presencia en la red social sea fuerte y se necesite monitorear. Estas entidades fueron
provistas por el Observatorio Nacional de Transparencia y Anticorrupción. Por esta razón, y con ánimos
de garantizar calidad, precisión y exactitud en los resultados, se extraerán los datos hasta el 28 de octubre
de 2017.
Extrayendo publicaciones y comentarios de los 24 medios de comunicación provistos por el
Observatorio y los 8 líderes de opinión que tienen página de Facebook, desde el 1 de enero de 2016 hasta
el 28 de octubre de 2017, el espacio de almacenamiento que ocuparon los datos fue de 14.72 GB. Con
base en esta información, se estima que mensualmente se extraen alrededor de 670 MB de publicaciones
y comentarios, y al año alrededor de unos 8 GB.
20

Para que los datos tengan sentido y sean apropiados para el desarrollo del proyecto, se desea entonces
solo extraer los siguientes elementos de Facebook. A continuación, se muestran en la figura los elementos
necesarios y los atributos que lo componen identificando su nombre y una descripción de cada atributo:
1. Posts
a. _id: representa el ID del post.
b. created_time: representa la fecha de creación de la publicación.
c. message: representa la cadena de caracteres de la publicación.
d. name: representa el nombre de la publicación.
e. description: representa una descripción de la publicación.
f. shares: representa la cantidad de veces que una publicación fue compartida.
g. link: representa la URL de la publicación (ej: URL que comparte un medio de una
noticia).
h. reactions:
i. sad: representa la cantidad de reacciones sad que recibió la publicación.
ii. haha: representa la cantidad de reacciones haha que recibió la publicación.
iii. love: representa la cantidad de reacciones love que recibió la publicación.
iv. like: representa la cantidad de reacciones like que recibió la publicación.
v. wow: representa la cantidad de reacciones wow que recibió la publicación.
vi. angry: representa la cantidad de reacciones angry que recibió la publicación.
2. Comments
a. _id: representa el ID del comentario.
b. created_time: representa la fecha de creación del comentario.
21
Ilustración 4 Modelo de datos

c. message: representa la cadena de caracteres del mensaje.
d. like_count: representa la cantidad de veces que los usuarios le dieron like a ese
comentario.
Como se puede detallar en el diagrama, todos los elementos tienen un identificador único denominado
"_id", junto con una fecha y los atributos correspondientes a cada elemento.
Debido a que la diferencia entre "message", "name" y "description" de una publicación es difícil de
comprender, a continuación, se muestra una publicación de Facebook y se identifican sus diferentes
partes:
Ilustración 5 Publicación de Facebook.
Vale la pena mencionar que no todas las publicaciones cuentan con estas tres partes. Es decir, no son
obligatorias.
Atributos numéricos
La tabla 16 muestra los atributos numéricos de características de publicaciones
Atributo Mínimo 1er cuartil
Mediana Media 3er cuartil
Máximo Desv. Estánd.
Shares 0 1 6 201.7 34 462640 3400.667Sad 0 0 0 22.18 2 34642 244.037
22

Wow 0 0 0 15.29 4 16902 103.146Love 0 0 1 24.91 5 17263 193.894Like 0 9 43 349.2 184 118635 1841.25Angry 0 0 0 33.2 4 39719 270.592Haha 0 0 0 24.94 3 22472 255.841like_count 0 0 0 1.521 1 9798 18.866
Tabla 16 Publicación de Facebook.
Atributos nominales
Gran parte de los datos que se extrajeron son texto. Esto hace el análisis más complejo y lento debido a
su alta dimensionalidad. En esta descripción inicial de datos, se hizo un conteo de palabras, lo cual nos da
indicios sobre cuáles son las palabras más mencionadas en noticias/comentarios, además de guiarnos en
cuanto a la preparación que se le debe hacer al texto. Por ejemplo: aparecieron signos de puntuación, stop
words1, caracteres ilegibles, URLs; los cuales se deben remover en la preparación de datos para aplicar los
algoritmos.
Atributo Palabras frecuentes Signos de puntuación frecuentes
posts.message http (590)https (494)goo.gl (494)bit.ly (417)colombia (267)años (250)
. (4425), (3378)/ (3328): (1745)" (696)
posts.name photos (219)timeline (217)colombia (161)cali (148)bogotá (106)méxico (101)
, (686). (510)" (425)' (368): (351)
posts.description colombia (20)cali (15)entérese (12)personas (10)ser (9)país (9)
. (246), (187): (37)" (34)/ (27)
comments.message q (57444)si (55094)dios (32115)colombia (24532)mas (23296)ser (18984)
. (574414), (263102)! (126617)? (76714)" (26453)
Tabla 17 Atributos nominales.
1 stop words o palabras vacías son todas aquellas palabras que carecen de un significado por si solas (Wilbur & Sirotkin, 1992).
23

2.3 Exploración inicial de datos En la exploración inicial de los datos (realizada en R), se generaron varios gráficos para mostrar
propiedades generales de los atributos numéricos (ej: varianza, asimetría, etc.). A continuación, se
muestran algunas gráficas que permiten describir los datos:
Ilustración 6 Cantidad de publicaciones que comparten los usuarios por página de noticias
Para cada medio de comunicación (por legibilidad se muestran cuatro medios), se muestra la cantidad
de veces que se comparten sus publicaciones. Se nota un alto número de publicaciones outliers, debido a
que se encuentra por fuera de los "bigotes" de las cajas.
El tamaño pequeño de las cajas indica una baja varianza, existen muchos puntos cercanos a 0. Esto nos
dice que, en general, los usuarios comparten poco las publicaciones de una página de noticias.
A continuación, se muestran boxplots para cada tipo de reacción. Cada punto es la cantidad de
reacciones que recibió una publicación de cada medio.
24

Ilustración 7 Reacciones 'wow'
Ilustración 8 Reacciones 'sad'
25

Ilustración 9 Reacciones 'love'
Ilustración 10 Reacciones 'haha'
26

Ilustración 11 Reacciones 'angry'
Ilustración 12 Reacciones 'like'
27

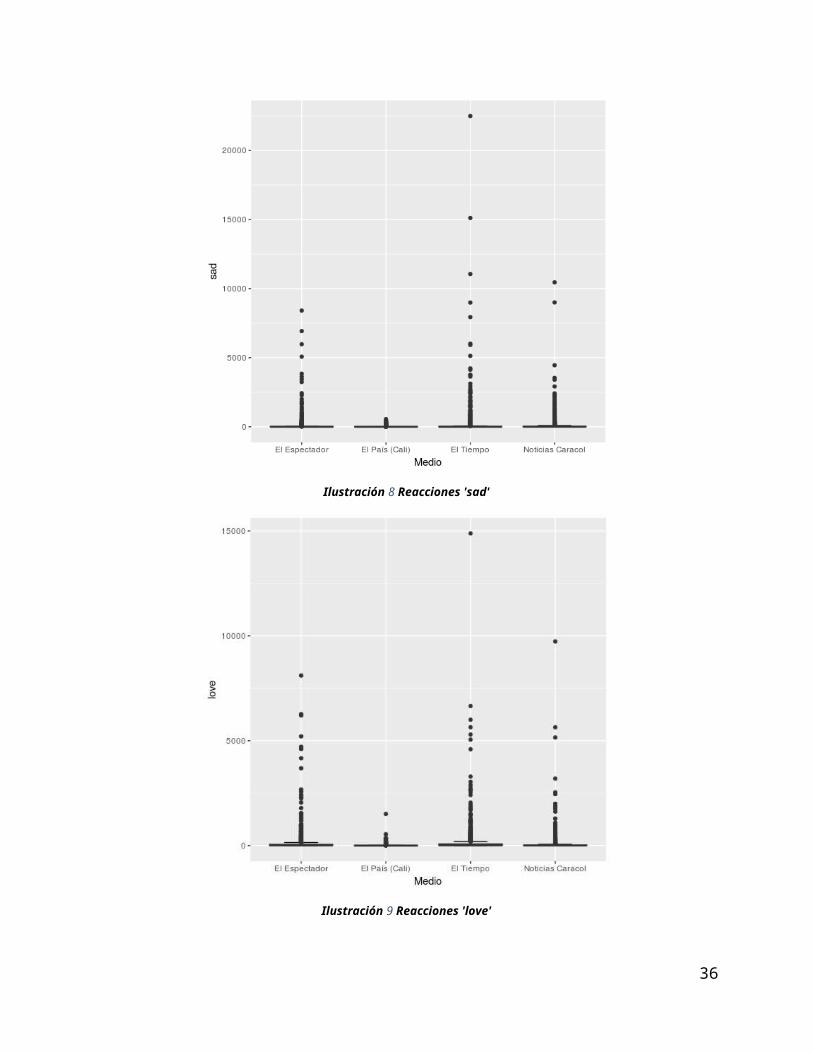
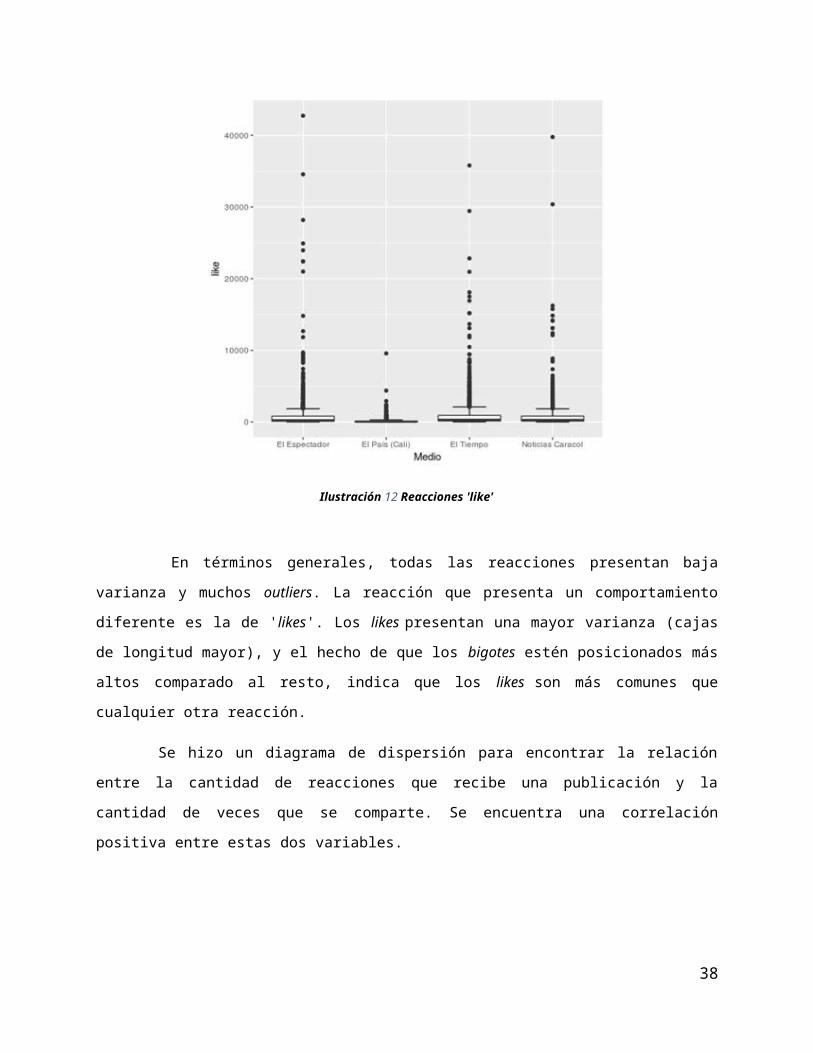
En términos generales, todas las reacciones presentan baja varianza y muchos outliers. La reacción
que presenta un comportamiento diferente es la de 'likes'. Los likes presentan una mayor varianza (cajas
de longitud mayor), y el hecho de que los bigotes estén posicionados más altos comparado al resto, indica
que los likes son más comunes que cualquier otra reacción.
Se hizo un diagrama de dispersión para encontrar la relación entre la cantidad de reacciones que recibe
una publicación y la cantidad de veces que se comparte. Se encuentra una correlación positiva entre estas
dos variables.
Ilustración 13 Reacciones vs shares
2.4 Verificar calidad de los datos En cuanto a la calidad de los datos se pueden resaltar los siguientes elementos:
1. Completitud de los datos: Al momento de revisar los datos y su completitud no se encontraron
errores o elementos faltantes, debido a que desde el inicio de la extracción de los datos ningún
atributo está incompleto.
28

