cenidet...seccionamiento de sonidos vocales ..... 45 4.3.2.2. seccionamiento de sonidos sernivocales...
TRANSCRIPT

S.E.P. S.E.I.T. D.G.I.T.
CENTRO NACIONAL DE INVESTIGACION Y DESARROLLO TECNOLOGICO
cenidet
"SINTESIS DE VOZ PARA EL IDIOMA ESPAÑOL USANDO WAVELETS"
T E S I S
PARA OBTENER EL GRADO DE:
MAESTRO EN CIENCIAS EN INGENIERIA ELECTRONICA
PRESENTA
RICARDO CORONADO VAZQUEZ
DIRECTOR DE TESIS
M.I. CARLOS ENRIQUE RAMIREZ VALENZUELA
CUERNAVACA, MORELOS DICIEMBRE 1999

S.E.P. S.E.i.i. S.N.1.T
CENTRO NACIONAL DE INVESTIGACI6N Y DESARROLLO TECNOL6GiCO cenidet
ACADEMIA DE LA MAESTRfA EN ELECTRbNICA
FORMA R11 ACEPTACION DEL TRABAJO DE TESIS
Cuernavaca, Mor.
Dr. Juan Manuel Ricaiio Castillo Director del cenidet Presente
Jefe del Depto. de Electrónica At‘n. Dr. Jaime E. Arau Roffiel
Después de haber revisado el trabaio de tesis t.....ado: ‘‘ 1 DE VOZ PARA EL IDIOMA ESPAÑOL USANDO WAVELETS”, elaborado por el alumno Ricardo Coronado Vázquez, bajo la dirección del M.I. Carlos E. Ramirez Valenzueia, el trabajo presentado se ACEPTA para proceder a su impresión.
A T E N T A M E N T E
ÍNTI
J e Pi%? c L 9 , Dr. Víctor Manuel Cárdenas Galindo
C.C.P.: Dr. Abraham Claudio Sáncbez I Pdte. de la Academia de Electrónica Ing. Jaime Rosas Álvarez I Jefe del Depto. de Servicios Escolares Expediente.
INTERIOR INTERNADO PALMIRA S/N. CUERNAVACA. MOR. MEXICO AP 5-164 CP 62050. CUERNAVACA, TELS. (73112 2314.12 7613.18 7741. FAX (73) 12 2434 Dr. Jaime Arau RaifieUJete del Depia de Elecir6nico EMAIL [email protected]

:entro Nacional de Investigación y Desarrollo Tecnológico
Cuernavaca, Morelos
ng. Ricardo Coronado Vazquer >andidat0 al grado de Maestro en Ciencias !n Ingeniería Electrónica ’resente
lespués de haber sometido a revisión su trabajo final de tesis titulado: “SíNTESIS DE VOZ PARA EL DlOMA ESPAÑOL USANDO WAVELETS”, y habiendo cumplido con todas las indicaciones que el jurado evisor de tesis le hizo, le comunico que se le concede autorización para que proceda a la impresión de la nisma, como requisito para la obtención del grado.
?eciba un cordial saludo
: .c.p. expediente.
gTERIOR INTERNADO PALMIRA SIN. CUERNAVACA, MOR. MCXICO iP 5-164 CP 62050. CUERNAVACA, ELS. (731122314, 127613, 187741. FAX 1731 122434 )r. Jaime Arau RoffielIJefe del Oepto de Electrónico :MAIL [email protected] cenidof

DEDICATORIA
A REYNALDO, VIRGINIA, ANDREA, PERLA, J. REYNALDO Y CECILIA.

AGRADECIMIENTOS
Gracias
A Dios por estar conmigo.
A mis Padres y a mi Abuela por todo su apoyo.
A mis Hermanos Reynaldo y Cecilia.
A Perla por su amor y a su Familia por sus atenciones.
A mi Asesor Carlos Ramírez V. por su orientación.
AI cenidet por permitirme realizar mis estudios de Maestría.
A la SEP y a Conacyt por su apoyo económico.
A mis Revisores: Raúl Fernández, Guillermo Cahue, Tomás Ramírez y Victor M. Cárdenas por su valiosa ayuda.
A mis Profesores.
A mis compañeros.

CONTENIDO
... LISTA DE FIGURAS .......................................................................................... H I
INTRODUCCI~N ................................................................................................. 1
CAPITULO 1 . GENERALIDADES 1 . 1. INTRODUCCIÓN ..................... .................................................................... 2 1.2. SINTESIS DE VOZ ....................................................................................... 3 1.3. ANALISIS WAVELET ................................................................................... 4 1.4. JUSTIFICACIÓN DEL TRABAJO ................................................................. 5 1.5. ALGUNOS TRABAJOS REALIZADOS EN EL TEMA .................................. 6
1.5.1 Análisis por wavelets usado en síntesis de texto a voz ................... 6 1.5.2 Métodos de codificación por segmentos de voz y control del tono para sistemas de síntesis de voz ................................................ 7
1.6. FINALIDAD DEL TRABAJO ......................................................................... 8 1.7. HERRAMIENTAS DE TRABAJO ................................................................. 9
CAPITULO I I . GENERACION DE VOZ 2.1. INTRODUCCIÓN ....................................................................................... 10 2.2. ORGANOS QUE INTERVIENEN EN LA GENERACIÓN DE VOZ ............ 11 2.3. PRODUCCIÓN DE LA VOZ ...................................................................... 12 2.4. PROCESAMIENTO DE VOZ ..................................................................... 13 2.5. INVESTIGACIÓN EN SíNTESlS DE VOZ ................................................ 14 2.6. SíNTESlS POR SEGMENTOS ................................................................. 15 2.7. CONTROL PROSÓDICO .......................................................................... 15 2.8. DETERMINACIÓN DE LA FRECUENCIA FUNDAMENTAL Fo ................ 16
CAPITULO 111 . PROCESAMIENTO DE SEÑALES 3.1. INTRODUCCIÓN ....................................................................................... 19 3.2. CORRELACIÓN DE SEÑALES EN TIEMPO DISCRETO ......................... 20
3.2.1. Funciones de correlación cruzada y autocorrelación ................... 20 3.2.2. Algoritmo para la correlación de dos secuencias ......................... 21
3.3. ANALISIS WAVELET ................................................................................. 22 3.3.1. Transformada Fourier ................................................................... 23 3.3.2. La transformada de Fourier de tiempo corto (STFT) .................... 26 3.3.3. La transformada wavelet continua ................................................ 27 3.3.4. Discretización de la transformada wavelet continua .................... 29
I

3.3.5. La transformada wavelet discreta ..., ............................................ 31 3.3.6. Herramienta de computaci6n ...... : ................................................ 35
CAPITULO IV . METODOLOGíA PARA LA SíNTESlS DE VOZ 4.1, INTRODUCC16N ....................................................................................... 40 4.2. PRINCIPIO PARA LA SlNTESlS DE VOZ ................................................. 41 4.3. PROCESO DE ANALISIS DE SEÑALES DE VOZ .................................... 42
4.3.1. Tipos de sonidos ............................ : ............................................. 42 4.3.2. Selección de micro funciones para análisis .................................. 44
4.3.2.1. Seccionamiento de sonidos vocales ............................... 45 4.3.2.2. Seccionamiento de sonidos sernivocales y nasales ........................................................................................ 46 4.3.2.3. Seccionamiento de sonidos oclusivos ............................ 48 4.3.2.4. Seccionamiento de sonidos fricativos ............................. 49
4.3.3. Extracción del pitch y envolvente ................................................. 50 4.3.4. Análisis de señales de voz ........................................................... 52
4.3.4.1. Análisis por correlación ................................................... 52 4.3.4.2. Análisis por transformada wavelet .................................. 56
4.4. AJUSTE DEL PERIODO "PITCH" PARA LA SlNTESlS (GENE- RACIÓN DE VOZ) ............................................................................................. 60
4.4.1. Concatenación por traslape .......................................................... 61 4.4.2. Concatenación por interpolación .................................................. 64
4.5. METODOLOGiA PROPUESTA PARA LA SiNTESIS DE VOZ ................. 66 4.6. RESULTADOS ........................................................................................... 67
4.6.1. Generación de fonemas y sílabas ................................................ 68 4.6.2. Generación de palabras ............................................................... 69
CAPITULO V . CONCLUSIONES 5.1 CONCLUSIONES ....................................................................................... 71 5.2 TRABAJOS FUTUROS .............................................................................. 72
REFERENCIAS ................................................................................................ 73
APÉNDICE A . DOCUMENTACI~N DE FUNCIONES DE SOFT WARE.........^^ A.1. FUNCIONES PRINCIPALES .................................................................... 78 A.2 FUNCIONES UTILIZADAS POR FUNCIONES PRINCIPALES ................ 80

LISTA DE FIGURAS
Figura 1 . 1. Wavelet descubierto Por Ingrid Daubachies ................................. 5
Figura 1.2. Preparación del diccionario de unidades de síntesis .................... 7
Figura 1.3. Generación de una señal por la superposición de wavelets ......... 8
Figura 2.1. Principales órganos que intervienen en la generación de voz .... I 2
Figura 2.2. Sistema de producción de voz .................................................... 13
Figura 2.3. Detección del pitch por corte central ........................................... 17
Figura 3.1. Algoritmo de la correlación para la rutina spcorr 21
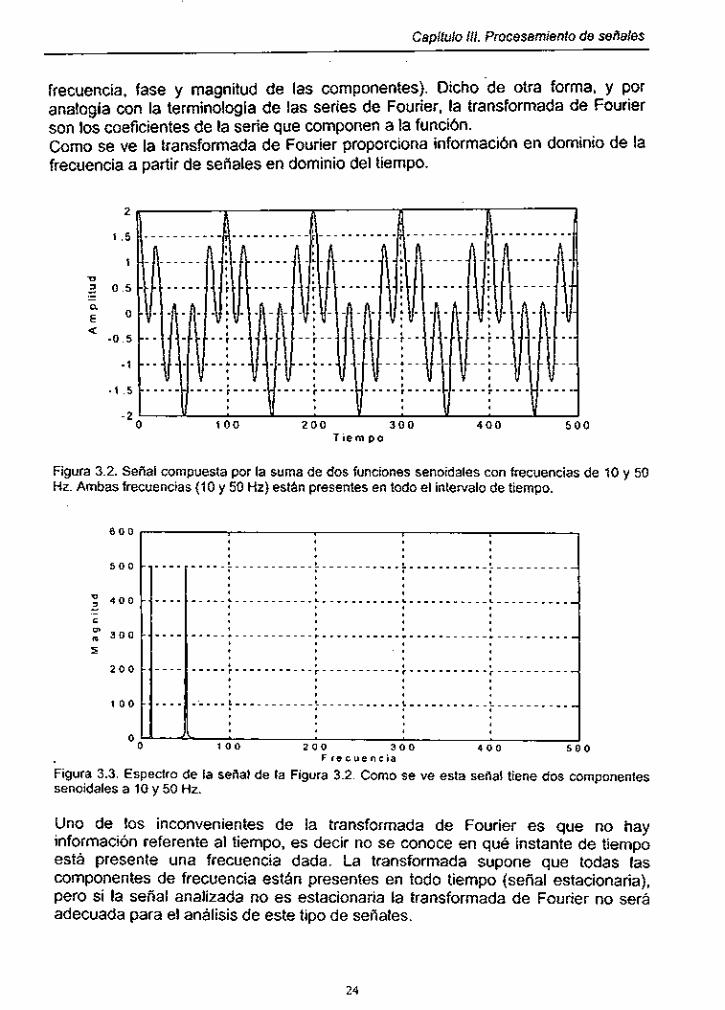
Figura 3.2. Señal compuesta por la suma de dos funciones senoidales con frecuencias de 10 y 50 Hz ...................................................................... 24
Figura 3.3. Espectro de la señal de la Figura 3.2 .......................................... 24
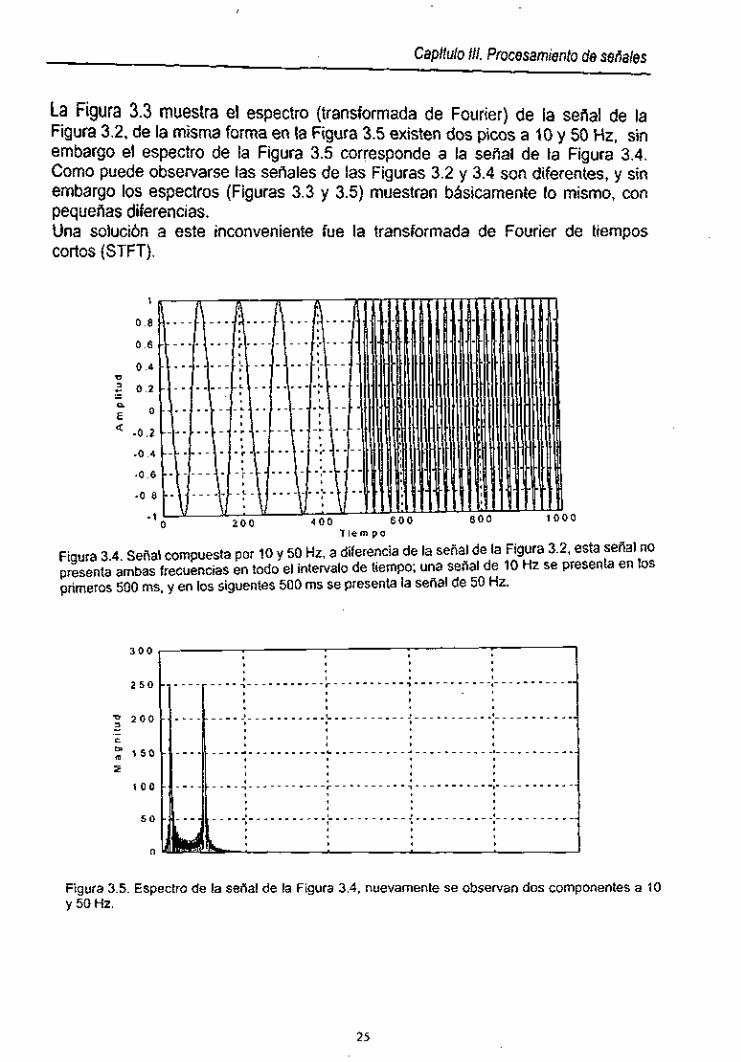
Figura 3.4. Señal no estacionaria compuesta por 10 y 50 Hz ....................... 25
Figura 3.5. Espectro de la señal de la Figura 3.4 .......................................... 25
.........................
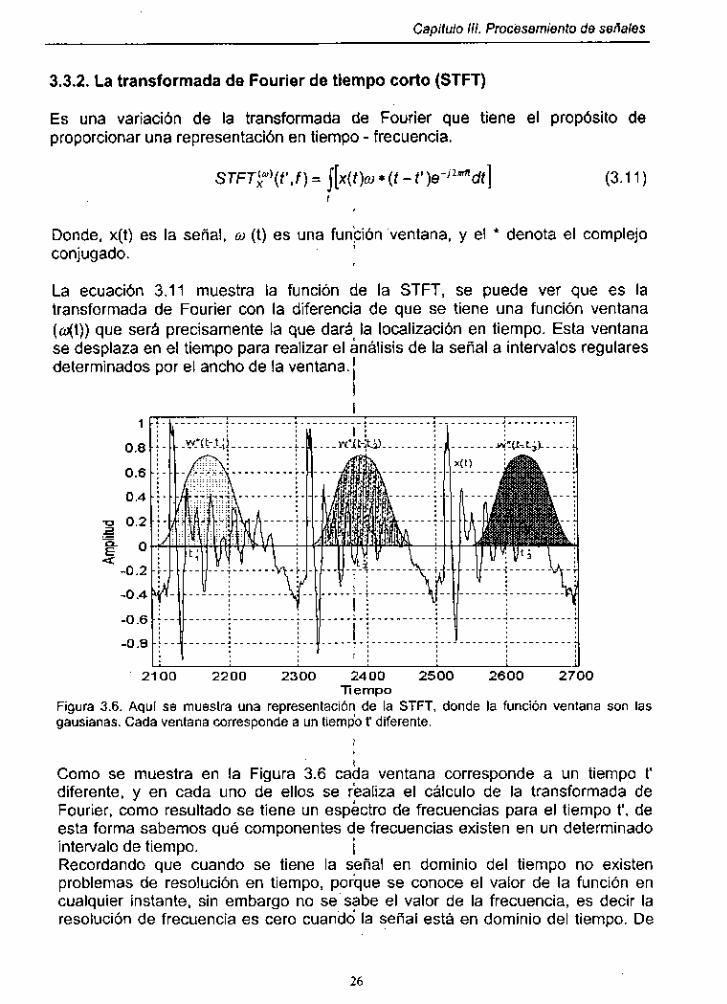
Figura 3.6. Representación de la STFT ........................................................ 26
Figura 3.7. Interpretación de la resolución de tiempo y frecuencia ............... 28
plano discreto de la transformada wavelet .................................................... 30 Figura 3.8. Representación de la escala contra razón de muestre0 en el
Figura 3.9. Algoritmo para la obtención de la DWT ....................................... 33
Figura 3.10. Algoritmo para obtener la DWT inversa .................................... 34
Figura 3.1 1 . Wavelets disponibles en el toolbox ........................................... 36
la síntesis de VOZ ........................................................................................... 41
Figura 4.2. Señal del fonema vocal "a" en dominio del tiempo ..................... 42
Figura 4.3. Forma de onda de los diferentes tipos de sonidos ...................... 43
Figura 4.1. Diagrama a bloques de los pasos para realizar
Figura 4.4. Separación del sonido (sílaba "ME) para extraer micro funciones ................................................................................. 44
Figura 4.5. Fonerna original de una vocal ("a") Con Su micro función elegida para el análisis ........................................................... 45

46 Figura 4.6. Fonema "MA" original ....................... : .......................................... Figura 4.7. Correlación de cada micro función contigua del fonema de "MA" : 46
Figura 4.8. Envolvente de la señal de la figura 4.7 ...................................... 47
Figura 4.9. Fonema semivocal por secciones y micro funciones de cada seccion ............................................................................................ 47
Figura 4.10. Micro funciones para la Sílaba "PO" ........ ~ ................................. 48
Figura 4.1 1 . Micro funciones seleccionadas para una sílaba con sonido fricativo ....................................................................................... 49
Figura 4.1 2 . Diferentes pasos en la detección del pitch ............................... 50
Figura 4.1 3 . Pendientes máximas de un fonema (fonema "E") .................... 51
Figura 4.14. Forma de onda del wavelet Coiflet, generado con la función makewavelet .................................................................................................. 53
Figura 4.15. Correlación entre dos señales .................... : ............................. 53
Figura 4.16. Representación de los máximos o picos resultantes de la correlación con cinco escalas diferentes de wavelets ...... 54
Figura 4.17. Reconstrucción de la señal usando 5 wavelets (5 correlaciones) ........................................................................ 54
Figura 4.18. Señal original contra señal reconstruida ................................. 55
............................................ .........................................
..
Figura 4.19. Fonema "a" sintetizado ........................................................... 55
Figura 4.20. Formas de onda de los wavelets disponibles en el paquete de software Wavelab .......................... ; ...................................... 57
Figura 4.21. Micro función original y coeficientes wavelet .......................... 58
Figura 4.22. Efecto que se produce cuando el período de la micro función base es menor al período pitch de la señal original
Figura 4.23. Forma de obtener micro función base de mayor longitud
Figura 4.24. Distorsión en formas de onda mediante
............. 61
62 ......
.. concatenation por traslape .......................................................................... 63
Figura 4.25. Señal resultante de la concatenación por traslape ................ 63
Figura 4.26. Ajuste de micro función por medio de ¡nterpOlaCiÓn ............... 64
Figura 4.27. Señal resultante del concatenación de micro funciones mediante interpolation ...................................................... 64
iv

Figura 4.28. Diagrama a bloques del proceso de análisis de voz ............ 66
Figura 4.29. Diagrama a bloques del proceso de síntesis ....................... 67
Figura 4.30. Proceso de síntesis para la palabra "casa" ......................... 69
Figura 4.31. Forma de onda de la palabra "casa". sonido original y sonido sintetizado ................................................................................ 70
Figura 4.32. Forma de onda de la palabra "sapo", sonido original y sonido sintetizado ................................................................................ 70
Figura 5.1. Variación de los coeficientes wavelets de cada micro función que forman al fonema "a" .................................................. 72
V

I I
. .
i
En la actualidad existe mayor desarrollo de sistemas de sintesis y reconocimiento de voz en computadoras personales. Las aplicaciones en dichos sistemas son muy variadas, desde diccionarios que nos permiten conocer la pronunciación, hasta sistemas TTS (text-to-speech), que permiten la reproducción automática de voz a partir de un gráfico (texto). La sintesis de voz se apoya en técnicas de procesamiento de señales como en la transformada de Fourier. En años recientes se ha aplicado una nueva técnica de análisis señales con algunas ventajas sobre la transformada de Fourier, esta técnica se basa en el wavelet (ondeletas). En este trabajo se aplican los wavelets al análisis de señales de voz para observar su desempeño y también pretende ser una base para futuros proyectos encaminados al desarrollo de sistemas de síntesis de voz a partir de texto. Este documento se encuentra organizado en cinco capítulos y un apéndice, En el capítulo uno se tratan aspectos generales sobre la síntesis de voz y el proyecto de tesis; la mayor parte del capítulo dos describe cómo se lleva a cabo la generación de voz, el desarrollo de técnicas e investigación en la síntesis de voz. El CaPitulo tres explica las herramientas matemáticas y algoritmos usados en la metodologia propuesta en esta tesis; el capítulo cuatro es el más importante, Puesto que describe el desarrollo del trabajo de tesis, ia forma en que se determinó la metodología propuesta para realizar sintesis de voz, así como
1 también los resultados obtenidos. Por último en el capitulo cinco se mencionan conclusiones del trabajo y se proponen algunos trabajos futuros. Se anexa un apéndice que contiene la documentación de los programas que se desarrollaron con el paquete Matlab, con la idea de utilizarlos como herramienta para posibles trabajos futuros.
I

CapilulO 1. Generalidades
CAPiTULO I GENERALIDADES
1.1. INTRODUCCI~N
En este capítulo se tratan aspectos generales sobre síntesis de voz y el trabajo realizado en esta tesis. Se inicia con el procesamiento de voz, en qué consiste la síntesis de voz y algunas de las técnicas desarrolladas para este fin. Se describe brevemente el análisis wavelet, algunos trabajos realizados sobre el tema, así como también cuál es la finalidad del trabajo de tesis, su objetivo y sus aportaciones. También se menciona la5 herramientas de software utilizadas en el proyecto.
2

v-puuru 1. UUIIUldIIUdUüS
1.2. SíNTESlS DE VOZ
Debido al rápido avance en la capacidad de procesamiento de las computadoras personales y el desarrollo de tecnología multimedia, existe en la actualidad un mayor desarrollo de sistemas de síntesis y reconocimiento de voz en computadoras personales. Las aplicaciones para dichos sistemas son muy variadas, desde diccionarios que nos permiten conocer la pronunciación, hasta sistemas TTS (text-to-speech), es decir, la reproducción automática de voz a partir de un gráfico (texto), resultado de la transcripción de una oración. Por lo anterior y por la aparición de mejores algoritmos para el procesamiento digital de señales, el procesamiento de voz ha tenido un gran desarrollo [I], El procesamiento de voz se puede clasificar según [2] en: análisis, que se encarga de descomponer una señal en sus diferentes componentes; síntesis, que es la formación de una señal a partir de señales básicas; y análisis - síntesis, es decir, un análisis seguido por síntesis, principalmente usado en transmisión de voz de manera comprimida. De esta forma se llama síntesis de voz a la generación artificial de la voz usando señales correspondientes a los fonemas o sílabas. Aún no se conoce la teoría general de cómo el cerebro reconoce la voz O al individuo que habla (reconocimiento de voz); sin embargo, la generación acústica del sonido está mejor comprendida (síntesis). Con las técnicas modernas de procesamiento digital es más fácil duplicar este mecanismo generación. En Io que a síntesis se refiere, existen varias técnicas [3] como son:
Por hardware, la cual tiene dos formas generales. Codificador digital de forma de onda. En este tipo de sistemas el material que se va a reproducir ha sido preparado y almacenado previamente; en su nivel más simple, consta solamente de un convertidor digital-analógico acoplado a un medio de almacenamiento y algún tipo de controlador Para Seleccionar 10 que se va a reproducir. En otros sistemas de este tiPo se aplica alguna técnicas de codificación e incorporan el decodificador necesario para la reproducción de la voz. . Sintetizador analógico - terminal. Es llamado así porque sus características son una analogía de los órganos usados en el habla. Esencialmente es una aproximación matemática del modelo de producción del habla.
Sistemas de respuesta a voz. En estos sistemas el vocabulario es previamente seleccionado y almacenado en memoria, se utiliza algún tipo de codificación. La reproducción se lleva a cabo haciendo una mezcla de palabras y frases almacenadas previamente. Las principales diferencias con respecto a las técnicas anteriores son: se utiliza una mayor cantidad de memoria, la complejidad del hardware para la decodificación es mayor y existe una mejora en la calidad de la voz sintetizada.
Es uno de los sistemas de síntesis mas utilizados, empezando con un texto escrito como entrada y la producción de habla de aceptable calidad como salida. El texto escrito puede ser una representación fonética del habla o en casos mas ambiciosos lenguaje escrito convencional. Este último proceso
Sistemas por regla.
3