2. Errores en los datos: Los datos no contienen errores, sin embargo, cada algoritmo del
componente de analítica cuenta con su propio procesamiento de datos debido a que cada
algoritmo requiere una preparación faltante
3. Valores faltantes: Ningún atributo cuenta con valores faltantes, pero es necesario aclarar que
algunos campos pueden estar vacíos, sin embargo, no se tomarán acciones debido a que sería
manipular los datos reales.
3. Preparación de datos
3.1 Selección de datos Se mantienen todas las variables que contengan texto, debido a que es la fuente principal de datos para
el análisis. En todos los análisis que se van a realizar, el atributo created_time es necesario, debido a que,
en la mayoría de casos, la visualización se realiza dentro de un rango de tiempo específico. Por ejemplo:
el usuario puede ver los sentimientos hacia un líder político a través del tiempo.
Se excluyen los siguientes atributos para aplicar las técnicas seleccionadas debido a que no aportan
ningún valor:
_id: no tiene sentido aplicar análisis sobre el _id de un comentario o una publicación
link: no se va a analizar el texto de las URLs
3.2 Limpieza de datos La limpieza y normalización de datos se divide en dos partes: básica y avanzada. Se tomó como base
la preparación y limpieza de texto detallada en el artículo "A Sentiment Analysis System of Spanish
Tweets and Its Application in Colombia 2014 Presidential Election" (Cerón-Guzmán & León-Guzmán,
2016).
Pre procesamiento básico:
Eliminación de direcciones URL.
Los caracteres desconocidos se asignan a su variante ASCII más cercana, utilizando el módulo
Python Unidecode.
Se remueven los stopwords utilizando el módulo Python NLTK.
Eliminación de signos de puntuación
Eliminación de acentos (tildes, virgulillas, diéresis, etc.)
Preprocesamiento avanzado:
29

Se hace stemming utilizando el módulo Python NLTK. Específicamente se utiliza el Snowball
Stemmer para el idioma español.
3.3 Construcción de datos Se genera un nuevo atributo llamado "stemmed" para la colección de "comments" y "posts". En
ese atributo guarda la versión stemmed de los mensajes (ya sean comentarios o publicaciones)
Esto evita recalcular de manera innecesaria cada algoritmo.
Se genera un nuevo atributo llamado "whole_sentence", donde se guarda la versión reprocesado
del texto (sin stop words, acentos, signos de puntuación, etc.), pero sin aplicar el stemming. En
este atributo, se concatenan los atributos originales "message", "name" y "description" (de las
publicaciones), para que quede todo en un solo atributo. El atributo "whole_sentence" se utiliza
en el algoritmo de asociación de palabras.
3.4 Integración de datos
No se realiza ninguna integración de datos Debido a que la fuente de información es
Facebook.
3.5 Adecuación de datos
Las modificaciones sintácticas que se le hacen a los datos se describen con mayor detalle en
la Sección 3.2 Limpieza de datos.
30

4. Modelo Basándose en el modelo de dominio, las preguntas generadas en la fase "Entendimiento del negocio" y
la disponibilidad de datos se procede a generar el modelo de analítica. A continuación, por medio de un
diagrama de clases se visualizan las técnicas y los algoritmos a utilizar.
Ilustración 14 Modelo de analítica
4.1 Seleccionar técnicas de minería A continuación, se presenta la salida de los algoritmos aplicados en términos de negocio, mostrando
su descripción, flujo principal y salida de manera gráfica:
4.1.1 Técnicas Predictivas
4.1.1.1 Análisis de sentimiento
Objetivo: Determinar de los comentarios sobre líderes de opinión, partidos políticos e
instituciones a través del tiempo
Algoritmo núcleo: Bag-of-words
Entrada: cadena de caracteres
Salida del algoritmo: -1 (sentimiento negativo), 0 (sentimiento neutral), 1 (sentimiento positivo)
31

Pese a que la salida del algoritmo de bag-of-words es negativo, neutral o positivo; en Sentinel se
muestran los resultados como un gráfico de los sentimientos a través del tiempo, ya sean sentimientos de
un líder de opinión, un partido político o una institución. A continuación, se muestra una captura de
pantalla del resultado de análisis de sentimiento:
Ilustración 15 visualización análisis de sentimientos
En rojo se muestran los sentimientos negativos, en verde los positivos y en azul los neutrales. Para este
caso, se desactivó la línea de tiempo de sentimientos neutrales.
Se utiliza un diccionario político de sentimientos creado en un trabajo de grado anterior (Caicedo,
Carrillo, Forero, & Ureña, 2017), debido a que un sistema de análisis de sentimiento es altamente
sensible al dominio en el que se utiliza, y, por lo tanto, se pueden obtener resultados pobres si se utiliza un
diccionario de sentimientos de un dominio diferente para el cual fue creado (Cerón-Guzmán & León-
Guzmán, 2016).
4.1.2 Técnicas Descriptivas
4.1.2.1 Sesgo
Objetivo: medir la inclinación de los medios en base a la cantidad de publicaciones que hacen
respecto a casos de corrupción, líderes de opinión y entidades.
Algoritmo núcleo: rango intercuartil
Entrada: cantidad de publicaciones que han hecho todos los medios sobre un caso de corrupción
o alguna una entidad particular, ya sea líder de opinión, partido político o institución. Esta entrada
se espera que sea un arreglo, donde cada elemento contiene un medio y la cantidad de
publicaciones que hizo ese medio sobre la entidad específica.
Salida: valores atípicos (outliers) identificados, ya sea porque publican considerablemente más
respecto a una entidad específica comparado al resto de medios o porque publican menos.
32

Ilustración 16 comparación de los medios
En Sentinel, al comparar los medios, se muestra una descripción si pública más o menos sobre
corrupción (utilizando las palabras otorgadas por el Observatorio), los casos de corrupción concretos,
líderes de opinión, partidos políticos e instituciones. En la imagen anterior el usuario está comparando
"Noticias Caracol" con "El País (Cali)". Se observa que El País publica considerablemente más sobre el
caso de Odebrecht comparado a los demás medios, mientras que Noticias Caracol pública en una cantidad
considerada "normal" (no es un atípico).
Existe la opción de ver todos los medios al tiempo, como se muestra a continuación:
33

Ilustración 17 Visualización de todos los medios
Aparte de mostrar la cantidad de publicaciones sobre una entidad, se muestra también la cantidad de
noticias de corrupción que mencionan a esa entidad (en la imagen son las barras rojas), igualmente
detectando datos atípicos.
4.1.2.2 Asociación de palabras
Objetivo: encontrar los temas más relacionados a las diferentes entidades y líderes de opinión
Algoritmo núcleo: matriz de correlación.
Proceso:
o Se construye una matriz de documento-palabra (Document-Feature Matrix).
o En la matriz documento-palabra, en las columnas se tienen todas las palabras (sin stop
words ni signos de puntuación), y en las filas se tienen todos los documentos (ej: cada
publicación es un documento, igual con los comentarios).
o Se normaliza la matriz basado en TF-IDF, de tal manera que cada celda de la matriz tiene
un valor entre 0 y 1 (según su peso TF-IDF).
Entrada: publicaciones y comentarios, además de las palabras que son de interés para el
Observatorio, para poder encontrar la asociación de esas palabras claves dentro de las
publicaciones/comentarios. Estas palabras son: los líderes de opinión, las instituciones, los casos
de corrupción, los partidos políticos y las palabras de corrupción (diccionario de corrupción).
Salida: para cada palabra clave, se obtiene una lista de palabras asociadas, con un valor de 0 (no
hay ninguna asociación) a un valor de 1 (asociación muy fuerte).
34

El algoritmo de asociación de palabras se aplica a dos tipos de documentos:
1. Publicaciones: se busca dentro de las publicaciones de los medios, las palabras claves y su
asociación. Esto con fines de determinar qué dicen los medios al respecto de una entidad
específica.
2. Comentarios: se busca dentro de los comentarios de los usuarios, las palabras claves y su
asociación. Se aplica sobre comentarios para saber cuáles son las palabras que más asocian los
usuarios a entidades.
Se aplica el algoritmo tanto a publicaciones como a comentarios de manera separada, debido a que al
Observatorio le interesa saber qué opinan los usuarios las entidades y contrastarlo con lo que reflejan los
medios.
En Sentinel, se toma la salida del algoritmo de asociación y se construye un grafo para visualizar la
asociación de las palabras encontradas. A continuación, se muestra el grafo:
Ilustración 18 grafo
En este caso, se muestran las asociaciones para los comentarios de los usuarios, en un mes específico.
Los nodos que representan las palabras claves tienen un color específico, basado en la categorización que
hizo el Observatorio. La codificación de colores para palabras claves es la siguiente:
Rojo: palabras de corrupción
Verde: líderes de opinión
Amarillo: partidos políticos
Rosado: casos de corrupción
35
Morado: Instituciones
En azul se muestran las palabras asociadas a las palabras claves.
4.1.2.3 Funciones agregadas
Objetivo: realizar cálculos sobre los datos extraídos para realizar mediciones básicas.
Algoritmos núcleo: Suma, Resta, Min, Max, Promedio
Entradas: conjunto de datos a ser resumido. En el caso de Sentinel, estos datos pueden ser:
publicaciones, comentarios y reacciones.
Salidas del algoritmo: un valor que resuma los datos de entrada. Este valor puede ser la suma,
resta, promedio, etc.; dependiendo de lo que se intenta visualizar.
Salidas en el componente de visualización: gráficos de barras, líneas de tiempo.
Las funciones agregadas son todas aquellas que toman un grupo de datos y retornan un solo valor,
efectivamente resumiendo los datos (Oracle, s/f). Para el caso de Sentinel, estas funciones son sumas,
promedios, min, max, etc. En Sentinel, las funciones agregadas se utilizan para mostrar tendencias sobre
las diferentes entidades que se están monitoreando (ej: cantidad de publicaciones sobre un partido político
a través del tiempo).
A continuación, se muestran algunas salidas de estas funciones agregadas:
Ilustración 19 Función agregada – Cantidad de publicaciones que realiza un medio sobre un caso
36