Capitulo I. Generalidades I
puede ser dividido en dos subprocecoc: traducci6n de gráfico a fonema y traducción de fonema al habla. La traducción del fonema al habla presenta los siguientes problemas:
1.Cómo seleccionar alófonos apropiados (dos o más formas del mismo fonema). 2.CÓmo unir sonidos en forma natural. 3.Cómo proporcionar tono y ritmo a la oración.
La síntesis basada en sistemas TTS básicamente se centra en dos problemas: el procesamiento natural del lenguaje y el procesamiento digital de señales [4]. El primero debe ser capaz de producir transcripción fonética correcta del texto, incluyendo entonación y ritmo, por otro lado la parte de procesamiento digital de señales debe adecuar la transformación de estos símbolos a voz digitalizada. Puesto que este trabajo pretende ser parte de un sistema TTS, se puede clasificar dentro de la síntesis de sistemas por regla. A mediados de la década de los 80’s como resultado de los avances en las investigaciones sobre este tema apareció el concepto de síntesis TTS de alta calidad. Las aplicaciones son diversas, como en la telefonía, sistemas multimedia, ayuda a discapacitados, juguetes, comunicación hombre-máquina, etc.
1.3. ANALISIS WAVELET
Los wavelets son señales de corta duración y que se pueden manipular para modificar su duración y amplitud, de esta forma, al sumarse con otros wavelets obtenemos señales muy semejantes a las originales. Para algunas aplicaciones es deseable ver a la transformada wavelet (por sus siglas en ingles WT) como la descomposición de una señal en un grupo de funciones básicas, en este caso las funciones básicas son llamadas wavelets [5]. Este análisis tiene muchas aplicaciones en lo que se refiere a procesamiento digital de señales. Actualmente se están utilizando los wavelets para el análisis de señales; ya que presenta ventajas sobre el análisis de Fourier, principalmente para análisis de señales no periódicas y discontinuas [6]. Cuando una señal se representa mediante señales senoidales (análisis de Fourier) se emplean tantos coeficientes de la serie como necesitemos que se acerque a la señal original, con los wavelets se necesitan menos coeficientes para representar a la misma señal (dependiendo también de la señal a analizar), esto representa una clara ventaja de la eficiencia del análisis wavelet sobre el análisis de Fourier [7]; Otra ventaja es que los wavelets tienen localización en tiempo por lo que las señales discontinuas son
.mejor representadas, además de que el algoritmo para calcular la transformada wavelet es más rápido, debido a que se realiza un menor número de operaciones matemáticas.
A
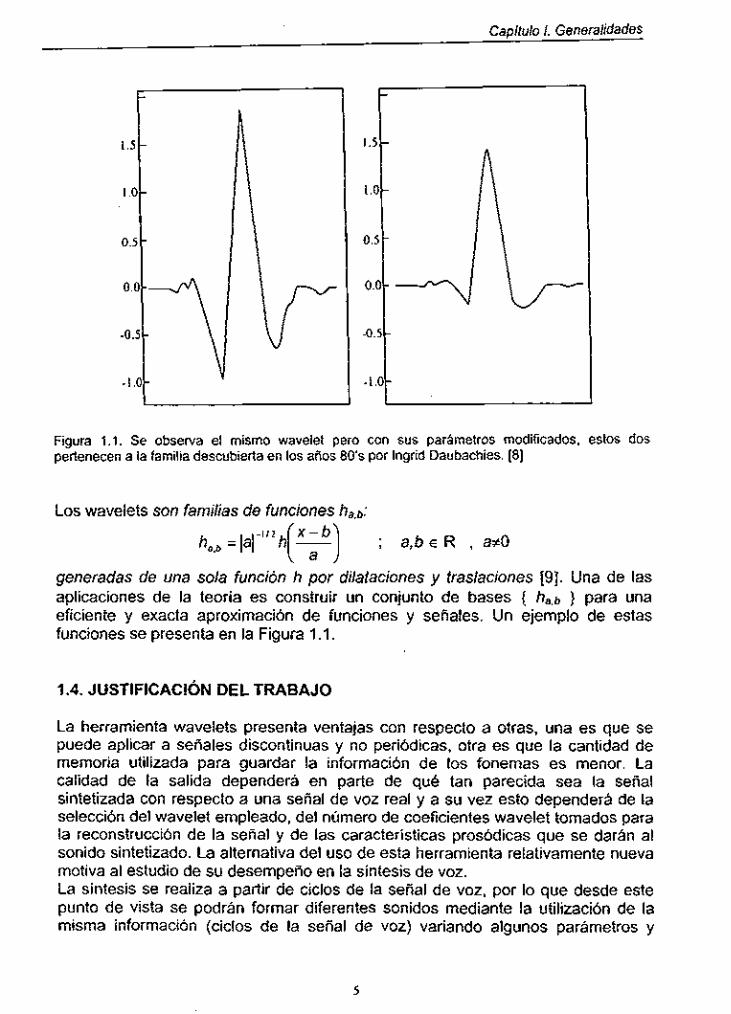
Capítulo l . Generalidades
Figura 1.1. Se observa el mismo wavelet pero con sus parámetroc modificados, estos doc pertenecen a la familia descubierta en los años 80's por Ingrid Daubachiec. [8]
Los wavelets son familias de funciones ha,b:
; a,bE R , a#O = Ial-''2h(a) x - b
generadas de una sola función h por dilataciones y traslaciones [9]. Una de las aplicaciones de la teoría es construir un conjunto de bases { ha,b } para una eficiente y exacta aproximación de funciones y señales. Un ejemplo de estas funciones se presenta en la Figura 1 .I.
1.4. JUSTIFICACIÓN DEL TRABAJO
La herramienta wavelets presenta ventajas con respecto a otras, una es que se puede aplicar a señales discontinuas y no periódicas, otra es que la cantidad de memoria utilizada para guardar la información de los fonemas es menor. La calidad de la salida dependerá en parte de qué tan parecida sea la señal sintetizada con respecto a una señal de voz real y a su vez esto dependerá de la selección del wavelet empleado, del número de coeficientes wavelet tomados para la reconstrucción de la señal y de las características prosódicas que se darán al sonido sintetizado. La alternativa del uso de esta herramienta relativamente nueva motiva al estudio de su desempeño en la síntesis de voz. La síntesis se realiza a partir de ciclos de la señal de voz, por lo que desde este punto de vista se podrán formar diferentes sonidos mediante la utilización de la misma información (ciclos de la señal de voz) variando algunos parametros y
5

Caplfulo I . Generalidades
concatenando con otros ciclos de voz correspondientes a otros sonidos (se podrá sintetizar diferentes sílabas a partir de la unión de diferentes ciclos, variando el tono y amplitud de la sella1 de voz) y como resultado se tendrá una menor cantidad de información para reproducir un sonido sintetizado.
1.5. ALGUNOS TRABAJOS REALIZADOS EN EL TfiMA
A continuación se exponen dos trabajos de investigación realizados con diferentes técnicas utilizando wavelets.
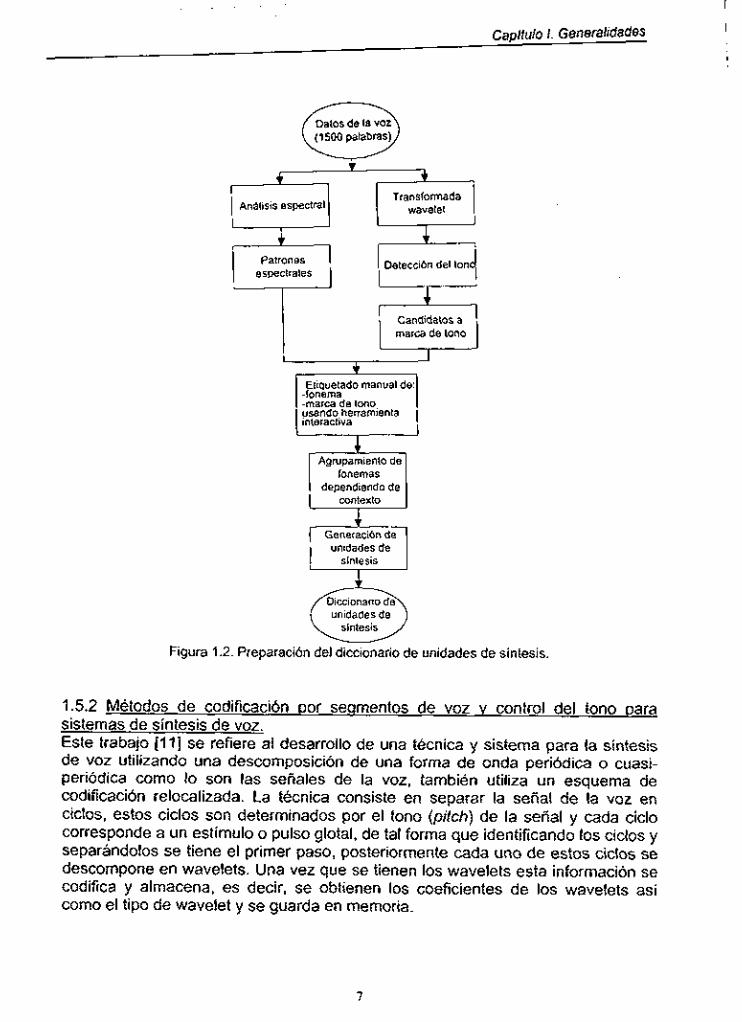
1.5.1 Análisis Dor wavelets usado en síntesis de texto a voz. En el primer trabajo que analizaremos [ IO ] se desarrollaron cuatro nuevas tecnologías para mejorar la calidad de la voz sintetizada del sistema. Las tecnologías desarrolladas fueron: determinación precisa del tono (pitch) por análisis de wavelets, generación de formas de onda usando un método modificado de tono síncrono de traslape-suma en dominio del tiempo, unidad de selección de síntesis de voz usando el método de agrupamiento dependiente del contexto y un eficiente control prosódico usando analizador sintáctico de tres frases. La síntesis fue hecha para el idioma japonés y se elaboró un diccionario de sonidos básicos (fonemas) a partir de 1500 palabras en texto leídas por oradores profesionales. Los datos grabados son analizados para separar los fonemas y etiquetados, también se determina el tono exacto (pitch) mediante el análisis por wavelets. Esto se basa en determinar el momento del cierre glotal, calculando la transformada wavelet de la forma de onda de la voz y tomando el período del pico máximo de la transformada se determina el período de los impulsos glotales, este dato servirá posteriormente para realizar la síntesis. Otra tecnología desarrollada fue la de clasificar los sonidos dependiendo del contexto, es decir se tiene un diccionario con los sonidos de las sílabas pero también dependen de la sílaba anterior y de la siguiente. De esta forma se tienen nuevas combinaciones de los sonidos que formarán el diccionario. La preparación de las unidades de síntesis para el diccionario se esquematiza en la Figura 1.2. Lo descrito anteriormente fue para la creación del diccionario, la forma en que se realiza la síntesis se describe a continuación. Se tiene un control prosódico usando un analizador sintáctico de tres frases, en el cual se examinan tres frases adyacentes y se determinan parámetros prosódicos como acentuación, pausas, conexión neutral, etc. Por Último se tiene un método modificado de tono síncrono de traslape-suma en dominio del tiempo ( TD-PSOLA ). La función de este método es producir la señal sintetizada a partir de la mezcla de los diferentes elementos previamente seleccionados que forman parte del diccionario, además de proporcionar cierta suavidad al habla. Esto se lleva a cabo separando la señal original en pequeñas secuencias y traslapándolas mediante una ventana Hanning. Esta ventana debe ser sincronizada con el instante de excitación en cada periodo del tono y además la ventana de la señal de voz debe conservar sus propiedades espectrales. Por lo anterior es importante la determinación exacta del periodo del tono.
I
1 I Capitulo 1. Generabdades
Analisis espectral
i Patrones
espectrales
Transformada wavelet -
i
4 Detección del tona
Candidatos a marca de tono -
---- AgNpamiento de fonemas
dependiendo de contexto
Generación de unidades de
sintesis
unidades de
Figura 1.2. Preparación del diccionario de unidades de sintesis.
1.5.2 Métodos de codificación por seqmentos de voz Y control del tono Dara sistemas de síntesis de voz. Este trabajo [I I] se refiere al desarrollo de una técnica y sistema para la sintesis de voz utilizando una descomposición de una forma de onda periódica o cuasi- periódica como lo son las señales de la voz, también utiliza un esquema de codificación relocalizada. La técnica consiste en separar la señal de la voz en ciclos, estos ciclos son determinados por el tono (pitch) de la señal y cada ciclo corresponde a un estímulo o pulso glotal, de tal forma que identificando los ciclos y separándolos se tiene el primer paso, posteriormente cada uno de estos ciclos se descompone en wavelets. Una vez que se tienen los wavelets esta información se codifica y almacena, es decir, se obtienen los coeficientes de los wavelets asi como el tipo de wavelet y se guarda en memoria.
7
Capitulo l. Generaiidades
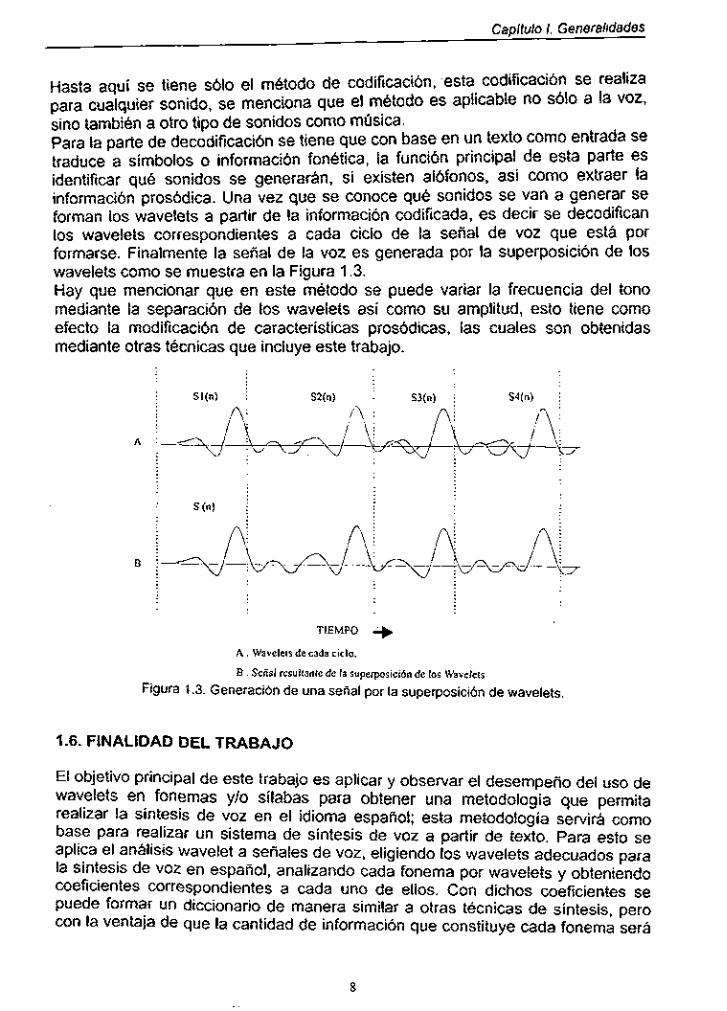
Hasta aquí se tiene ~610 el método de codificación, esta codificación se realiza para cualquier sonido, se menciona que el método es aplicable no sólo a la VOZ, sino también a otro tipo de sonidos como música. Para la parte de decodificación se tiene que con base en un texto como entrada se traduce a símbolos o información fonética, la función principal de esta parte es identificar qué sonidos se generarán, sí existen al6fonos, así como extraer la información prosódica. Una vez que se conoce qué sonidos se van a generar se forman los wavelets a partir de la información codificada, es decir se decodifican los wavelets correspondientes a cada ciclo de la señal de voz que está por formarse. Finalmente la señal de la voz es generada por la superposición de los wavelets como se muestra en la Figura 1.3. Hay que mencionar que en este método se puede variar la frecuencia del tono mediante la separación de los wavelets así como su amplitud, esto tiene como efecto la modificación de características prosódicas, las cuales son obtenidas mediante otras técnicas que incluye este trabajo.
TIEMPO + A . Wavelets de cada ciclo.
B . Señal resultante de la superposición de los Wavelets
Figura 1.3. Generación de una sena1 por la superposición de wavelets.
1.6. FINALIDAD DEL TRABAJO
El objetivo principal de este trabajo es aplicar y observar el desempeño del uso de wavelets en fonemas y/o sílabas para obtener una metodología que permita realizar la síntesis de voz en el idioma español; esta metodología servirá como base para realizar un sistema de síntesis de voz a partir de texto. Para esto se aplica el análisis wavelet a señales de voz, eligiendo los wavelets adecuados para la síntesis de voz en español, analizando cada fonema por wavelets y obteniendo coeficientes correspondientes a cada uno de ellos. Con dichos coeficientes se puede formar un diccionario de manera similar a otras técnicas de síntesis, pero con la ventaja de que la cantidad de información que constituye cada fonema será
8