Ilustración 20 Función agregada – Cantidad de publicaciones que realiza un medio sobre un partido político
Ilustración 21 Función agregada – Reacciones en noticias sobre un caso de corrupción
4.2 Definir el diseño de pruebas para el modelo Se definen los mecanismos para probar la calidad y validez de los datos. Se busca apoyar esta tarea
con el Observatorio Nacional de Transparencia y Anticorrupción junto con medidas de error.
Técnicas Predictivas (Análisis de sentimientos)
Para validar el algoritmo de análisis de sentimientos, se hace un muestreo aleatorio de los
comentarios de usuarios y se clasificará su polaridad manualmente por los integrantes del grupo.
Se comparan los resultados esperados (comentarios clasificados por los integrantes) con los
resultados reales del algoritmo de análisis de sentimientos.
Basado en los resultados del algoritmo y la clasificación manual, se genera una matriz de
confusión, con la cual se procede a sacar las medidas de precisión, exhaustividad y exactitud.
37
Técnicas Descriptivas
Se realiza un procedimiento parecido para las técnicas descriptivas. Se toma un muestreo
aleatorio de comentarios y publicaciones en Facebook utilizando las expresiones regulares que
creó el grupo de trabajo que contienen las entidades y palabras de corrupción.
Manualmente, se determina a cuál entidad y palabra de corrupción están haciendo referencia las
publicaciones y comentarios.
Se aplican los algoritmos descriptivos desarrollados sobre la muestra tomada y se comparan los
resultados esperados contra los resultados reales del algoritmo.
Se evalúa qué tan precisa está siendo la extracción de comentarios y publicaciones sobre
entidades y corrupción utilizando las expresiones regulares creadas por el grupo.
4.3 Construir el modelo
4.3.1 Análisis de sentimientos
Esta técnica está desarrollada en Python.
Parámetros
Diccionario: diccionario político elaborado en el trabajo de grado dirigido por el profesor Jorge
Alvarado.
Entidades: líderes de opinión, partidos político e instituciones de las cuales se quieren saber los
sentimientos.
Comentarios: los comentarios a ser analizados con su preparación respectiva (eliminación de stop
words, acentos, signos de puntuación, URLs, etc.)
Resultado de la técnica
Ilustración 22 Salida de algoritmo de análisis de sentimientos
38

En la ilustración anterior se muestra la salida del algoritmo de análisis de sentimientos para la líder de
opinión Claudia López. Se observa un incremento en la popularidad a lo largo del tiempo, probablemente
debido a que se acercan las elecciones presidenciales. En términos generales se observan más comentarios
positivos que negativos para Claudia López, aunque se debe tener en cuenta la exactitud, exhaustividad y
precisión del algoritmo, que se pueden ver en la sección 4.4.1 Evaluación de análisis de sentimiento.
A continuación, se muestra el análisis de sentimientos para Álvaro Uribe Vélez, ex-presidente y actual
senador de la República de Colombia:
Ilustración 23 Análisis de sentimientos para Álvaro Uribe Vélez
Se observa un pico en la cantidad de comentarios sobre Álvaro Uribe en noviembre de 2016,
probablemente debido al proceso de paz. Nuevamente, este tipo de interpretaciones se dejan mejor para la
Secretaría de Transparencia.
Ilustración 24 Noticia sobre Álvaro Uribe Vélez en noviembre 16 del 2016, El Tiempo
Los resultados para los demás líderes de opinión se pueden observar en la página de Sentinel.
39

4.3.2 Sesgo
Esta técnica está desarrollada en Python.
Parámetros
Medios y líderes de opinión: páginas de Facebook de los medios y líderes de opinión de los
cuales se quiere saber el sesgo (publican más o menos acerca de una entidad o caso de
corrupción).
Expresiones regulares (entidades y palabras/casos de corrupción) para identificar las
publicaciones realizadas por los medios y líderes de opinión.
Publicaciones realizadas por los medios y líderes de opinión.
Resultado de la técnica
En la siguiente imagen se observa el resultado del algoritmo de sesgo, cuando el usuario compara dos
medios: "Noticias Caracol" y "El País (Cali)". Noticias Caracol es el medio con más publicaciones que
incluyen las palabras claves de corrupción, con un total de 3.515 publicaciones, comparado a las 748
publicaciones realizadas por El País. Por ende, el algoritmo de sesgo detecta que la cantidad de
publicaciones que realiza Noticias Caracol es atípica comparado a la cantidad de publicaciones que hacen
el resto de medios.
Ilustración 25 Visualización del algoritmo de sesgo
El mismo algoritmo para determinar el sesgo de los medios, se utiliza para identificar cuáles líderes de
opinión publican más o menos sobre corrupción (incluyendo casos de corrupción) en su página de
Facebook. Por ejemplo, en la siguiente imagen se puede observar que Claudia López publica sobre
corrupción considerablemente más comparado al resto de líderes de opinión:
40

Ilustración 26 Algoritmo de sesgo para publicaciones sobre corrupción de un líder de opinión
Es bien sabido que Claudia López habla bastante sobre la lucha contra la corrupción, por lo cual no es extraño
encontrar que publique más sobre corrupción comparado al resto de líderes de opinión. Esto se ve evidenciado
también por los resultados de las funciones agregadas (sección 4.3.4), en donde se crea una nube de palabras con las
publicaciones que realizan los líderes de opinión en su página de Facebook, y deja en evidencia que Claudia López
es una de las personas que más habla sobre corrupción.
4.3.3 Asociación de palabras
Esta técnica está desarrollada en R.
Parámetros
Expresiones regulares para identificar las entidades y palabras/casos de corrupción de los cuales
se quieren encontrar las asociaciones,
Nivel de asociación mínimo: mayor a 0
En este algoritmo se buscan las 5 palabras con una correlación más fuerte a las palabras de interés
(entidades, casos de corrupción, etc.) con fines de no saturar el grafo con tantos nodos y que se garantice
una velocidad de carga aceptable en equipos que no tengan alto nivel de procesamiento o memoria.
Resultado de la técnica
La técnica de asociación de palabras se aplica a publicaciones con fines de saber en qué tipo de
noticias se ha visto más involucrado recientemente un líder de opinión o cualquier otro tipo de entidad.
De igual manera, se busca qué temas o qué tipo de entidades han estado más asociadas a noticias de
corrupción, al buscar asociaciones con las palabras de corrupción que provisionó el Observatorio. En la
41

siguiente imagen, se muestra el resultado de aplicar esta técnica en publicaciones de los 24 medios de
comunicación provistos por el Observatorio. Este grafo se construye a partir de un resumen mensual de
publicaciones. Por lo tanto, al momento de realizar este informe, se cuenta con 22 grafos para
publicaciones (desde enero de 2016 hasta octubre de 2017)
Ilustración 27 Grafo (asociación de palabras) para publicaciones
En la imagen anterior, aparte de las asociaciones obvias, como, por ejemplo, "Partido Verde" está
asociado con "Claudia López", también se pueden descubrir otras asociaciones interesantes. Por ejemplo,
la palabra "SIC" (Superintendencia de Industria y Comercio) está asociada con "cementos" y
"cartelizaron", por lo cual el grupo de trabajo buscó noticias que incluyan estas dos palabras en Google, y
se encontró que la Superintendencia de Industria y Comercio está adelantando investigaciones contra
Cementos Argos por "acusaciones de prácticas restrictivas de la competencia desde agosto del 2013"
(Dinero, 2017).
La técnica de asociación de palabras se aplica también a los comentarios de usuarios, para conocer
cuáles temas/palabras los usuarios asocian más con las entidades o palabras de corrupción. Esta es otra
manera de conocer los sentimientos de los usuarios, debido a que permite identificar si algún líder de
opinión, por ejemplo, tiene asociadas más palabras negativas o positivas según los comentarios de los
usuarios.
42

Ilustración 28 Grafo (asociación de palabras) para comentarios
En la imagen anterior, se observa el resultado del algoritmo de asociación de palabras para
comentarios de usuarios, esta imagen deja en evidencia que los usuarios asocian la palabra "serrucho" con
"congreso", lo cual da un indicio de que los usuarios hablan negativamente acerca del congreso. También
se observa, que, en el mes de octubre de 2017, los comentarios que mencionan a "Saludcoop", también
mencionan la palabra "abuso" y "burla", nuevamente reflejando una percepción negativa sobre la
institución.
Vale la pena aclarar que esta técnica -y las demás- no permiten descubrir a personas o entidades
corruptas.
Cabe mencionar que, gracias a este algoritmo, se identificaron nuevas palabras relacionadas a
corrupción, que posteriormente se agregaron a la base de conocimiento. Por ejemplo: las palabras
"coimas" y "peculado", no estaban dentro de las palabras iniciales de corrupción provistas por la
Secretaría de Transparencia. Este algoritmo permite la realimentación del sistema.
4.3.4 Funciones agregadas
Esta técnica está desarrollada en Python.
Parámetros
Expresiones regulares para identificar publicaciones y comentarios con las palabras de interés.
Resultado de la técnica
43

Las funciones agregadas se aplican tanto a comentarios como a publicaciones de medios y líderes de
opinión. Se utilizan para contar el número de reacciones que recibió una entidad o un caso de corrupción
en un período de tiempo, o para identificar la cantidad de reacciones que ha recibido un líder de opinión
en las publicaciones que realiza. También se utilizan para determinar cuáles son los comentarios más
populares sobre un líder de opinión (utilizando una función max). A continuación, se muestran varios
usos de las funciones agregadas en Sentinel.
Ilustración 29 Función agregada - Reacciones en noticias sobre un caso de corrupción
Ilustración 30 Función agregada - número total de reacciones que han hecho en la página de un líder de opinión
44
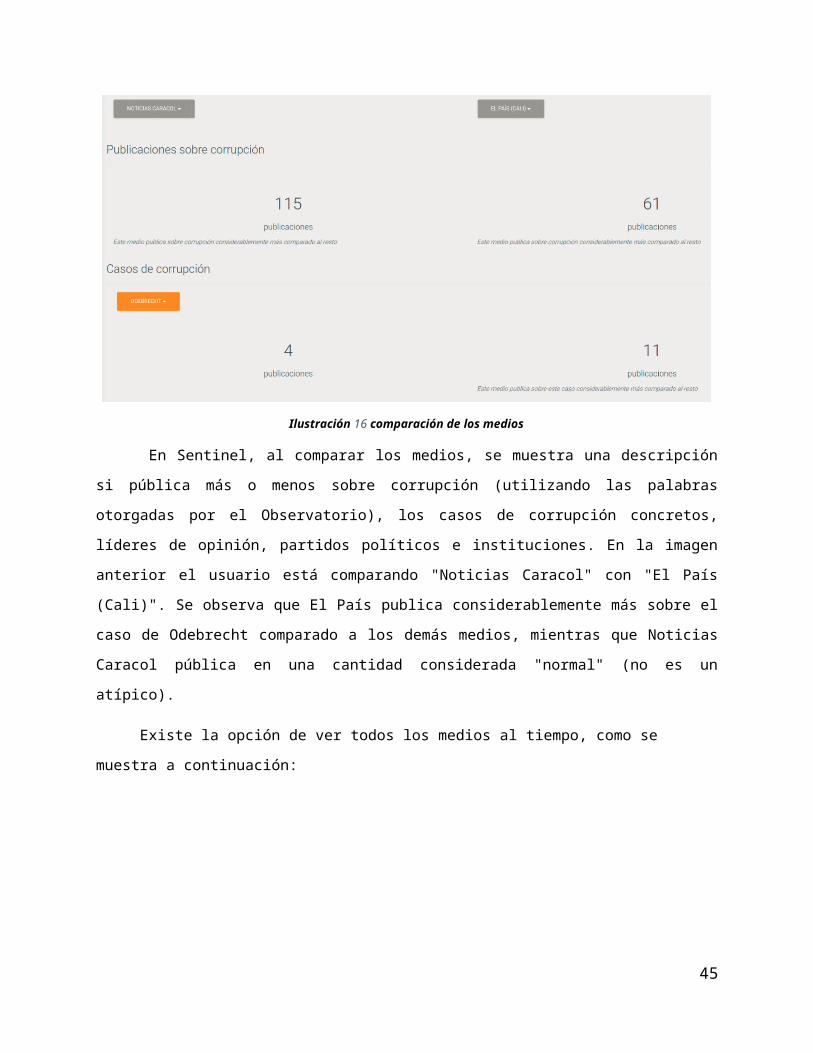
Ilustración 31 Función agregada - Comentarios populares de un líder
45

Ilustración 32 Función agregadas - Cantidad de publicaciones sobre el partido político vs cantidad de publicaciones de corrupción que mencionan al partido
Ilustración 33 Función agregada - Publicaciones de dos medios sobre un caso de corrupción
46

Ilustración 34 Función agregada - Nube de palabras de publicaciones en la página de un líder de opinión
Vale la pena mencionar que las salidas de este algoritmo también se pueden utilizar en otros
algoritmos. Por ejemplo, al sumar todas las publicaciones que un medio ha realizado sobre cierta entidad,
se puede determinar si un medio está sesgado a hacer más publicaciones sobre esa entidad o a publicar
noticias de corrupción que mencionen a esa entidad.
4.4 Evaluación de modelos
4.4.1 Evaluación de análisis de sentimiento Se realiza un muestreo aleatorio de 200 comentarios sobre líderes de opinión
Los tres integrantes del grupo clasifican los comentarios manualmente de manera independiente.
El criterio para decidir la clasificación final del sentimiento es el siguiente:
o Si al menos dos personas clasificaron el sentimiento con la misma clase, se deja ese
sentimiento
o Si cada persona lo considera como un sentimiento diferente, se deja neutral
Luego de clasificar los comentarios manualmente, se comparan con los resultados del algoritmo
de análisis de sentimientos utilizando una matriz de confusión y se determina la precisión,
exhaustividad y exactitud lograda con el algoritmo.
Esperado (manual):
Esperado (manual):
Esperado (manual):
47

negativo neutral positivoPredicho (algoritmo): negativo
1 4 0 5
Predicho (algoritmo): neutral
47 82 54 183
Predicho (algoritmo): positivo
0 6 6 12
48 92 60Tabla 18 Resultados algoritmo de análisis de sentimientos con diccionario político
Exactitud: 44.5%
Precisión Negativo: 20.0%
Precisión Neutral: 44.8%
Precisión Positivo: 50%
Exhaustividad Negativo: 2.08%
Exhaustividad Neutral: 89%
Exhaustividad Positivo: 10%
Debido a la exactitud pobre del análisis de sentimiento, se prueba con otro diccionario diferente al
político para revisar si la exactitud aumenta. De manera sorpresiva, al utilizar un diccionario que no es
específico para política se logra obtener una exactitud de 48%. A continuación, se muestran los
resultados:
Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
Predicho (algoritmo): negativo
1 2 1 4
Predicho (algoritmo): neutral
47 85 49 181
Predicho (algoritmo): positivo
0 5 10 15
48 92 60Tabla 19 Resultados algoritmo de análisis de sentimientos con diccionario genérico
Exactitud: 48.0%
Precisión Negativo: 25.0%
Precisión Neutral: 47.0%
Precisión Positivo: 66.7%
48

Exhaustividad Negativo: 2.08%
Exhaustividad Neutral: 92.4%
Exhaustividad Positivo: 16.7%
Se decide, entonces, probar con la solución de análisis de sentimientos de IBM: Watson Tone Analyzer
(IBM, 2017). Esta herramienta es un poco más robusta, y no retorna "negativo", "neutral" y/o "positivo",
sino que retorna un ranking de emociones. Las 5 emociones que mide Watson Tone Analyzer, son:
enfado, asco, miedo, alegría y tristeza. Para poder comparar directamente los resultados de Tone Analyzer
con las clasificaciones manuales que el grupo de trabajo hizo sobre los comentarios, se debe hacer un
mapeo de cuáles emociones se consideran negativas y positivas. En este caso, el grupo decide que las
emociones negativas son: enfado, asco, miedo y tristeza; y la emoción positiva es alegría.
Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
Predicho (algoritmo): negativo
26 20 19 65
Predicho (algoritmo): neutral
21 20 28 69
Predicho (algoritmo): positivo
9 12 45 66
56 52 92Tabla 20 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.4
Exactitud: 45.5%
Precisión Negativo: 33.8%
Precisión Neutral: 44.9%
Precisión Positivo: 45.4%
Exhaustividad Negativo: 45.8%
Exhaustividad Neutral: 33.6%
Exhaustividad Positivo: 50%
Vale la pena mencionar que, para utilizar IBM Watson Tone Analyzer, fue necesario traducir los
comentarios a inglés, debido a que actualmente no cuenta con soporte para el idioma español. Además de
esto, es necesario definir un cutoff, para saber cuándo se debe considerar un comentario como positivo,
negativo o neutral. En este caso, el grupo de trabajo definió inicialmente un cutoff de 0.4. Tone Analyzer
asigna un puntaje a cada emoción entre 0 y 1. Si alguna emoción tiene un valor mayor o igual al cutoff
(por definición del grupo, si es mayor a 0.4), entonces se considera que esa es la emoción más fuerte.
49

Existe un problema, y es que las puntuaciones no son complementarias. Es decir, si se suma el puntaje
de todas estas emociones, puede que la suma no dé un total de 1. Esto representa un problema para
evaluar el algoritmo porque pueden existir, por ejemplo, valores para tristeza y alegría mayores a 0.4 en
un mismo mensaje, lo cual hace más difícil definir qué polaridad tiene finalmente un comentario.
Comparando los resultados obtenidos con IBM Watson Tone Analyzer y los demás diccionarios de
sentimientos, se nota que con Tone Analyzer se pierde un poco de precisión y exactitud, a cambio de más
exhaustividad (en la polaridad negativa y positiva).
En busca de mejores niveles de exactitud, precisión y exhaustividad, se prueba con diferentes valores
para el cutoff y se vuelven a tomar las medidas. A continuación, se muestran las matrices de confusión
para diferentes cutoffs:
Cutoff = 0.2
Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
Predicho (algoritmo): negativo
37 27 37 101
Predicho (algoritmo): neutral
4 9 7 20
Predicho (algoritmo): positivo
15 16 48 79
56 52 92Tabla 21 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.2
Exactitud: 47.0%
Precisión Negativo: 36.6%
Precisión Neutral: 45.0%
Precisión Positivo: 60.8%
Exhaustividad Negativo: 66.1%
Exhaustividad Neutral: 17.3%
Exhaustividad Positivo: 52.2%
Cutoff = 0.3
Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
50
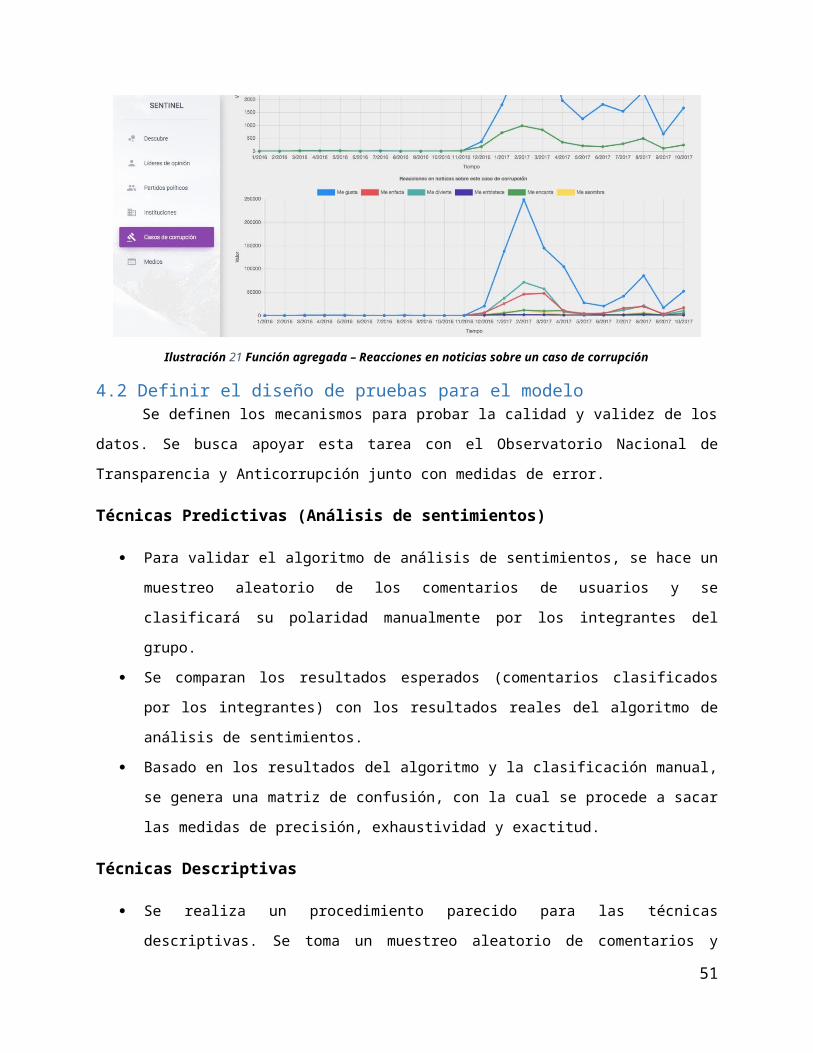
Predicho (algoritmo): negativo
30 22 25 77
Predicho (algoritmo): neutral
12 15 17 44
Predicho (algoritmo): positivo
14 15 50 79
56 52 92Tabla 22 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.3
Exactitud: 47.5%
Precisión Negativo: 39.0%
Precisión Neutral: 34.1%
Precisión Positivo: 63.3%
Exhaustividad Negativo: 53.6%
Exhaustividad Neutral: 28.9%
Exhaustividad Positivo: 54.3%
Cutoff = 0.5
Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
Predicho (algoritmo): negativo
20 14 12 46
Predicho (algoritmo): neutral
31 28 41 100
Predicho (algoritmo): positivo
5 10 39 54
56 52 92Tabla 23 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.5
Exactitud: 43.5%
Precisión Negativo: 43.4%
Precisión Neutral: 28.0%
Precisión Positivo: 72.2%
Exhaustividad Negativo: 35.7%
Exhaustividad Neutral: 53.8%
Exhaustividad Positivo: 42%
51