1 Capitulo l . Generalidades
menor, de hecho en los sistemas de síntesis existentes no se hace mucho énfasis en la forma de almacenar los componentes del diccionario de fonemas, como en (121 y como ejemplo se puede mencionar que para almacenar la sílaba "Sa" se necesitan 12000 bytes de memoria en el formato PCM, mientras que por la metodología propuesta se necesitan 4025 bytes. Se definirán reglas de concatenación de los fonemas. La aportación de este trabajo es proponer un método para realizar síntesis de voz usando wavelets; observar los resultados de la aplicación de los wavelets, y determinar si es un buen método para este fin; tener una base para estudios posteriores y contribuir en la linea de investigación de procesamiento digital de señales del cenideí ! con la asimilación del análisis por wavelets.
1.7. HERRAMIENTAS DE TRABAJO
El desarrollo de este proyecto se realizó utilizando una computadora personal con tarjeta de sonido, sistema operativo Windows 95. El software de programación fue Matlab ver. 4.2, además del toolbox de análisis wavelet Wavelab versión 7. Toda la programación se llevó a cabo en Matlab.
9

CAPITULO II GENERACIÓN DE VOZ
2.1. INTRODUCCI~N
La mayor parte del capitulo dos está dedicado a profundizar sobre aspectos de generación artificial de la voz, no sin antes describir la forma en que se lleva a cabo la generación de voz en el cuerpo humano y los Órganos que intervienen en ello. La investigación en la síntesis de voz a llevado a la aplicación de técnicas como la síntesis por segmentos y al desarrollo de algunas formas de extraer caracteristicas propias de la voz así como también de su control, como en el caso de las características prosódicas y el tono o "pitch". De este último describimos algunas de las formas existentes para la detección. Estas características de la voz son importantes debido a que de ellas dependen la inteligibilidad y la naturalidad.
IO

Cap/tu/o /l. Generacdn de VOZ I
2.2. ORGANOS QUE INTERVIENEN EN LA GENERACI~N DE VOZ
~1 sistema generador de voz, se divide en tres Partes [I311 1) pulmones y tráquea 2) laringe 3) tracto vocal
LOS pulmones y la tráquea son la fuente de poder del sistema, la laringe Contiene el mecanismo principal de generación de sonido y el interior de la boca modula el sonido resultante. Los órganos vocales funcionan usando el aire comprimido proporcionado por los pulmones y entregado al sistema por medio de la tráquea. Estos órganos también controlan la sonoridad de la voz resultante, pero no hacen una contribución audible a la voz. Los pulmones se encuentran encerrados en una cámara hermética llamada pleura, la cual está rodeada por sus lados de costillas, y por abajo del diafragma. Los pulmones son expandidos y comprimidos, de esta forma atraen y exhalan gases cambiando el tamaño de la pleura. El diafragma es un músculo en la parte baja de las costillas que cuando se contrae presiona el aire en los pulmones, cuando se relaja regresa a su forma normal y el proceso es el inverso. La tráquea tiene aproximadamente 12 cm de largo por 2 cm de diámetro, une a los pulmones y a la laringe. La tráquea y los pulmones juntos constituyen el tracto pulmonar. La laringe consta de un complicado sistema de cartílagos y músculos que contienen y controlan las cuerdas vocales. Cuando en su parte final las cuerdas están separadas, se dice que están abiertas, y es ésta la posición para la respiración, el espacio entre las cuerdas vocales se llama glotis. Cuando el final de las cuerdas está cerrado proporcionan un sello hermético que no permite el paso al tracto pulmonar, pero sí permite el paso at estómago. La función acústica de las cuerdas vocales es proporcionar una fuente de excitación para producir la voz. El tracto vocal es un sistema compuesto por muchas partes como son: epiglotis, mandíbula, lengua, velo, paladar, dientes y labios. Cada una de estas partes cumplen una función biológica, pero además, tienen una función en el habla. Mediante el movimiento de los músculos y tejidos cambian la forma del interior de la boca, que tiene como consecuencia la modulación del flujo de aire proveniente de la glotis.
9 9 - 0 6 1 9

i I Capitulo /I Generacdn de VOZ
I
- Pulmones
Diafragma
Figura 2.1, Principales 6rganos que intervienen en la generación de voz,
2.3. PRODUCCIÓN DE LA VOZ [I41
La operación del sistema como un conjunto es dividida en dos funciones: excitación y modulación; la mayor parte de la excitación tiene lugar en la glotis, mientras que la modulación es realizada por varios órganos del tracto vocal. La excitación puede ser de varios tipos, la más importante es la fonación, que consiste en la oscilación de las cuerdas vocales cuando el aire es forzado a pasar por ellas, vibrando como los labios de una trompeta. La apertura y cierre de las cuerdas rompe el flujo de aire y produce ondas de presión, la forma de estas ondas y su ciclo se reflejan en aspectos como sonoridad, tono, voz con respiración, etc. La razón de repetición de los pulsos es llamada "pitch" y es controlado principalmente por la tensión en las cuerdas vocales y regulado por retroalimentación a través de los oídos y el cerebro. Desde el punto de vista fisiológico, el sonido es modulado por el movimiento de los Órganos del habla (principalmente la lengua) para cambiar la calidad de la voz y para interponer sonidos adicionales o interrupciones en la voz. Acústicamente, la principal razón de la modulación es la operación de filtrado. La forma de onda glotal es muy rica en armónicos, y el tracto vocal, como cualquier tubo acústico tiene frecuencias naturales las cuales son una función de su forma. Estas resonancias son las formas más importantes de modular la voz.
12

Capitulo If. Generación de VOZ
Excitaci6n Modulaci6n (glotis) (tracto vocal) Radiada
Figura 2.2. Sistema de producci6n de voz
2.4. PROCESAMIENTO DE VOZ
Las investigaciones en procesamiento de voz y comunicaciones en un Principio fueron motivadas por el deseo de construir modelos mecánicos para emular la capacidades de comunicación verbal humana [I 51. Uno de los primeros intentos fue, un aparato mecánico-mímico, que emula el aparato vocal humano, realizado por Wolfgang Von Kempelen y que es descrito en un libro publicado en 1791; Mas tarde, 40 años después Charles Wheatstone, construyó una máquina basado en las especificaciones de Kempelen, en esta máquina emula los 6rganos que intervienen en la generación de la voz mediante dispositivos mecánicos, por ejemplo, un fuelle hace la función del pulmón, las cuerdas vocales son reemplazadas por lengüetas colocadas al final de un tubo flexible (el tracto vocal), cuya área transversal puede variar, para producir varios sonidos. Posteriormente ya en el siglo XX, Helmholz, Miller, Koenig, y otros siguieron otro principio, ellos sintetizaron sonidos de vocales superponiendo armónicas de senoides con los ajustes apropiados de amplitud. La visión de los investigadores en voz hoy en día es mayor debido a los avances en las herramientas matemáticas (algoritmos), computación, y todas las aplicaciones potenciales de procesamiento de voz en las comunicaciones modernas y en redes de computadoras.
13

1 I i
Capitulo II Generacibn de VOZ
2.5. INVESTIGACIÓN EN SíNTESIS DE voz 1161
Generación de voz es el proceso que permite la transformación de una cadena de simbolos fonéticos y prosódicos en una setiai de VOZ sintética. La calidad resultante depende tanto de la calidad de la cadena. como del proceso de generación [17]. La calidad de la voz sintetizada en 10s sistemas texto a VOZ se relaciona con dos criterios, el primero la inteligibilidad, la cual puede ser medida tomando en cuenta algunas clases de unidades (fonemas, silabas, palabras, frases). La segunda y más dificil de definir, es frecuentemente descrita como naturalidad. Actualmente el concepto de naturalidad se refiere al concepto de realismo en el campo de la sintesis de imágenes: La meta no es restituir la realidad, pero si sugerir esta. AS¡, escuchando una voz sintética debemos permitir al escucha atribuir esta voz a un pseudo orador y percibir alguna clase de expresión tan bien como algunas características del estilo del orador y la situación particular de elocución. Para este propósito debe ser proporcionada información lingüística extra al sistema. La mayoría de los sistemas texto a voz producen una aceptable inteligibilidad, pero la naturalidad, la habilidad del control de expresión, estilo de voz y la identidad del pseudo orador es pobre. En los años recientes de la sintesis, los esfuerzos de los investigadores fueron dirigidos principalmente a simular los mecanismos humanos de producción de voz, usando modelos básicos de articulación basados en teorías electroacústicas. Aunque este modelado es aún una de las principales metas en la investigación de la síntesis, avances en las ciencias de la computación han ampliado el campo de la investigación hasta incluir síntesis de texto a voz, en la cuál se modelada la generación de voz y también se procesa texto. Como este modelado es generalmente hecho por un conjunto de reglas derivadas de teorías fonéticas y de análisis acústico, la tecnología es típicamente referida como síntesis de voz por regla. La síntesis por regla ha alcanzado una calidad altamente inteligible y puede servir en muchos usos prácticos; esta calidad se ha logrado por la alternación del análisis de características de la voz con el desarrollo de reglas de control. Sin embargo, la mayoria de estos progresos han sido sistemas dependientes y permanecen profundamente incrustados dentro de la arquitectura en impenetrables redes de reglas detalladas y de parámetros finamente sintonizados. Como consecuencia, el conocimiento para desarrollar sistemas de síntesis similares no está disponible y puede ser muy difícil reproducirlo en sistemas equivalentes por otros investigadores. En contraste a este método basado en reglas, también se ha desarrollado un método basado en corpus’, en el cual se tienen conjuntos de datos de voz bien definidos a varios niveles con información, tal como etiquetas acústico-fonéticas Y marcado sintáctico, para seguir como fundamento para un modelado estadístico. Parámetros espectrales y características prosódicas de los datos de voz se analizan en relación a la información etiquetada; basados en los resultados de
Corpus. Conjunto lo más extenso y ordenado posible de datos o textos cientiflcos. literarios, etc., que pueden servir de I
base a una investigación [is].
14

este análisis, se crea un modelo computacional que es entrenado usando el corpus. Por medio de la aplicación subsecuente de datos de prueba (entrenamiento) se valida el modelo resultante y cualquier defecto puede ser mostrado cuantitativamente para realizar mejoras adicionales al modelo en un proceso iterativo. Este procedimiento caracteristico, formalizado del método basado en corpus, proporciona una clara formulación empírica de los controles fundamentales de la voz, con su procedimiento especifico de entrenamiento y con su resultado objetivo de la evaluación; asi que puede ser reproducido por otros investigadores para otras bases de datos de corpus de voz equivalentes.
2.6. SíNTESlS POR SEGMENTOS [I91
En los sistemas texto a VOZ se utilizan unidades más pequeñas que las palabras, típicamente se hace un modelado en sílabas, fonemas, o pares de fonemas. Las características espectrales de un segmento de voz varían dependiendo del: contexto fonético, cómo es influido por fonemas vecinos, estrés y diferencias de posición de este último. Sin embargo, aunque en la sintesis por regla tradicional las unidades de voz incluyen las variaciones fonéticas, no se han realizado estudios sistemáticos para determinar cómo y dónde es mejor extraer los parámetros acústicos de las unidades o que clase de corpus de voz puede considerarse Óptimo. Con el objetivo de tener una técnica para la generación apropiada de unidades de voz, la síntesis por selección de unidades ha sido propuesta en [20], [21] y [22]. Las unidades pueden ser determinadas automáticamente a través del análisis del corpus de voz, usando una medida de entropia2 entre las subcadenas de etiquetas de sonidos (las etiquetas se subdividen). En la selección de unidades de síntesis, se toman en cuenta medidas objetivas que indican el adecuado grado contextual, así como también la suavidad y las transiciones espectrales dentro y entre las unidades. A diferencia de la concatenación en la sintesis por regla, los segmentos de voz no están limitados a un símbolo (etiqueta fonética) por tipo de unidad, además son usados varios tipos y tamaños de unidades. De esta forma se seleccionan unidades ÓDtimas aue correspondan a una cadena fonética de entrada de una base de datos de voz para generar voz de salida.
2.7. CONTROL PROSÓDICO [23]
Para obtener naturalidad en la calidad del sonido en la sintesis de voz es necesario el control prosódico, para asegurar el correcto ritmo, tiempo, acento, entonación y estrés. El control de duración de segmento se necesita para modelar caracteristicas temporales y el control de frecuencia fundamental se necesita para
2 Enlropia. Medida de incertidumbre eliminada por el conocimiento de cierta información con base a una probabilidad