Cutoff = 0.6
Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
Predicho (algoritmo): negativo
11 4 2 17
Predicho (algoritmo): neutral
44 41 62 147
Predicho (algoritmo): positivo
1 7 28 36
56 52 92Tabla 24 Matriz de confusión IBM Watson Tone Analyzer, cutoff = 0.6
Exactitud: 40.0%
Precisión Negativo: 64.7%
Precisión Neutral: 27.9%
Precisión Positivo: 77.7%
Exhaustividad Negativo: 19.6%
Exhaustividad Neutral: 78.8%
Exhaustividad Positivo: 30.4%
La decisión final sobre cuál cutoff es el adecuado, debe ser algo que decida el Observatorio, debido a
que ellos son los que pueden determinar si es más importante para ellos tener mayor exhaustividad o
mayor precisión. De igual manera, se debe tener en cuenta el costo de utilizar el servicio de IBM Watson
Tone Analyzer.
Con fines de hacer una comparación más justa, se decide utilizar también Google Cloud Natural
Language API que tiene soporte nativo para español. Por esta razón, no es necesario traducir el texto a
inglés antes de analizar el sentimiento. A diferencia de Watson Tone Analyzer, la herramienta de Google
retorna un único valor entre –1 y 1 (no retorna valores para diferentes emociones) que indica el
sentimiento general del documento; -1 siendo muy negativo y 1 siendo muy positivo. Google recomienda
un cutoff de 0.25: si el puntaje final del documento es mayor o igual a 0.25 es positivo, y si es menor o
igual a –0.25 es negativo, de lo contrario se considera neutral.
Los resultados con el API de Google en general fueron mejores que bag-of-words y IBM Watson Tone
Analyzer. A continuación, se muestran las matrices de confusión obtenidas junto con su respectivo cutoff:
Cutoff = 0.25 (cutoff por defecto recomendado por Google)
52

Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
Predicho (algoritmo): negativo
27 18 6 51
Predicho (algoritmo): neutral
18 24 21 63
Predicho (algoritmo): positivo
11 10 65 86
56 52 92Tabla 25 Matriz de confusión Cloud Natural Language API, cutoff = 0.25
Exactitud: 58.0%
Precisión Negativo: 52.9%
Precisión Neutral: 38.1%
Precisión Positivo: 75.6%
Exhaustividad Negativo: 48.2%
Exhaustividad Neutral: 46.2%
Exhaustividad Positivo: 70.7%
Cutoff = 0.2
Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
Predicho (algoritmo): negativo
29 21 7 57
Predicho (algoritmo): neutral
9 15 17 41
Predicho (algoritmo): positivo
18 16 68 102
56 52 92Tabla 26 Matriz de confusión Cloud Natural Language API, cutoff = 0.2
Exactitud: 56.0%
Precisión Negativo: 50.9%
Precisión Neutral: 36.6%
Precisión Positivo: 66.7%
Exhaustividad Negativo: 51.8%
Exhaustividad Neutral: 28.8%
53

Exhaustividad Positivo: 73.9%
Cutoff = 0.3
Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
Predicho (algoritmo): negativo
27 18 6 51
Predicho (algoritmo): neutral
18 24 21 63
Predicho (algoritmo): positivo
11 10 65 86
56 52 92Tabla 27 Matriz de confusión Cloud Natural Language API, cutoff = 0.3
Exactitud: 58.0%
Precisión Negativo: 52.9%
Precisión Neutral: 38.1%
Precisión Positivo: 75.6%
Exhaustividad Negativo: 48.2%
Exhaustividad Neutral: 46.2%
Exhaustividad Positivo: 70.7%
Cutoff = 0.4
Esperado (manual): negativo
Esperado (manual): neutral
Esperado (manual): positivo
Predicho (algoritmo): negativo
19 16 5 40
Predicho (algoritmo): neutral
29 27 34 90
Predicho (algoritmo): positivo
8 9 53 70
56 52 92Tabla 28 Matriz de confusión Cloud Natural Language API, cutoff = 0.4
Exactitud: 49.5%
Precisión Negativo: 47.5%
Precisión Neutral: 30.0%
54
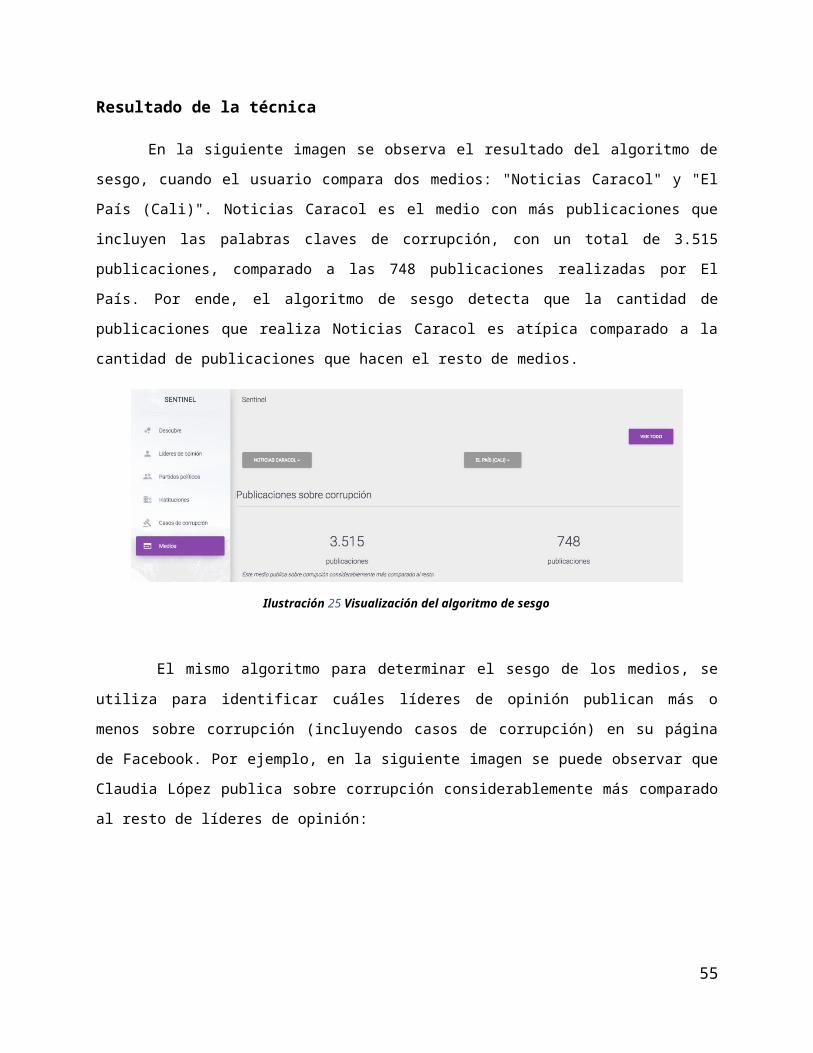
Precisión Positivo: 75.7%
Exhaustividad Negativo: 33.9%
Exhaustividad Neutral: 51.9%
Exhaustividad Positivo: 57.6%
Al observar estos resultados, se concluye que la mejor herramienta de análisis de sentimientos para el
caso específico de Sentinel es Google Cloud Natural Language API. Sin embargo, estas soluciones eran
bastante costosas, por lo cual se recurrió a utilizar un algoritmo de análisis de sentimientos desarrollado
por CAOBA en el artículo "CSL: A Combined Spanish Lexicon - Resource for Polarity Classification and
Sentiment Analysis" (Moreno-Sandoval et al., 2017). Para el desarrollo de Sentinel se terminó utilizando
el algoritmo de bag-of-words, debido al alto costo de las herramientas comerciales considerando que se
analizan más de 100 mil comentarios.
4.4.2 Evaluación de algoritmos descriptivos
Se realiza un muestreo aleatorio de 300 comentarios y publicaciones sobre entidades (líderes de
opinión, instituciones, partidos políticos) y palabras de corrupción (incluyendo casos de
corrupción), haciendo una búsqueda con las expresiones regulares creadas por el grupo.
150 comentarios y publicaciones son sobre entidades y los otros 150 son sobre palabras y casos
de corrupción.
Se verifica que en realidad las publicaciones y comentarios extraídos correspondan a entidades y
palabras/casos de corrupción, con fines de evaluar qué tan bien desarrolladas están las
expresiones regulares. Se obtienen los siguientes resultados:
o Publicaciones y comentarios sobre entidades extraídas por el algoritmo: 150
o Publicaciones y comentarios con palabras y casos de corrupción extraídas por el
algoritmo: 150
o Publicaciones y comentarios que realmente mencionaban entidades: 139
o Publicaciones y comentarios que realmente mencionaban palabras y casos de
corrupción: 150
Con esto se obtiene una exactitud de 96.3% en la extracción de entidades y palabras/casos de
corrupción mencionados. Las expresiones regulares que tienen error son las que buscan entidades. Al
indagar un poco más a fondo cuáles son las expresiones regulares que están generando errores, el grupo
observa que son las del Partido Mira (porque comúnmente se refiere a este partido simplemente por
Mira). Esta expresión regular disminuye la precisión debido a que los usuarios comentan seguido la
palabra "mira" (del verbo mirar), por lo cual el grupo decide modificar la expresión regular para que
55

busque "Partido Mira" en vez de "Mira". El resto de expresiones regulares se dejan como estaban
inicialmente. Habiendo garantizado la calidad de las expresiones regulares generadas, se aplicaron los
algoritmos descriptivos y funciones agregadas sobre la muestra realizada para verificar el correcto
funcionamiento de los mismos.
5. Evaluación
5.1 Evaluación de resultados
Evaluación del Observatorio de Transparencia y Anticorrupción
La Secretaría de Trasparencia realizó un documento donde expresan algunas recomendaciones y
conclusiones sobre Sentinel, además expresan que existe un potencial enorme en la iniciativa y que así
mismo hay amplio espacio para la mejora. A continuación, se presenta la evaluación del trabajo realizada
por la secretaría de transparencia:
Conclusiones y recomendaciones herramienta SENTINEL
Actualmente, la Secretaría enfoca sus esfuerzos en analizar los indicadores de percepción, única aproximación existente a la medición del fenómeno de la corrupción. El indicador más conocido es el calculado por Transparencia Internacional, en el que Colombia está en el puesto 90 de 176 países partícipes de la medición. Cabe destacar que la percepción es una medición subjetiva, y es necesario analizar los factores que la afectan, sus manifestaciones y si es un medio efectivo de medir la corrupción en un país.
Sentinel podría ser entonces una herramienta útil para observar, desde las redes sociales, cómo los medios de comunicación, los líderes de opinión y las instituciones, pueden alterar a través de sus publicaciones la percepción de corrupción en los ciudadanos y generar reacciones de apoyo o indignación.
Este mapeo de los factores que más alteran la percepción y la participación de los ciudadanos en las discusiones relacionadas con corrupción, nos permite entrever los focos a los que debe dirigirse la formulación de política pública, conforme a las necesidades y demandas de la ciudadanía. A su vez, se genera un desafío importante para lograr que las noticias no procuren solamente un aumento en la percepción de corrupción, sino que incrementen las acciones concretas de vigilancia y control social.
A continuación, esbozamos algunas conclusiones y recomendaciones sobre las secciones del
56