1 Capltulo If. Generacibn de VOZ
características tonales. En contraste a la relativa escasez en trabajos de voz en generación de unidades, muchos análisis cuantitativos se han llevado a cabo para el control prosódico. Específicamente, análisis cuantitativos y modelado de control de duración de segmentos se han realizado para muchos lenguajes usando corpus de voz masivos. Para generar una curva adecuada de la frecuencia fundamental (Fo) cuando sólo es dado texto como entrada. necesita ser especificada una estructura prosódica _ _ --. intermedia y para ello es necesario un procesamiento del texto. Como en el caso del control de duración, en los primeros modelos de reglas para el control de Fo fueron hechas independientemente sólo por la reunión de análisis de las características de Fo. Sin embargo, recientemente se han empleado modelos estadísticos para asociar patrones de FO con entradas de información lingüística directamente, sin requerir estimar la estructura prosódica intermedia.
2.8. DETERMINACIÓN DE LA FRECUENCIA FUNDAMENTAL Fo (PITCH) [24]
Las señales de voz se componen de muchos armónicos de frecuencias, llamados formantes. El armónico principal, frecuencia fundamental o pitch es de crucial importancia, ya que determina cierta periodicidad en la voz. La determinación del pitch es muy importante tanto en el reconocimiento como en la síntesis de voz, debido a que forma parte de las características prosódicas que definen la calidad de la síntesis en nuestro caso. Aunque la determinación exacta del pitch en las señales de voz es un problema que no se ha resuelto totalmente, existen muchas formas de determinarlo; a continuación mencionamos algunas de ellas. Uno de los primeros métodos fue simplemente un filtro pasa baja para remover todos los armónicos y después medir la frecuencia fundamental por medios convenientes. Pero este método tiene dos inconvenientes. El primero, puesto que el pitch puede cubrir fácilmente uno o dos rangos, el filtro debe asegurarse de permitir el paso de la frecuencia fundamental y rechazar el segundo armónico. El segundo problema está en que el pitch se tiene que detectar, en muchos casos, de voz con calidad telefónica. La respuesta de frecuencia de un canal telefónico cae abruptamente debajo de 300 Hz, por lo que para voces masculinas la frecuencia fundamental está ausente o es muy débil. En una función periódica la autocorrelación puede mostrar un máximo en un retraso igual al periodo de la función; sin embargo la voz no es exactamente periódica debido a los cambios de pitch y de los formantes, lo que es un problema para la detección del pitch mediante la autocorrelación. El principal problema con la autocorrelación, es que la primera formante puede interferir con la fundamental, así que se han desarrollado técnicas para tener un espectro de amplitud plana y así todos los armónicos tengan esencialmente el mismo tamaño, para lo anterior se tienen algunas técnicas [25].
Filtrado adaptativo. En este método se tiene un banco de filtros pasa banda a través de los cuales se filtrada la señal. Cada filtro cubre aproximadamente 100 Hz y tiene un control automático de ganancia, la función de los filtros es la de
I Capitulo I I . Generacibn de VOZ
obtener un espectro plano, posteriormente las salidas son autocorrelacionadas para obtener una estimación del pitch (261.
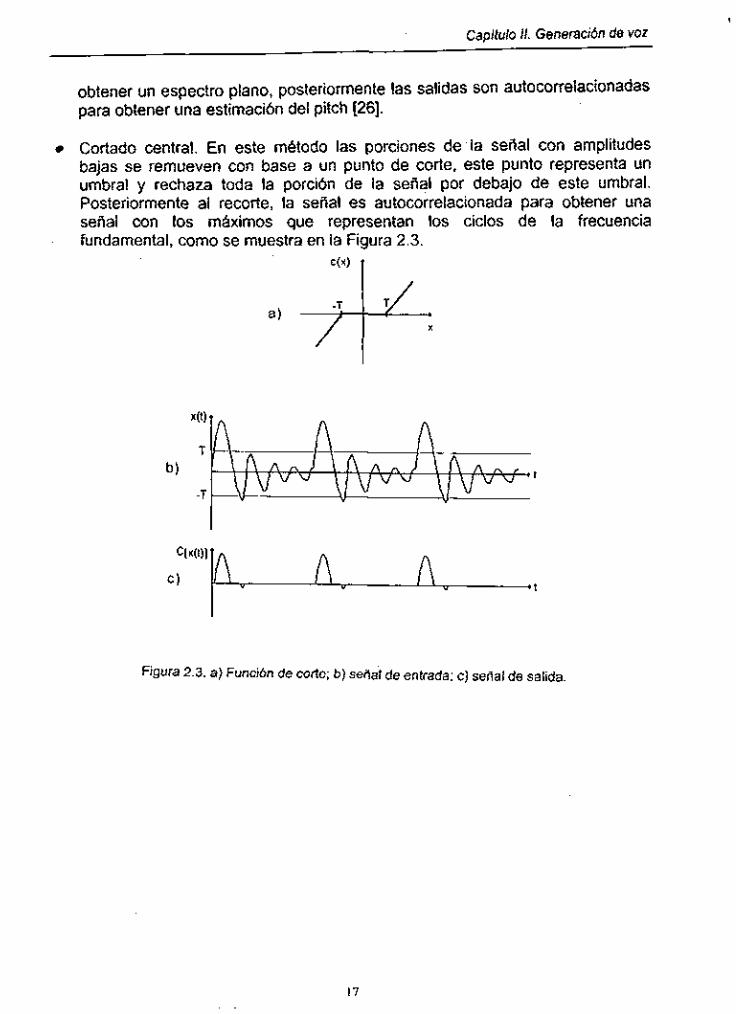
Cortado central. En este metodo las porciones de la señal con amplitudes bajas se remueven con base a un punto de corte, este punt0 representa un umbral y rechaza toda la porción de la señal por debajo de este umbral. Posteriormente al recorte, la señal es autocorrelacionada para obtener una señal con los máximos que representan los ciclos de la frecuencia fundamental, como se muestra en la Figura 2.3.
Figura 2.3. a) Función de corte; b ) cefial de entrada: c) seiíal de salida,
17

Capitulo I / . Generaci6n de voz
El Cepstrum. Es la transformada de Fourier del logaritmo de su espectro de potencia; es otro método bastante poderoso para la obtención de un espectro plano. Este se deriva del modelo de excitación - modulación del tracto vocal. El espectro de voz esta dado por:
X(f) = G(f)H(f)
Donde G(f) es el espectro de la excitación glotal y H(f) es la función de transferencia del tracto vocal. Si tomamos el logaritmo del espectro de potencia, podemos transformar estos componentes multiplicativos en aditivos.
T ( f ) = 2lnlX(f] = 2[lnlG(f)l+InlH(f)/]
Note que T(f) consta de dos componentes, un componente de variación lenta el cual corresponde al espectro de la envolvente y una componente de variación rápida la cual corresponde a los picos de armónicos del pitch. Estos componentes pueden separarse por filtrado o tomando la segunda transformada de Fourier. Así el cepstrum queda expresado como [27]:
C(q) = FF(f)J = 2F(ln/G(f)/+InlH(f)I)
Análisis en dominio del tiempo. Algunos investigadores han intentado determinar la frecuencia fundamental por análisis detallado de la forma de onda misma. En 1969 Gold y Rabiner [28] propusieron un detector de pitch, el cual usa los atributos de la forma de onda como son las mediciones de las amplitudes de los picos positivos y negativos, las posiciones de pico a pico y de pico a valle. Las mediciones se efectuaron después de procesar la señal por un filtro pasa baja de 600 Hz. Miller [29] menciona que cada período de pitch está caracterizado normalmente por una excursión que es significativamente más grande que sus vecinas, estas excursiones son llamadas ciclos principales; antes se hace una reducción de datos por medio de un filtro pasa bajo y se identifican los ciclos de mayor potencia con base a criterios de cruce por cero y área bajo la curva. Estas técnicas se mencionan con más detalle en [24].

Capitulo 111. Procesamiento de seilales
CAPITULO 111 PROCESAMIENTO DE SEÑALES
3.1. INTRODUCCI~N
El objetivo principal de este capitulo es explicar en qué consisten las herramientas matemáticas y algoritmos usados en la metodología propuesta para realizar la síntesis de voz. Iniciamos describiendo la operación de correlación entre señales, en un principio se pretendía usar la correlación para implementar la transformada wavelet, aunque finalmente se utilizó la transformada wavelet incluida en un paquete de software; también se utilizó esta operación en el seccionamiento de fonemas, como se verá en el siguiente capítulo. Posteriormente se explica el análisis wavelet; para lo cual se considera necesario iniciar con una explicación del análisis de Fourier, debido al parecido de estos dos tipos de análisis y a que, en principio, es más conocido el análisis de Fourier. Se parte de la serie de Fourier para seguir con la transformada y su caso particular la transformada de Fourier de tiempo corto; posteriormente explicamos la transformada wavelet continua para llegar al caso discreto. Finalmente se explica el algoritmo para el cálculo de la transformada wavelet discreta.
19

Caplfulo 111. Procesamiento de seriales
3.2. CORRELACIdN DE SENALES EN TIEMPO DISCRETO
La correlación entre dos señales es una medida de la similitud entre éstas. Es una operación muy empleada en el procesamiento de señales con diferentes aplicaciones como son radar, sonar, transmisión de datos y muchas más. En aplicaciones como radar se tiene una señal transmitida x(n) y una señal recibida y(n), si existe un objeto en el área de búsqueda la señal recibida y(n) será una versión retrasada de x(n), puesto que es una señal reflejada por algún objeto y distorsionada por el ruido w(n), por otra parte si no existe ningún objeto la señal y(n) consistirá solamente de ruido. Lo anterior se puede expresar mediante la ecuación 3.1 [30].
y(n) = ax(n - d ) + w(n) (3.1 1
Donde aes un factor de atenuación y d representa el atraso de la señal recibida. El problema en la detección por radar y sonar consiste en comparar la señal transmitida x(n) con la señal recibida y(n), para determinar si existe un objeto y si así es debe determinarse el retraso d. del cual se puede calcular la distancia del objeto. La correlación es una importante herramienta para revelar la existencia o ausencia de la señal reflejada, tomando en cuenta que en la práctica la identificación de la señal no es tan sencilla pues la señal reflejada puede estar contaminada por ruido.
3.2.1. Funciones de correlación cruzada y autocorrelación
Dadas dos secuencias de energía finita x[n] e y[n], la correlación cruzada entre ellas se define por la ecuación 3.2 1311.
Donde I representa el atraso, el subíndice xy en la secuencia de correlación cruzada rxv[& representa las secuencias que son correlacionadas. El orden de los subindices, x precedido por y. indica la dirección de desplazamiento de una secuencia con respecto a otra. Si el orden de las secuencias x[n] e y[n] en la ecuación 3.2 se invierten, obtenemos la ecuación 3.3
Comparando la ecuación 3.2 y 3.3 se concluye que:
rxy 111 = ryr [-I1
(3.3)
(3.4)
20

i Capltulo 111. Procesamiento de serlales I
I La ecuación 3.4 dice que, con respecto a la similitud entre ambas secuencias la información proporcionada por r,& y rvx[/l es la misma. Cuando la secuencia x[n]=y[n], la función de correlación se expresa como la ecuación 3.5, y recibe el nombre de autocorrelación.
3.2.2. Algoritmo para la correlación de dos secuencias
En este trabajo se elaboró una rutina que realizará la función de correlación entre dos señales. El algoritmo utilizado calcula el producto punto de dos secuencias (señales) n veces (donde n = longitud de los vectores de entrada), con un desplazamiento de una muestra entre cada una de las operaciones del producto punto. La Figura 3.1 explica mejor la operación para dos secuencias (x[n] e y[n]) cada una con una longitud de cinco muestras. Para cada iteración se realiza el producto punto entre las dos secuencias, después de la primera iteración se introduce un cero en la última muestra de la secuencia y[n] y el primer valor de dicha secuencia se descarta; esta operación tiene el propósito de realizar el corrimiento en tiempo de la secuencia.
xc[n] - Valor
descartado y? y2 y3 y4 y5 O
Figura 3.1. Algoritmo de la correlación para la rutina spcorr.
21

Capitulo 111. Procesamiento oe senafes
La siguiente es la sintaxis de la funci6n SPCorr:
xc = spcorr ( x. y)
x = señal a correlacionar. Longitud =n. y = señal a correlacionar. Longitud =n.
xc = función de correlación entre x e y.
Sintaxis:
Entradas:
Salidas:
Comentarios: Los vectores x e y deben ser de la misma longitud. El vector resultante xc tiene la misma longitud que x e y.
3.3. ANÁLISIS WAVELET
Las transformadas son poderosas herramientas matemáticas para el análisis de sistemas, señales y funciones; en el caso de señales, el análisis consiste en la extracción de información que generalmente no se aprecia en su forma natural. Las señales de voz se encuentran en dominio del tiempo, como la mayoría de las señales en la práctica, sin embargo algunas veces es necesario conocer las componentes de frecuencia, por lo que se requiere de una transformación lineal al dominio de la frecuencia. En el campo de la ingeniería son ampliamente utilizadas una variedad de transformadas lineales, una de las más usadas es la transformada de Fourier y recientemente la transformada wavelet. El punto central de esta tesis es aplicar el análisis wavelet a señales de voz, por lo que a continuación se explica en qué consiste, pero antes es pertinente hacer mención del análisis de Fourier puesto que se relaciona en gran parte con el análisis wavelet. Joseph Fourier estableció que una función periódica f(t) puede ser representada como una serie trigonométrica [32], siempre y cuando cumpla con ciertas condiciones. Así se tiene que:
m 1 f(f)=-a, +C(a,cosno,t+b, sennw,t) (3.6)
2 “=I
donde: W, = 2 n l T
T i 2
a, = - j f( f) cos(nw,t )df 7- -7-12
22