aplicativo
1. Descubre: Esta sesión nos fue útil para conocer a profundidad el discurso que se genera en redes sociales alrededor del fenómeno de la corrupción. Esta sección del aplicativo podría mejorar si:
Se filtran aquellas palabras que no son relevantes para el análisis. El grafo se despliega más claramente para una mejor interpretación de las relaciones
entre palabras y fuentes. Es posible filtrar por categoría para verlas de forma aislada; e.g. si se puede tomar el
nodo de líderes de opinión y filtrar por líder cuáles son las palabras más asociadas a cada uno. Si bien ya es posible entrever algunas de estas cosas en el grafo general, limitar la visión a determinadas características puede hacer que su interpretación sea más ágil.
Se pueden ver estadísticas sobre la cantidad de veces que se usa una determinada palabra por cada publicación; e.g. si al colocar el puntero sobre una de las palabras (círculos azul claro) se puede ver el número de menciones.
2. Medios: Esta sección nos permitió reconocer la visibilidad por caso en medios regionales y nacionales, y sacar datos relevantes sobre la permanencia de una noticia de corrupción luego de que es publicado el caso por primera vez. Esta sección del aplicativo podría mejorar si:
Es posible obtener estadísticas por año o por mes. Se puede identificar cuál es la proporción de las publicaciones que están directamente
relacionadas con casos de corrupción frente al total de publicaciones que genera un determinado medio, líder de opinión, u otros; e.g. “de X número de noticias generales que publica Y medio, Z noticias se asocian a temas de corrupción”.
Se puede identificar cuál es la proporción de las publicaciones sobre un caso de corrupción en particular frente al total de publicaciones de actos de corrupción que genera un determinado medio, líder de opinión, u otros; e.g. “de X número de noticias sobre casos de corrupción en general que publica Y medio, Z noticias son sobre un determinado caso en particular”.
3. Casos de corrupción: Esta sección nos permitió concluir que efectivamente existe, en la mayoría de los casos, una relación directamente proporcional entre las publicaciones relacionadas con corrupción y los comentarios de los individuos en redes sociales. Cabe destacar que esto confirma la hipótesis de que la actividad ciudadana en redes tiende a ser exclusivamente reaccionaria; esto es, que difícilmente se sigue comentando sobre un determinado caso de corrupción si se dejan de publicar noticias sobre el mismo en páginas de medios, líderes de opinión, u otros (entre otros). Esta sección del aplicativo podría mejorar si:
Se genera una gráfica que compare los datos de varios casos de corrupción a la vez; esto es, una gráfica donde se pueda observar cuál caso de corrupción fue el que tuvo más publicaciones y cómo se compara con los demás (lo mismo se puede hacer en materia de comentarios).
4. Instituciones: Esta sección provee información valiosa para realizar estudios comparados con otras encuestas tales como el Barómetro de las Américas. Es aconsejable, sin embargo, mejorar la forma en que se presenta la información; esto, como en otros casos anteriores, se puede lograr si:
Se genera una gráfica que compare los datos de varias instituciones a la vez; esto es, una gráfica donde se pueda observar cuál institución tuvo el mayor número de publicaciones sobre corrupción y cómo se compara con los demás (lo mismo se puede hacer en materia
57

de comentarios).5. Partidos políticos:
Esta sección permite a la Secretaría hacer un diagnóstico sobre cuáles son las fuerzas políticas que mayor actividad tienen en términos de publicaciones y comentarios acerca del fenómeno de la corrupción. Para proyectos posteriores, esta información podrá servir para analizar si una mayor o menor actividad en esta materia se correlaciona con un mayor número de iniciativas o proyectos presentados para luchar contra la corrupción, o si de hecho se relaciona con un mayor o menor número de investigaciones sobre sus miembros sobre casos de corrupción. Tal como en otras secciones, ese aspecto se puede mejorar si:
Se genera una gráfica que compare los datos de varios partidos políticos a la vez; esto es, una gráfica donde se pueda observar cuál partido político tuvo el mayor número de publicaciones sobre corrupción y cómo se compara con los demás (lo mismo se puede hacer en materia de comentarios).
6. Líderes de opinión: En este apartado pudimos observar la importancia del tema de la corrupción para los líderes de opinión, y el apoyo o reprobación de los ciudadanos a sus posturas. Esta sección del aplicativo podría mejorar si:
Es posible realizar cruces entre las publicaciones y comentarios de los líderes de opinión con el resto de categorías.
Además del informe realizado por la Secretaría de Transparencia, en la reunión que se tuvo para
presentar el sistema en funcionamiento, se pudieron derivar las siguientes conclusiones:
En la sección Casos de Corrupción, los usuarios manifiestan su indignación por medio de la
reacción "Me divierte" indicando una postura sarcástica frente a los casos de corrupción que se
presentan.
La reacción "Me gusta" no es muy diciente sobre la actitud de las personas hacia casos de
corrupción. Es decir, los usuarios le dan "Me gusta" a una publicación más que cualquier otra
reacción cuando se espera que generen más reacciones de "Me enfada" y "Me divierte".
Algunos de los líderes de opinión monitoreados no tienen página en Facebook y por lo tanto no se
puede obtener información más detallada sobre estos.
Se observa un pico en la actividad de los líderes de opinión Álvaro Uribe y Juan Manuel Santos
en el mes de noviembre de 2016, debido al proceso de paz.
Para el caso de los partidos políticos, los comentarios negativos por lo general prevalecen sobre
los comentarios positivos. Esto se puede contrastar con los resultados obtenidos en la encuesta
LAPOP 2015, donde los partidos políticos cuentan el nivel de desconfianza más alto entre los
encuestados.
Desde un punto de vista general, se observa que la negatividad que los usuarios manifiestan es
mayor a los comentarios o reacciones positivas. En la entrevista inicial con la Secretaría de
58

Transparencia, Mauricio Ortiz tenía la hipótesis que en redes sociales hay mayor indignación
(Castañeda, Ortiz, & Pérez, 2017). A partir de los resultados obtenidos, todo parece indicar que
hay un mayor nivel de indignación en Facebook respecto a líderes de opinión, partidos políticos e
instituciones.
Sentinel permite saber quiénes pueden ser aliados de la Secretaría de Transparencia para llevar a
cabo investigaciones e iniciativas anticorrupción, priorizando estrategias dirigidas a ciertas áreas
donde la percepción de corrupción de los usuarios sea más alta.
Basándose en el informe realizado por la Secretaría de Transparencia y las conclusiones generadas a
partir de la reunión con ellos, se puede afirmar que el sistema cumple con los objetivos planteados al
inicio del proyecto. De igual manera también se resalta la utilidad e importancia del proyecto, puesto que
el sistema desarrollado permite al Observatorio identificar la percepción y la participación de la población
civil en discusiones relacionadas con corrupción y de esta manera poder tomar decisiones que van
enfocadas a la correcta formulación de política pública conforme a las necesidades y demandas de la
nación.
5.2 Encuesta TAM Para validar el sistema con el usuario final, el grupo de trabajo desarrolló una serie de preguntas bajo
los lineamientos de validación TAM (Venkatesh & Hillol, 2008) en donde el principal propósito es
realizar una serie de preguntas en donde se validan cuatro variables principales:
1. Variables externas (Involucramiento): Qué tanto el usuario final estuvo involucrado en el
desarrollo del sistema
2. Utilidad percibida: Qué nivel de utilidad encuentra el usuario final frente al sistema.
3. Percepción de facilidad de uso: Qué tan fácil fue para el usuario final la interacción con el
sistema.
4. Actitud hacia el uso: Qué tan dispuesto está el usuario final al momento de usar el sistema.
Previamente a la realización de la encuesta, a los usuarios finales se les capacitó y mostró el correcto
funcionamiento y uso del sistema desarrollado. La encuesta realizada tiene la siguiente escala de
clasificación:
Valor Descripción
1 Totalmente en desacuerdo
2 Moderadamente en desacuerdo
59

3 Neutral
4 Moderadamente de acuerdo
5 Totalmente de acuerdo
Tabla 29 Encuesta escala de clasificación
ver la encuesta TAM realizada ver el Anexo D Encuesta TAM .
A continuación, se presentan los resultados de la encuesta.
Ilustración 35 Variables externas: Involucrados
Ilustración 36 Facilidad de uso percibida
60

Ilustración 37 Utilidad percibida
Ilustración 38 Actitud hacia el uso
61

Ilustración 39 Nivel satisfacción Sentinel
Ilustración 40 Nivel satisfacción objetivo general
Como se puede observar en los resultados de las encuestas TAM se puede concluir los siguiente:
1. En términos generales, el usuario encuentra el sistema fácil de usar y navegar; se desplaza con
comodidad y fluidez por la interfaz del sistema, sin embargo, hay espacio para la mejora y el
arreglo de ciertas secciones de la interfaz como lo es por el ejemplo el grafo que visualiza la
asociación de palabras.
62

2. El usuario resalta la utilidad y beneficio de usar el sistema en las labores diarias, y además
considera que el sistema puede ayudar en iniciativas anticorrupción.
3. El involucramiento del usuario en el desarrollo del sistema fue productivo y constante.
4. El usuario afirma que el sistema cumple con el objetivo general planteado al incido de la
formulación del trabajo de investigación.
5.2 Próximos pasos Luego de validar el sistema construido con la Secretaría de Transparencia, se procede a hacer el plan
de despliegue. A pesar de que surgen nuevas ideas para mejorar el proyecto, son requerimientos y/o
funcionalidades que no se contemplaban dentro del alcance inicial del proyecto y por ende no estaban
dentro del tiempo estimado por el grupo de trabajo. Por esta razón, las nuevas sugerencias por parte del
Observatorio quedan como trabajo futuro para el proyecto Sentinel.
6. Despliegue
6.1 Plan de despliegue
Requisitos del sistema
El sistema fue desarrollado para Ubuntu 16.04 (64-bits), aunque también debería funcionar
para macOS.
Se recomiendan las siguientes especificaciones para poder ejecutar todos los módulos del
sistema de manera eficiente:
Características Recomendado/MínimoSistema Operativo Ubuntu 16.04 (64-bit), macOS
(64-bit)Procesador Intel Core i5/Intel Core 2 DuoRAM 32 GB/16 GBDisco Duro 128 GB/64 GBBase de datos MongoDB 3.4Python Python 3.5.2/Python 3.x (Python
2 no está soportado)PIP PIP 9+/PIP 8.1.1R R 3.4.1/R 3.1.xNode.js Node.js v6.10.3/Node.js v6.xNPM (Node Package Manager)
NPM v3.10.10
Tabla 30 Especificaciones
63
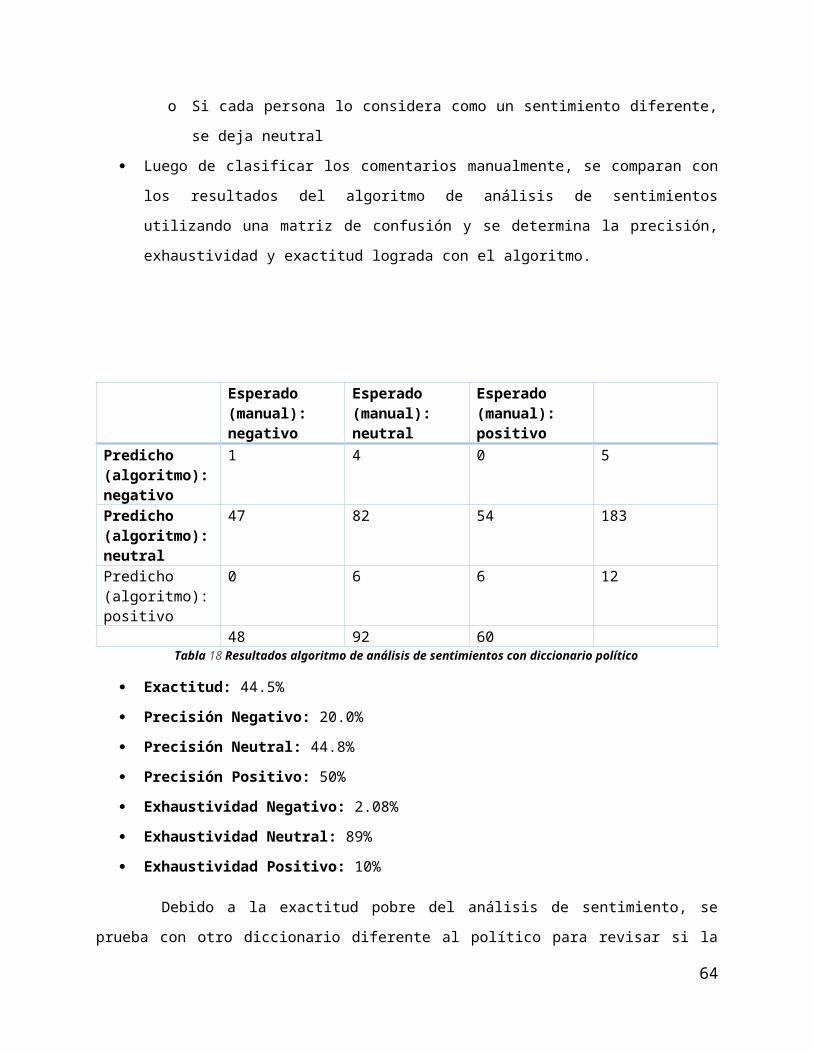
Además de las especificaciones anteriores, se requiere de una cuenta de Facebook para poder extraer
datos. Para esto es necesario también registrarse en el portal de desarrolladores de Facebook (Facebook
Developers) en https://developers.facebook.com/.
En el portal de Facebook se debe crear una nueva aplicación. La aplicación puede tener cualquier
nombre. Al crear la aplicación, es importante tomar nota del ID de la aplicación creada y del "secret" de
la aplicación. Estos dos datos son importantes y necesarios para poder extraer datos.
Código fuente
El código de los tres módulos: extracción de datos de Facebook, analítica y visualización; se puede
encontrar en el repositorio de Sentinel en Github: https://github.com/sentinelanalytics.
En el repositorio se encontrarán los tres módulos con los siguientes nombres:
facebook-scraper-py: componente de extracción de datos
analytics: componente de analítica
sentinel: componente de visualización
El código fuente se debe descargar y se debe colocar en una carpeta llamada "workspace" (sin
comillas), en la carpeta home del usuario. Cada carpeta (es decir, cada módulo), debe estar dentro de esta
carpeta. Por ejemplo, si el nombre de usuario en una máquina Ubuntu es "sentinel", entonces se debe
descargar el código en las siguientes rutas:
facebook-scraper-py: /home/sentinel/workspace/facebook-scraper-py
analytics: /home/sentinel/workspace/analytics
sentinel: /home/sentinel/workspace/sentinel
Instalación
En esta sección se muestra cómo instalar las herramientas necesarias para ejecutar todo el sistema de
Sentinel. Se muestran las instrucciones para Ubuntu 16.04, pero el procedimiento es parecido para
macOS.
MongoDB
Para ver las instrucciones específicas de cómo instalar MongoDB para su sistema operativo, diríjase a
la página oficial de MongoDB: https://docs.mongodb.com/manual/installation/
MongoDB se puede instalar directamente como un servicio en el sistema operativo que esté
utilizando. Sin embargo, se recomienda instalarlo utilizando contenedores Docker, debido a que es más
64

fácil y rápido de instalar. Si está familiarizado con la tecnología Docker, puede descargar la imagen de
MongoDB en: https://hub.docker.com/_/mongo/. Esta fue la manera en que el grupo de trabajo trabajó con
Mongo durante el desarrollo de Sentinel.
Python 3.5.2
$ sudo apt-get update
$ sudo apt-get install python3.5.2
PIP
$ sudo apt-get install python3-pip
R
Para la instalación de R, seguir las instrucciones en: https://www.r-bloggers.com/download-and-
install-r-in-ubuntu/
Node.js y NPM
No se recomienda ejecutar el instalador oficial de Node.js en Ubuntu y Mac debido a que se instala en
carpetas con permisos restringidos y esto puede presentar problemas al instalar paquetes de Node.js
utilizando NPM.
Por el contrario, se recomienda al usuario instalar NVM (Node Version Manager), que instala Node.js
y NPM en carpetas a las que cualquier usuario puede acceder. Para ver las instrucciones de cómo instalar
NVM (para Ubuntu y para Mac), ir a: https://github.com/creationix/nvm.
Al instalar Node.js con NVM, también se instala NPM. NPM se encarga de descargar las librerías
(paquetes) necesarios para ejecutar una aplicación Node.js.
Sentinel
Al descargar el código fuente de cada componente, estos ya están en capacidad de ejecutarse. El
usuario puede ejecutar cada componente de forma manual. Sin embargo, se recomienda al usuario utilizar
el script provisto por Sentinel y que estará situado en /home/<usuario>/workspace/analytics/util/setup.sh
luego de que el usuario descargue el código fuente de los tres módulos. El script setup.sh programa la
ejecución automática de los componentes de Sentinel.
65

Si el usuario está familiarizado con cron en Linux, puede crear su propio script para programar la
ejecución de los diferentes módulos y personalizar la periodicidad con la que se ejecutan, o puede
modificar el script provisto por Sentinel
6.2 Plan de monitoreo y mantenimientoBases de conocimiento
El primer aspecto de mantenimiento que debe tener en cuenta la Secretaría de Transparencia (o
cualquier otra persona o institución que desee utilizar el sistema) es en cuanto a las palabras claves que se
desean buscar. A medida que se van encontrando nuevas palabras, ya sean entidades, palabras de
corrupción, casos de corrupción, etc.; estas se deben ir agregando a la base de conocimiento, con fines de
enriquecer los términos y entidades para poder llevar a cabo un análisis más completo sobre la
corrupción.
Los archivos que contienen la base de conocimiento, están situados en el código fuente del
componente de analítica, específicamente en la carpeta "base-conocimiento". Por ejemplo, para el usuario
"sentinel", esta carpeta estaría ubicada en: /home/sentinel/workspace/analytics/base-conocimiento.
En esta carpeta encontrará las bases de conocimiento para casos de corrupción, instituciones, líderes de
opinión, palabras de corrupción y partidos políticos. También se provee una lista de stop words que el
usuario puede completar en caso de que encuentre palabras que no aportan ningún significado, por
ejemplo, en el algoritmo de asociación de palabras.
A continuación, se describen las propiedades de cada archivo:
casos-corrupcion.all.txt
Este archivo es un archivo separado por comas, y en él se encuentran las expresiones regulares para
identificar publicaciones y comentarios que mencionan casos de corrupción. El esquema del archivo es el
siguiente (se muestra el significado de cada columna, en orden):
1. Expresión regular para identificar el caso de corrupción: puede incluir acentos, mayúsculas,
signos de puntuación, y cualquier otro carácter permitido en las expresiones regulares de Python.
2. Valor booleano, indicando si se debe hacer un encuentro exacto de la expresión regular: los
valores que puede tomar esta columna son "true" o "false" (sin comillas).
En caso de que el valor sea "true", significa que la expresión regular buscará una palabra
completa que coincida con la expresión regular definida en la primera columna y no buscará, por
ejemplo, que la expresión regular esté dentro de otra palabra. Esto es útil en los casos donde se
tienen acrónimos, que son más susceptibles a aparecer dentro de otras palabras. Por ejemplo: la
66

palabra ONU está dentro de monumental. Por lo cual sería necesario asignar un valor de "true" en
esta columna para que solo busque la palabra ONU (todas las expresiones regulares desarrolladas
ignoran las mayúsculas, y se buscan en el texto luego de haber sido pre-procesado y haber
removido los stop words).
3. Caso de corrupción (todo en minúscula y sin acento): esta columna se utiliza para definir el caso
de corrupción o la categoría a la cual pertenece la expresión.
Es posible que haya más de una manera de referirse a un caso de corrupción (ej: fiscal
anticorrupción y Luis Gustavo Moreno, ambos hacen referencia al mismo caso), por lo cual es
necesario tener la opción de agrupar varios casos de corrupción en uno solo. Al asignar el mismo
valor en esta columna para dos casos de corrupción, se están agrupando en uno solo. Esta
columna no debe tener espacios (se recomienda utilizar un guion en vez de espacio).
4. Nombre del caso de corrupción: este nombre no debe contener sintaxis de expresiones regulares.
En esta columna se pone el nombre "real" del caso de corrupción (con mayúsculas, acentos, etc.).
El valor de esta columna es el que le aparece al usuario final en el componente de visualización
de Sentinel. Igual que con la columna anterior, si existen dos maneras de referirse al mismo caso
de corrupción, esta columna debe tener el mismo valor para los dos. Esta columna puede contener
espacio.
Ejemplo del archivo:
Odebrecht,false,odebrecht,Odebrechtfiscal anticorrupci[óòo]n,false,fiscal-anticorrupcion,Luis Gustavo Moreno (fiscal anticorrupción)Luis Gustavo Moreno,false,fiscal-anticorrupcion,Luis Gustavo Moreno (fiscal anticorrupción)...
Se observa en la primera fila, el caso Odebrecht. En este caso, la expresión regular no requiere de
ninguna sintaxis especial, debido a que Odebrecht no contiene ningún acento o signo de puntuación. Hay
que recordar que la búsqueda de las expresiones regulares (en Sentinel) no tiene en cuenta las
mayúsculas, por lo cual daría el mismo resultado si se tiene la expresión regular "Odebrecht" u
"odebrecht".
En la segunda y tercera fila, se tienen dos maneras de referirse al caso del ex-fiscal anticorrupción. En
la segunda fila, se tiene la expresión regular "fiscal anticorrupci[óòo]n". Para este caso no se incluye la
expresión regular "ex-fiscal anticorrupci[óòo]n" debido a que la expresión regular "fiscal
anticorrupci[óòo]n" ya está definida, y como la tercera columna tiene un valor "false", significa que puede
buscar este patrón dentro de otra palabra. Por ende, la expresión regular va a ser capaz de encontrar "ex-
fiscal anticorrupción" porque contiene la expresión "fiscal anticorrupci[óòo]n".
67

Para conocer más sobre la sintaxis de expresiones regulares, se puede dirigir a: https://docs.python.org/3/library/re.html#regular-expression-syntax
instituciones.all.txt
Este archivo tiene el mismo esquema que el de casos de corrupción. La única diferencia es que se
definen expresiones regulares para identificar a instituciones en vez de casos de corrupción. Igualmente,
se conservan las reglas de agrupar varias formas de referirse a una institución.
lideres-opinion .all.txt
Este archivo tiene el mismo esquema que el de casos de corrupción. La única diferencia es que se
definen expresiones regulares para identificar líderes de opinión en vez de casos de corrupción.
Igualmente, se conservan las reglas de agrupar varias formas de referirse a un líder de opinión.
palabras-corrupcion.all.txt
Este archivo tiene el mismo esquema que el de casos de corrupción. La única diferencia es que se
definen expresiones regulares para identificar palabras relacionadas con corrupción en vez de casos de
corrupción.
Para el caso del archivo de palabras de corrupción, se debe colocar el valor "corrupción" (sin tilde y
sin comillas) en la tercera columna para todas las filas, debido a que todas las palabras definidas en este
archivo se agrupan en el concepto de corrupción. La última columna si puede tomar un valor diferente
para cada palabra.
partidos-politicos.all.txt
Este archivo tiene el mismo esquema que el de casos de corrupción. La única diferencia es que se
definen expresiones regulares para identificar partidos políticos en vez de casos de corrupción.
Igualmente, se conservan las reglas de agrupar varias formas de referirse a un partido político.
palabras-corrupcion-assoc.txt
Este archivo tiene un esquema diferente a los demás, y es el que se utiliza para el algoritmo de
asociación de palabras. A continuación, se detalla el significado de cada columna, en orden:
1. Expresiones regulares: al igual que los anteriores archivos, las expresiones regulares de esta
primera columna permiten identificar publicaciones y comentarios que mencionen entidades y
palabras/casos de corrupción.
68