Capitulo 111. Procesamiento de seilales
2 b, = -- If(t)sen(no,t)dt
T -Ti2
n = 1,2,3, ...
Una serie representada como en la ecuación 3.6 se llama serie trigonométrica de Fourier [33] y a cada elemento de la serie se le llama armónico. Conceptualmente la representación de una función mediante series de Fourier es la representación de dicha señal como la combinación lineal de un conjunto de funciones bases, en este caso senoidalec, es decir, se representa una función mediante la suma de componentes senoidales de diferentes frecuencias (armónicos) y con diferentes amplitudes. Es necesario que el conjunto de funciones base (senoidales) sean ortogonales entre ellas y, además, que la función a ser representada por series de Fourier cumpla con las condiciones de Dirichlet.
3.3.1. Transformada Fourier
El concepto anterior se puede extender para encontrar la representación de una señal no periódica como una combinación lineal de exponenciales complejas relacionadas armónicamente y es de aquí de donde se parte para obtener la transformada de Fourier [34]. La serie de Fourier de la ecuación 3.6 puede ser expresada en forma compleja como:
i
De estas ecuaciones se obtiene la ecuacion que permite calcular la Transformada de Fourier, ecuación 3.9, as¡ como también la transformada inversa, ecuación 3.10.
(3.9)
(3.10)
La transformada de Fourier de una señal no periódica se conoce como el espectro de la función f(t), ya que proporciona la información acerca de qué componentes senoidales y de qué frecuencia forman a f(t) (proporciona información de la
23
Capltulo 111. Procesamiento de senales
frecuencia, fase y magnitud de las componentes). Dicho -de otra forma, y por analogla con la terminología de las series de Fourier, la transformada de Fourier son los coeficientes de la serie que componen a la función. Como se ve la transformada de Fourier proporciona información en dominio de la frecuencia a partir de señales en dominio del tiempo.
T i e m p o
Figura 3.2. Seilal compuesta por la suma de dos funciones senoidales con frecuencias de 10 y 50 Hz. Ambas frecuencias (10 y 50 Hz) están presentes en todo el intervalo de tiempo.
Figura 3.3. Espectro de la seilal de la Figura 3.2. Como se ve esta seilal tiene dos componentes senoidales a 10 y 50 Hz.
Uno de los inconvenientes de la transformada de Fourier es que no hay información referente al tiempo, es decir no se conoce en qué instante de tiempo está presente una frecuencia dada. La transformada supone que todas las componentes de frecuencia están presentes en todo tiempo (señal estacionaria), pero si la señal analizada no es estacionaria la transformada de Fourier no será adecuada para el análisis de este tipo de señales.
24
Capltulo 111. Procesamiento de senales
La Figura 3.3 muestra el espectro (transformada de Fourier) de la señal de la Figura 3.2, de la misma forma en la Figura 3.5 existen dos picos a 10 y 50 Hz, sin embargo el espectro de la Figura 3.5 corresponde a la señal de la Figura 3.4. Como puede observarse las señales de las Figuras 3.2 y 3.4 son diferentes, y sin embargo los espectros (Figuras 3.3 y 3.5) muestran básicamente lo mismo, con pequeñas diferencias. Una solución a este inconveniente fue la transformada de Fourier de tiempos cortos (STFT).
Figura 3.4. Señal compuesta por 10 y 50 Hz, a diferencia de la señal de la Figura 3.2, esta señal no presenta ambas frecuencias en todo el intervalo de tiempo; una sena1 de 10 Hz se presenta en los primeros 500 ms. y en los siguentes 500 ms se presenta la seilal de 50 Hz.
3 0 0
2 5 0
2 0 0 - ._ c
1 5 0
I
1 0 0
5 0
n
Figura 3.5. Espectro de la serial de la Figura 3.4, nuevamente se observan dos componentes a 10 y 50 Hz.
25
Capítulo 111. Procesamiento de sedales
3.3.2. La transformada de Fourier de tiempo corto (STFT)
Es una variación de la transformada de Fourier que tiene el propósito de proporcionar una representación en tiempo - frecuencia.
ST iTg) ( t ' , f ) = j [x ( t )w * ( t - t')e-'2ddt] (3.11) t
Donde, x(t) es la señal, w (t) es una funpón 'ventana, y el * denota el complejo conjugado.
La ecuación 3.11 muestra la función de la STFT, se puede ver que es la transformada de Fourier con la diferencia de que se tiene una función ventana (o(t)) que será precisamente la que dará la localización en tiempo. Esta ventana se desplaza en el tiempo para realizar el análisis de la señal a intervalos regulares determinados por el ancho de la ventana. 1
I I
21 O 0 2200 2300 2400 2500 2600 2700 Tempo
Figura 3.6. Aqui se muestra una representación de la STFT, donde la función ventana son las gausianas. Cada ventana corresponde a un tiempo t' diferente.
Como se muestra en la Figura 3.6 caida ventana corresponde a un tiempo t' diferente, y en cada uno de ellos se realiza el cálculo de la transformada de Fourier, como resultado se tiene un espectro de frecuencias para el tiempo t', de esta forma sabemos qué componentes de frecuencias existen en un determinado
Recordando que cuando se tiene la señal en dominio del tiempo no existen problemas de resolución en tiempo, poique se conoce el valor de la función en cualquier instante, sin embargo no se sabe el valor de la frecuencia, es decir la resolución de frecuencia es cero cuando la señal está en dominio del tiempo. De
intervalo de tiempo. i
26

Capítulo Ill. Procesamiento de senales
manera similar, cuando la señal está en dominio de la frecuencia se conoce la magnitud a cualquier frecuencia, pero no en qué instante sucede, es decir la resolución del tiempo cuando la seilal está en dominio de la, frecuencia es cero. Cuando se usa la STFT la función ventana dice qué en determinado rango o intervalo de tiempo existe tal banda de frecuencias, así que ahora la resolución del tiempo cuando la señal está en dominio de la frecuencia ya no es cero. Esta resolución depende del ancho de la ventana, es decir entre más estrecha sea la ventana, mayor será la resolución en tiempo, sin embargo la resolución en frecuencia es baja, pues sólo se toma una pequeña porción de la señal, en la cual posiblemente no estén componentes de frecuencias bajas. Es as¡ como el ancho de la ventana establece un compromiso, si la ventana es estrecha, la resolución en tiempo es buena, pero la resolución en frecuencia es pobre; y si la ventana es ancha, la resolución en frecuencia es buena, pero la resolución en tiempo es pobre. Este inconveniente podría ser superado si el ancho de la ventana pudiera variarse, pero uno de los problemas de la STFT es precisamente que el ancho de la ventana permanece fijo, cosa que no sucede en la transformada wavelet, pues el ancho de la ventana es variable. LOS problemas de resolución en el análisis de señales son un fenómeno físico que se explica por el principio de incertidumbre de Heisenberg [351 [36l. Para mayores detalles de la STFT se puede Consultar [VI.
3.3.3. La transformada wavelet continua
Un wavelet es una forma de onda oscilatoria que persiste sólo por uno o pocos ciclos y tiene la característica de presentar localización (posición) y una escala (duración) [38]. La transformada wavelet continua (CWT) surgió como un método de análisis que supera los problemas que presenta la transformada de Fourier de tiempo corto. La transformada wavelet continua utiliza un método llamado análisis de multiresolución (MRA) [39], el cual consiste en analizar una señal a diferentes frecuencias con diferentes resoluciones, por lo que con MRA tenemos buena resolución en tiempo y pobre resolución en frecuencia para altas frecuencias y buena resolución en frecuencia y pobre resolución en tiempo para bajas frecuencias.
C W : ( t , s ) = Y~(z ,s ) = k(tk *,,s (t)dt (3.12)
(3.13)
El análisis de la CWT es similar al de STFT, en el sentido de que se utiliza una ventana que multiplica a la señal; esta ventana, llamada wavelet, es desplazada
21
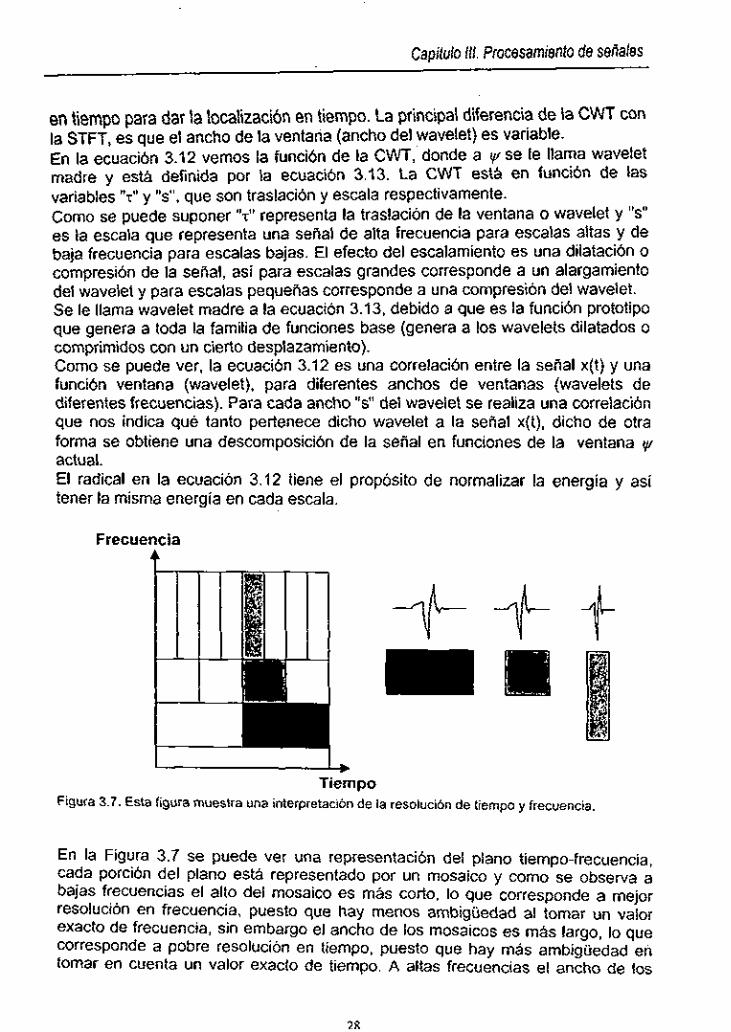
Capitulo 111. Procesamiento de seilales
en tiempo para dar la localizaci6n en tiempo. La principal diferencia de la CWT con la STFT, es que el ancho de la ventana (ancho del wavelet) es variable. En la ecuación 3.12 vemos la función de la CWT, donde a se le llama wavelet madre y está definida por la ecuación 3.13. La CWT está en función de las variables "K" y "s", que son traslación y escala respectivamente. Como se puede suponer "K" representa la traslación de la ventana o wavelet y "s" es la escala que representa una señal de alta frecuencia para escalas altas y de baja frecuencia para escalas bajas. El efecto del escalamiento es una dilatación o compresión de la señal, así para escalas grandes corresponde a un alargamiento del wavelet y para escalas pequeñas corresponde a una compresión del wavelet. Se le llama wavelet madre a la ecuación 3.1 3, debido a que es la función prototipo que genera a toda la familia de funciones base (genera a los wavelets dilatados o comprimidos con un cierto desplazamiento). Como se puede ver, la ecuación 3.12 es una correlación entre la señal x(t) y una función ventana (wavelet), para diferentes anchos de ventanas (wavelets de diferentes frecuencias). Para cada ancho "s" del wavelet se realiza una correlación que nos indica que tanto pertenece dicho wavelet a la señal x(t), dicho de otra forma se obtiene una descomposición de la señal en funciones de la ventana actual. El radical en la ecuación 3.12 tiene el propósito de normalizar la energía y así tener la misma energía en cada escala.
Frecuencia 4
- Tiempo
Figura 3.7. Esta figura muestra una interpretación d e la resolución d e tiempo y frecuencia.
En la Figura 3.7 se puede ver una representación del plano tiempo-frecuencia, cada porción del plano está representado por un mosaico y como se observa a bajas frecuencias el alto del mosaico es más corto, lo que corresponde a mejor resolución en frecuencia, puesto que hay menos ambigüedad al tomar un valor exacto de frecuencia, sin embargo el ancho de los mosaicos es más largo, lo que corresponde a pobre resolución en tiempo, puesto que hay más ambigüedad en tomar en cuenta un valor exacto de tiempo. A altas frecuencias el ancho de los
2R