2. Valor booleano, indicando si la(s) palabra(s) de la primera columna NO contienen stop words.
Esta columna puede tomar dos valores: "true" o "false".
Por ejemplo, "Partido de la U" contiene tres stop words: "de", "la" y "u". Por lo tanto, esta
columna tendría el valor de "false". Este valor lo utiliza el algoritmo internamente para
determinar en qué campos de la base de datos debe buscar. Si la expresión regular contiene stop
words, entonces no puede buscar en el texto pre-procesado, y debe buscar en el texto original.
3. Nombre real del concepto/entidad: este es el nombre que se mostrará en el grafo, por lo tanto,
puede tener acentos, espacios y stop words.
4. Identificador del concepto/entidad: esta columna debe tener un valor único para cada fila. Es un
identificador que utiliza internamente el algoritmo de asociación de palabras, para poder
diferenciar cada nodo. En ningún momento se muestra este valor al usuario final. Solo se debe
garantizar que todas las filas de este archivo tengan un valor único en esta columna.
5. Palabras a buscar: estas palabras no deben ser expresiones regulares. Las expresiones regulares se
utilizan para identificar publicaciones y comentarios que mencionen a entidades o casos de
corrupción. Luego de haber identificado esas publicaciones/comentarios, se buscan las palabras
de esta columna. Estas palabras no deben contener acentos ni caracteres especiales, pero si
pueden contener stop words.
6. Color: la última columna indica el color del nodo. Este color se especifica en formato
hexadecimal (ej: el verde es #FFFE4F). Para ver una lista de colores hexadecimales, puede
remitirse a: https://www.w3schools.com/colors/colors_names.asp
A pesar del nombre del archivo (palabras-corrupcion-assoc.txt), este archivo no solo contiene
palabras de corrupción, sino instituciones, partidos políticos, líderes de opinión y casos de corrupción
(también las palabras de corrupción).
Nota:
El único archivo que no termina en ".all.txt" que debe modificar el usuario es palabras-corrupcion-
assoc.txt. Los archivos que no terminan en ".all.txt" (a excepción de palabras-corrupcion-assoc.txt), son
archivos de prueba que se utilizaron para desarrollar Sentinel. Estos archivos pueden servir para otros
usuarios que quieran desarrollar nuevos módulos de Sentinel sin necesidad de cargar información para
todas las entidades o casos de corrupción.
Páginas de Facebook de medios y líderes de opinión
El otro aspecto a tener en cuenta para el mantenimiento, es la lista de páginas que la Secretaría de
Transparencia desea monitorear. En el módulo de extracción de datos ( facebook-scraper-py), se
69

encuentran dos archivos llamados: config. medios. json y config. lideres.json. Estos dos archivos
contienen la lista de páginas de medios y líderes de opinión respectivamente, de las cuales se quieren
extraer publicaciones y comentarios. Estos archivos también se pueden modificar con fines de
eliminar/agregar nuevas páginas de Facebook. Los archivos están en formato JSON, y ambos tienen el
siguiente esquema:
Tabla 31 Esquema
En el objeto "credentials":
appId: en esta propiedad se debe colocar el ID de la aplicación que se creó en el portal de
desarrolladores de Facebook (ver sección 6.1 Plan de Despliegue)
appSecret: en esta propiedad se debe colocar el "secret" de la aplicación que se creó en el portal
de desarrolladores de Facebook.
En el arreglo "pages":
En este arreglo se colocan las páginas de Facebook de las cuales se quieren extraer datos.
Es importante resaltar que no se ponen las URLs de la página de Facebook, sino el ID de la
página.
El ID de una página se puede encontrar ingresando la URL de la página de Facebook en la
siguiente aplicación web: https://findmyfbid.com/
Por ejemplo, para el medio El Tiempo, primero se debe ingresar a la página de Facebook de El Tiempo
y copiar la URL de la página pública (ej: https://www.facebook.com/eltiempo). Luego se debe pegar la
70

URL en la página https://findmyfbid.com, para obtener el ID de la página. Finalmente, se copia el ID de
la página y se pega en el archivo JSON para que la próxima vez que se ejecute el módulo de extracción de
datos, tenga en cuenta la página agregada.
Ilustración 41 Buscar ID de una página de Facebook
Ilustración 42 ID de página de Facebook
6.3 Reporte final Los resultados de Sentinel se presentan en la sustentación final del trabajo de grado y en la
memoria del trabajo de grado.
La Secretaría de Transparencia realizó un informe con algunas conclusiones que pudieron sacar
gracias a Sentinel. Ver informe Conclusiones y recomendaciones herramienta SENTINEL
6.4 Revisión del proyecto6.4.1 Fortalezas
Apoyo de la Secretaría de Transparencia en la formulación y validación del proyecto.
Contacto constante con la directora del Trabajo de Grado y con la Secretaría de Transparencia.
71

Todas las herramientas que se usaron para el desarrollo del proyecto fueron gratuitas y de licencia
publica, por lo cual la Secretaría de Transparencia puede utilizar el sistema sin necesidad de
pagar.
Conocimiento previo de diferentes herramientas para el desarrollo del proyecto lo que incrementó
la agilidad del mismo.
El equipo de trabajo fue capaz de afrontar los contratiempos del proyecto.
6.4.2 Debilidades Apoyo de otras entidades diferentes al Observatorio para el entendimiento del negocio.
Como el grupo de trabajo no tenía 100% de autonomía de los servidores, en ocasiones se
presentaban problemas de disponibilidad y conectividad, los cuales no eran fácilmente
solucionables y por esta razón se presentaron problemas en el calendario del proyecto.
Existen diferentes herramientas que prestan servicios en nube para realizar analítica, sin embargo,
éstas son costosas en términos económicos y el proyecto no contaba con recursos económicos
para adquirir estas herramientas.
6.4.3 Trabajo futuro En la reunión de validación del sistema que se tuvo con la Secretaría de Transparencia, se
propusieron nuevas funcionalidades para el sistema, las cuales quedan como propuestas de
trabajo futuro en Sentinel. Estas sugerencias se pueden ver en la sección de 5. Evaluación.
Se propone crear una ontología de corrupción, con fines de tener una base de conocimiento
mucho más robusta, y tener mayor exhaustividad en la búsqueda de entidades y palabras o casos
relacionados a corrupción.
Mejorar el módulo de análisis de sentimientos. El grupo de trabajo inicialmente pretendía utilizar
una solución comercial (IBM Watson Tone Analyzer), pero no contó con los recursos monetarios
necesarios.
El tema de análisis de sentimientos es algo complicado. Incluso, los mismos integrantes del
grupo, tuvieron problemas para determinar la polaridad de los comentarios. Como trabajo futuro,
se propone probar con diferentes algoritmos y técnicas (ej: redes neuronales, Naive Bayes, etc.),
para medir cuál tiene mejor rendimiento.
Permitir realizar denuncias de casos de corrupción dentro de Sentinel, y aplicar procesos de
analítica a las denuncias en sí para conocer cuáles entidades o cuales son los temas de corrupción
más mencionados en denuncias de casos de corrupción.
El Observatorio reconoció la importancia del sistema desarrollado, pero identificó que sería de
gran utilidad realizar el mismo monitoreo sobre la red social Twitter con ánimos de obtener
conclusiones que abarquen todo el espectro de las redes sociales en la población de país.
72

7. Referencias Observatorio de Transparencia y Anticorrupción. (2017, octubre 1). Quiénes componen el Observatorio.
Recuperado el 1 de octubre de 2017, a partir de http://www.anticorrupcion.gov.co/Paginas/Qui
%C3%A9nes-componen-el-Observatorio.aspx
Observatorio de Transparencia y Anticorrupción. (2017, octubre1). Instituciones para la Lucha Contra la
Corrupción. Recuperado el 1 de octubre de 2017, a partir de
http://www.anticorrupcion.gov.co/Paginas/Instituciones.aspx
Observatorio de Transparencia y Anticorrupción. (2017, octubre 1). Misión y Visión - Observatorio de
Transparencia y Anticorrupción. Recuperado el 1 de octubre de 2017, a partir de
http://www.anticorrupcion.gov.co/Paginas/Misi%C3%B3n-Visi%C3%B3n.aspx
Observatorio de Transparencia y Anticorrupción. (2017, octubre 1). Caja de Herramientas. Recuperado el
2 de octubre de 2017, a partir derom http://www.anticorrupcion.gov.co/Paginas/caja-herramientas.aspx
Caicedo, L., Carrillo, A., Forero, J., & Uruena, J. (2017, octubre 9). Análisis del sentimiento político
mediante la aplicación de herramientas de minería de datos a través del uso de redes sociales. Recuperado
el 9 de octubre de 2017, a partir de https://repository.javeriana.edu.co/handle/10554/20516
CAOBA, A. (2017, abril 23). Corpus de sentimientos.
Ortiz, M. (2017, agosto 17). Trabajo de grado: percepción de corrupción en redes sociales.
Cerón-Guzmán, J. A., & León-Guzmán, E. (2016). A Sentiment Analysis System of Spanish Tweets and
Its Application in Colombia 2014 Presidential Election. In 2016 IEEE International Conferences on Big
Data and Cloud Computing (BDCloud), Social Computing and Networking (SocialCom), Sustainable
Computing and Communications (SustainCom) (BDCloud-SocialCom-SustainCom) (pp. 250–257).
https://doi.org/10.1109/BDCloud-SocialCom-SustainCom.2016.47
IBM. (s/f). Tone Analyzer | IBM Watson Developer Cloud. Recuperado el 28 de marzo de 2017, a partir
de https://www.ibm.com/watson/services/tone-analyzer/
73

Garcia, M., Montalvo, J., & Seligson, M. (2015, junio). Cultura política de la democracia en Colombia,
2015: Actitudes democráticas en zonas de consolidación territorial. Vanderbilt University.
Calambás Marin, D. A., & Mendoza, J. A. (2016). RART. Recuperado el 9 de marzo de 2017, a partir de
http://pegasus.javeriana.edu.co/~CIS1630AP06/entregables.html
Facebook. (s/f). Using the Graph API - Documentation. Recuperado el 27 de octubre de 2017, a partir de
https://developers.facebook.com/docs/graph-api/using-graph-api/
MongoDB. (s/f). MongoDB for GIANT Ideas. Recuperado el 5 de noviembre de 2017, a partir de
https://www.mongodb.com/index
Oracle. (s/f). Database SQL Language Reference. Recuperado el 5 de noviembre de 2017, a partir de
https://docs.oracle.com/database/121/SQLRF/functions003.htm#SQLRF20035
Dinero. (2017, octubre 13). Cementos Argos rechaza posibles sanciones de la SIC por cartel del cemento.
Recuperado el 6 de noviembre de 2017, a partir de http://www.dinero.com/empresas/articulo/cementos-
argos-sanciones-de-la-sic-por-cartel-del-cemento/251249
Castañeda, P., Ortiz, M., & Pérez, S. (2017). Entrevista con El Observatorio Nacional de Transparencia
y Anticorrupción. Observatorio Nacional de Transparencia y Anticorrupción
Cloud Natural Language API. (2017). Cloud Natural Language API | Google Cloud Platform.
Recuperado el 15 de noviembre de 2017, a partir de https://cloud.google.com/natural-language/
74