Capitulo Ill. Procesamrento de senales
mosaicos decrece, es decir, la resolución en tiempo aumenta y el alto de los mosaicos se incrementa, lo que indica que la resoluci6n en frecuencia es pobre. También se puede observar la escala del wavelet para cada largo del mosaico; cada mosaico en la Figura 3.7 corresponde a un valor de la CWT, por lo que todos los puntos que caen dentro de un mosaico son representados por un valor de la CWT. La ecuación 3.14 muestra la transformada inversa wavelet continua, para esto es necesario satisfacer la ecuación 3.15. La CWT es reversible aunque la función base puede no ser ortonormal.
(3.14)
La reconstrucción de x(t) depende de la constante c,,, (constante de admisibilidad) y el valor de ella se relaciona con el wavelet usado.
Donde p({)es la transformada de Fourier de dt). La ecuación 3.15 implica que p(0) = O , lo cual significa:
(3.15)
(3.16)
Como establece la ecuación 3.16 esta es una condición que puede cumplir muchas funciones wavelet, sólo es.necesario que su integral sea cero.
3.3.4. Discretización de la transformada wavelet continua
Hasta aquí se ha visto la transformada wavelet continua, pero es necesario un análisis para el plano discreto, que al igual que sus similares como la transformada discreta de Fourier se pueda implementar en computadora para hacer más práctico el cálculo de análisis y síntesis. Una forma intuitiva de pasar al plano discreto la transformada wavelet es realizar un muestreo directamente del plano tiempo-frecuencia. Sin embargo, el cambio de escala en la WT puede ser utilizado para reducir la razón de muestreo; es decir de acuerdo con el teorema de Nyquist a bajas frecuencias la razón de muestreo puede decrecer. En otras palabras, la porción del plano tiempo-frecuencia que contiene bajas frecuencias puede tener una razón de muestreo más baja que la porción del plano tiempo-frecuencia que contiene las frecuencias más altas. La consideración anterior tiene como ventaja una reducción en el número de operaciones a realizar en el cálculo de la transformada wavelet.
29
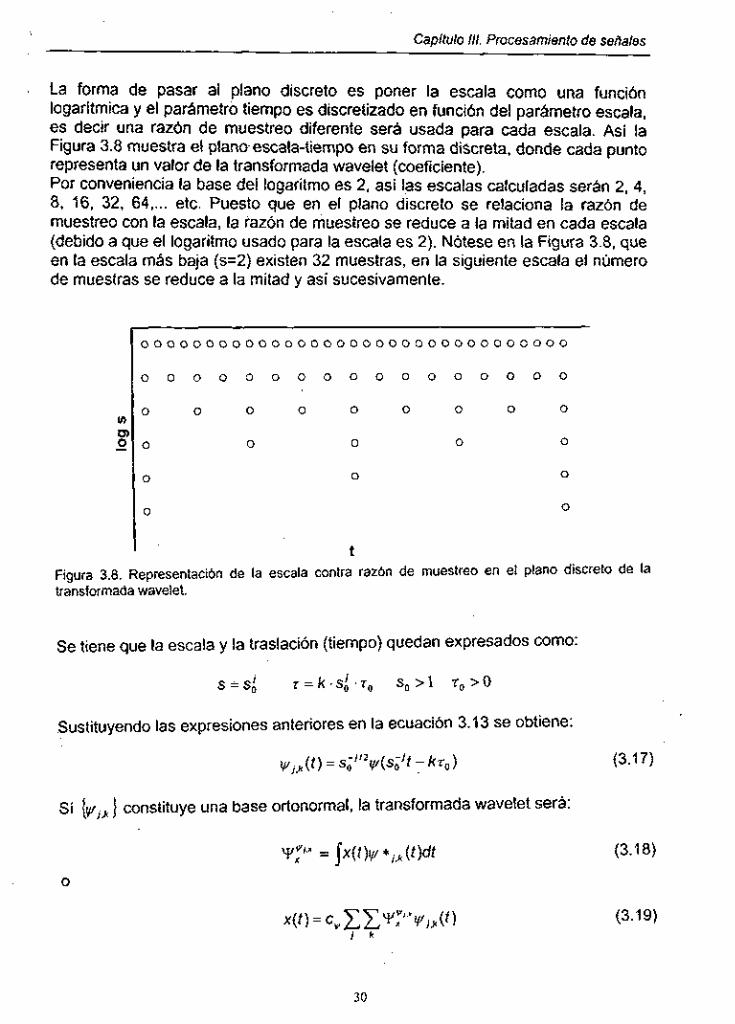
Capítulo 111. Procesamienfo de señales
I La forma de pasar al plano discreto es poner la escala como una función logaritmica y el parámetro tiempo es discretizado en función del parámetro escala, es decir una razón de muestreo diferente será usada para cada escala. Así la Figura 3.8 muestra el planoescala-tiempo en su forma discreta, donde cada punto representa un valor de la transformada wavelet (coeficiente). Por conveniencia la base del logaritmo es 2, as¡ las escalas calculadas serán 2, 4, 8, 16, 32, 64, ... etc. Puesto que en el plano discreto se relaciona la razón de muestreo con la escala, la razón de muestreo se reduce a la mitad en cada escala (debido a que el logaritmo usado para la escala es 2). Nótese en la Figura 3.8, que en la escala más baja (s=2) existen 32 muestras, en la siguiente escala el número de muestras se reduce a la mitad y as¡ sucesivamente.
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
O
0
O
O
Figura 3.8. Representación de la escala contra razón de muestreo en el plano discreto de la transformada wavelet.
Se tiene que la escala y la traslación (tiempo) quedan expresados como:
S = S ; z = k . s i . 7 , , S,>1 r O > Q
Sustituyendo las expresiones anteriores en la ecuación 3.13 se obtiene:
v,,k(t) = si’’*v(so’t - kc,)
Si {v,,~} constituye una base ortonormal, la transformada wavelet sera:
Y? = b(t)v*i,k(t)df
O
(3.17)
(3.18)
(3.19)
30

Capitulo 111. Procesamiento de serlales
En resumen el cambio de escala utilizado en la I ransformada es aprovechado para reducir la razón de muestreo, puesto que es suficiente cumplir con el teorema de Nyquist. La operación anterior implica una reducción en el número de operaciones realizadas en el cálculo y una mayor eficiencia del algoritmo. Por conveniencia se tiene que la variación de la escala está en función logaritmica (base 2); además como se expreso anteriormente la traslación en tiempo es función de la escala. Para un estudio más a fondo puede consultarse [40] y [41].
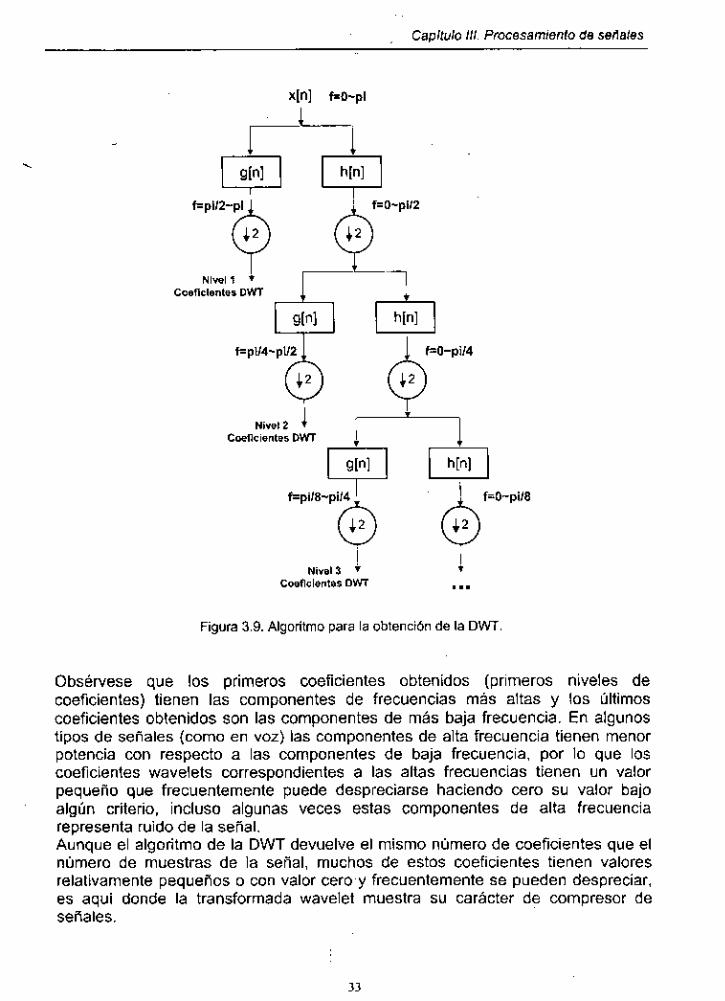
3.3.5. La transformada wavelet discreta
Los fundamentos de la transformada wavelet discreta (DWT) tienen sus bases en esquemas tales como la codificación de sub-banda 1421 y el análisis de multiresolución [39]. Como se ve en la ecuación 3.12, la CWT es la correlación entre un wavelet a diferentes escalas y la señal, usando la escala como una medida de similaridad. La CWT se calcula cambiando la escala de la ventana, desplazando la ventana en el tiempo, multiplicando la señal por la ventana e integrando cada producto de la señal por la ventana. En el caso de la transformada discreta, filtros de diferentes frecuencias de corte se usan para analizar la señal a diferentes escalas. La señal se pasa a traves de una serie de filtros pasa alta para analizar altas frecuencias y por una serie de filtros pasa baja para analizar las bajas frecuencias. La resolución de la señal, la cual es una medida de la cantidad de información detallada en la señal, es cambiada por las operaciones de filtrado, y la escala es cambiada por una operación de sobre muestreo o sub muestreo (esta última operación también conocida como diezmado). La operación de filtrado corresponde a la convolución de la señal con la respuesta al impulso del filtro. La ecuación 3.20 corresponde a la operación de convolución.
m
~ [ n ] * h[n] = C ~ [ k ] . h[n - k] k=-m
(3.20)
Sí se expresa la frecuencia de señales discretas en función de radianes y además para generalizar la explicación a cualquier frecuencia se hace una normalización de la frecuencia de muestreo a 2n radianes, la componente de frecuencia más alta que puede existir en una señal es de n radianes, si la razón de muestreo de la setial está de acuerdo con el teorema de Nyquist. Cuando la señal pasa por un filtro pasa baja de media banda, la mitad de las muestras de la señal resultante del filtrado pueden ser descartadas de acuerdo al teorema de Nyquist y ahora la señal tendrá la componente más alta de frecuencia a un máximo de n12 radianes en lugar de n radianes; por lo que se realiza un diezmado por 2, descartando una muestra y dejando sin cambio otra muestra, así que ahora se reduce a la mitad el número de muestras que anteriormente se tenía. Resumiendo: la operación del filtro pasa baja removió la alta frecuencia y además cambió la resolución (se redujo a la mitad la resolución), por otra parte la operación de diezmado reduce a la mitad el número de muestras de la señal y
31

Capitulo 111. frocesarn/ento de seirales
además cambia la escala (ahora está al doble). Esto puede ser expresado en la ecuacibn 3.21.
(3.21)
La DWT emplea dos conjuntos de funciones, llamadas de escalamiento y wavelet, las cuales están asociadas con filtros pasa baja y pasa alta, respectivamente. La descomposición en bandas de frecuencias de la señal se obtiene por la operación de filtrado pasa alta y pasa baja de la señal en dominio del tiempo. La señal x[n] pasa primeramente por filtros de media banda pasa alta g[n] y pasa baja h[n]. Despues del filtrado la mitad de las muestras puede ser eliminada de acuerdo al teorema de Nyquist y este proceso constituye un nivel de descomposición expresado por las ecuaciones 3.22 y 3.23, donde Yhigh e YI,, son las salidas de los filtros posteriormente al diezmado por 2.
(3.22)
(3.23)
La Figura 3.9 explica el procedimiento del cálculo de la DWT. Como se muestra la Señal x[n] con una banda de frecuencia de O a ÍT se filtra por h[n], que divide la banda de frecuencia de la señal ahora de O a 7d2, para después diezmar las muestras por 2; por otra parte g[n] divide la banda de frecuencia de d 2 a n para posteriormente diezmarla y obtener el primer nivel de coeficientes wavelets. El procedimiento se repite hasta que el número de muestras sea 2. Los niveles de coeficientes se unen para obtener un vector de igual longitud a la señal analizada x[n]* dicho vector contiene los coeficientes wavelets de la señal.
32
.
Capitulo 111. Procesamiento de serlales
Nivel 1 1 Coeficientes DWT
Nivel 2 Coeficientes DWT
I Nivel 3 T
Coeficientes DWT ... Figura 3.9. Algoritmo para la obtención de la DWT.
Obsérvese que los primeros coeficientes obtenidos (primeros niveles de coeficientes) tienen las componentes de frecuencias más altas y los últimos coeficientes obtenidos son las componentes de más baja frecuencia. En algunos tipos de señales (como en voz) las componentes de alta frecuencia tienen menor potencia con respecto a las componentes de baja frecuencia, por lo que los coeficientes wavelets correspondientes a las altas frecuencias tienen un valor pequeño que frecuentemente puede despreciarse haciendo cero su valor bajo algún criterio, incluso algunas veces estas componentes de alta frecuencia representa ruido de la señal. Aunque el algoritmo de la DWT devuelve el mismo número de coeficientes que el número de muestras de la señal, muchos de estos coeficientes tienen valores relativamente pequeños o con valor cero y frecuentemente se pueden despreciar, es aquí donde la transformada wavelet muestra su carácter de compresor de señales.
33
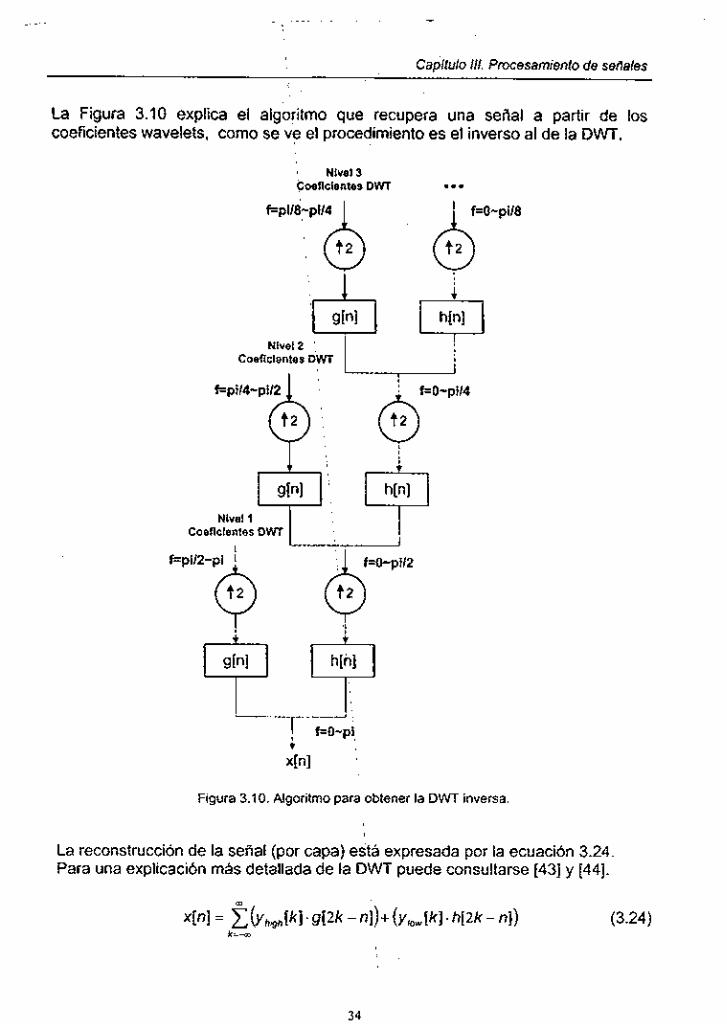
I Capifuio 111. Procesamiento de seriales
La Figura 3.10 explica el algoritmo que recupera una señal a partir de los coeficientes wavelets, como se ve el procedimiento es el inverso al de la D W .
1 1 1, Nivel3 Coeflcientes DWT ...
I f=o-pi/a
Nivel 2 j
I 1
Coeflcientes DWT
Nivel 1 Coeflclentes D W
Figura 3.10. Algoritmo para, obtener la DWT inversa
I
La reconstrucción de la señal (por capa) está expresada por la ecuación 3.24 Para una explicación más detallada de la DWT puede consultarse [43] y [44].
m
mi = c G/,,,wI. g w - ni)+ (Y,,,,[~I. w - 4) (3.24) k = a ,
34

Capítulo 111. Procesamienfo de seiiaíes
Cada nivel del algoritmo de la transformada wavelet está compuesto por dos filtros media banda pasa baja (h[n]) y pasa alta (g[n]), estos filtros se conocen como Filtros espejo de cuadratura (QMF) y son filtros del tipo FIR. Para una mayor explicación consúltese [43] y [45]. Los filtros pasa baja y pasa alta no son independientes uno del otro, su relación está expresada por la Ecuación 3.25.
g[L - 1 - n] = (-l)”h[n] (3.25)
Donde g[n] es el filtro pasa alto, h[n] el pasa bajo y L es la longitud del filtro en número de puntos. Como se mencionó antes h[n] y g[n] se relacionan con dos funciones llamadas de escalamiento y wavelet, respectivamente. Estas funciones están representadas por una serie que se compone de coeficientes y de funciones base (wavelets). La operación de filtrado es la convolución de la señal con los coeficientes que componen dicha serie; pa’ra mayor detalle véase [46].
3.3.6. Herramienta de computación
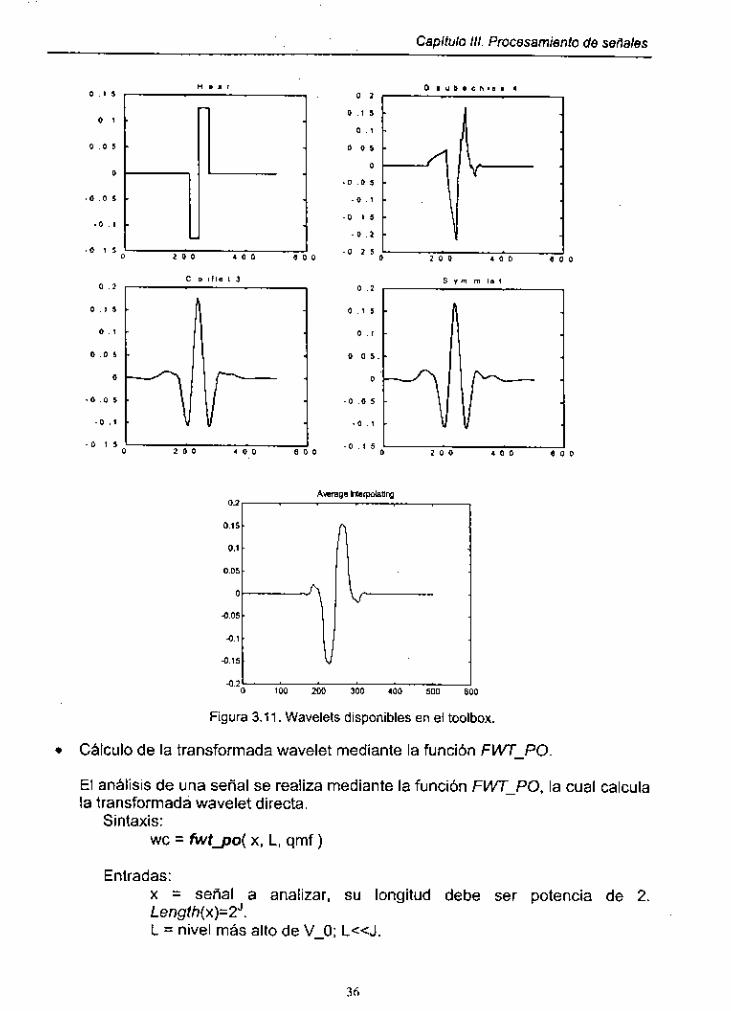
Los algoritmos de DWT y DWT inversa están implementados en módulos de programas (funciones) incluidos en el paquete de software Toolbox Wavelab ver. 0.700, que se ejecutan bajo el ambiente de MATLAB. El software Toolbox Wavelab es un conjunto de librerías que utiliza el análisis wavelet, paquetes wavelet, paquetes cosenoidales, etc.; este Toolbox se obtiene en la dirección: http://playfair.stanford.edu/-wavelab. El conjunto de wavelets (funciones base) para el análisis y síntesis de señales disponible en este software son los wavelets Haar, Coiflet, Daubechies, Symmlet y el wavelet de interpolación promedio. A continuación mostramos gráficamente estos wavelets.
35
CapMulo 111. Procesamiento de senales - L . o . o 5
- 0 . I
0.2
0.15.
0.1
0.05.
O
0.05.
4 . 1
0 .15 .
0 . 2
. r b-
-
J
I 2 0 0 4 0 0 6 0 0
o 2
o . I 5
o . 1
o . o 5
o
. o . o 5
- 0 . I
. o . I 5
. o . 2
- 0 2 5
s " r n m I* t
o . o 5 .
O
- 0 . o 5
. o ol'-Li4 . o ., . I 5 o Z O O 4 0 0 6 0 0
36

Caolfulo 111. Procesamiento de serlales
qmf = Filtro espejo de cuadratura (ortonormal).
Salidas: wc = transformada wavelet de x.
Comentarios: 1. El filtro qmf se puede obtener de la función MakeOnFilter. 2. Generalmente la longitud del filtro se expresa como:
Lengfb(qmf)<2(L+’).
Otra función para el cálculo de la transformada wavelet es la función FWT - A/. Sintaxis:
wc = fwf-ai(x,L,D,F,EF)
Entradas: x = Señal a analizar, su longitud debe ser potencia de 2. Lengtb(~)=2~. L = Nivel más alta; L-J. D = Grado del polinomio para la interpolación promedio. F = Filtro creado por la función makeaifi/ter. EF = Filtro de borde creado por la función makeaibdryfifer.
Sa I i d a s : wc = transformada wavelet de x.
Cálculo de la transformada wavelet inversa.
La síntesis de una señal se realiza mediante la función /WT-PO, la cual calcula la transformada wavelet inversa.
Sintaxis:
Entradas: x = iwtpo( wc, L, qmf )
wc = coeficientes de la transformada wavelet. Su longitud debe ser potencia de 2. Lengtb(~)=2~. L = nivel más alto de V-O; L<<J. qmf = Filtro espejo de cuadratura (ortonormal).
x = Señal reconstruida a partir de wc. Salidas:
Cálculo de la transformada wavelet inversa usando la funci. I I W r , Sintaxis:
x = iwt-ai(wc,L,D,F,EF)
37

Capitulo 111. Procesamiento de seriales
Entradas: wc = coeficientes de la transformada wavelet. Su longitud debe ser potencia de 2. Length(~)=2~: L = Nivel más alta; L-J. D = Grado del polinomio para la interpolación promedio. F = Filtro creado por la función rnakeaifiiter. EF = Filtro de borde creado por la función rnakeaibdryfilter.
x = Señal reconstruida a partir de wc. Salidas:
Construcción de los filtros digitales utilizados por las transformadas.
+ Cálculo del filtro QMF mediante la función MakeOnFilter. Sintaxis:
qmf = MakeOnFi/ter( Tipo, Par)
Tipo = Cadena con el tipo de wavelet: 'Haar', 'Beylkin', 'Coiflet', 'Daubechies'. 'Symrnlet', 'Vaidyanathan'.
Entradas:
Par = Número entero, por ejemplo, sí el Tipo = 'Coiflet', Par=3, especifica el wavelet Coiflet.
qrnf = Filtro espejo de cuadratura. Salidas:
+ Cálculo de filtro mediante la función makeaifilter. Sintaxis:
Entradas: Filt = makeaifi/fer(D)
D = Grado del polinomio para la interpolación promedio. Debe ser un entero par.
Filt = Filtro de interpolación promedio. Salidas:
+ Cálculo de filtro mediante la función rnakeaibdryfilter.
EdgeFilt = makeaibdryfi/ter(D)
D = Grado del polinomio para la interpolación promedio. Debe ser un entero par.
uso:
Entradas:
38

CapltUlO 111. Procesamiento de seilales
Salidas: EdgeFilt = Filtro de borde.
Estos datos fueron obtenidos del manual de referencia de Waveiab [47].
39

Capitulo IV. Metodologia para la sintesis de voz
CAPITULO IV METODOLOGíA PARA LA
SíNTESIS DE VOZ
4.1. INTRODUCCI~N
Este capítulo describe la metodología propuesta para realizar síntesis de voz, así como también los resultados obtenidos. La metodología propuesta presenta varias etapas; básicamente se realiza la detección del período pitch y la amplitud envolvente; dependiendo del tipo de sonido se hace un seccionamiento del fonema; se hace la selección de micro funciones, el análisis de una micro función mediante wavelets; esta información sirve para reconstruir la señal, es decir para generar el fonerna sintetizado por medio de concatenación de micro funciones reconstruidas. Para algunas de las etapas se probaron dos alternativas diferentes para seleccionar la mejor, tal es el caso del análisis de micro funciones y los métodos de concatenación de micro funciones.
40

Capitulo ;V. Metodologia para la sintesis de voz
4.2. PRINCIPIO PARA LA SiNTESIS DE VOZ
En forma general, la síntesis de voz se realiza a partir de un análisis de voz grabada para extraer coeficientes wavelets, así como también las características propias de la voz, como son la razón de repetición (pitch) y la amplitud de la envolvente’; esta información, que es menor que la información de sella1 original, servirá para realizar una reconstrucción de la señal y así llevar a cabo la síntesis, véase la Figura 4.1.
ENVOLVENTE
Figura 4.1. Diagrama a bloques.de los pasos para realizar la síntesis de voz.
Como se observa en la Figura 4.2, una señal de voz presenta cierta periodicidad, es decir, está formada por ciclos que van cambiando su forma de onda en el tiempo; dicha forma de onda cambia en mayor o menor grado dependiendo del tipo de sonido. Los sonidos vocálicos presentan en menor grado este cambio en su forma de onda (ver la Figura 4.2), esto significa que los ciclos de un sonido vocálico son muy parecidos entre sí. Con base en este hecho, la síntesis de voz en este trabajo se basa en tomar uno de estos ciclos (que llamaremos micro función), analizarlo mediante wavelets, para posteriormente repetirlo con ciertas reglas y formar un fonema sintetizado. El tomar un ciclo o micro función de la señal de voz original para, a partir de su información, generar un segmento o todo el fonema es el enfoque que diferencia este trabajo de otras formas para llevar a cabo la generación artificial de voz. En la actualidad la forma mas común de realizar la síntesis es grabando unidades básicas como fonemas o sílabas de sonidos y concatenarlas mediante alguna técnica para disminuir la transición de los segmentos, además de agregar características que permitan variar algunos de sus parámetros de entonación y
Amplitud de la envolvenle. En este trabajo nos referimos a la amplitud de la envolvente como el valor de 1
amplitud máximo de cada uno de los ciclos que componen a la señal de voz.
41
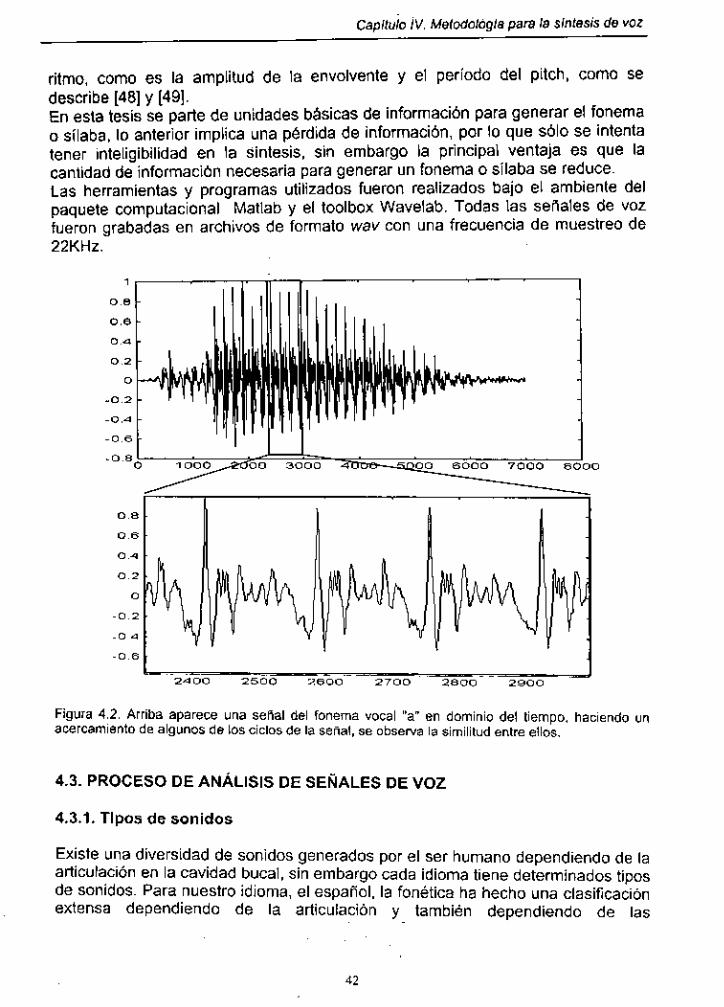
Capitulo IV. Metodologla para is sintesis de voz
ritmo, como es la amplitud de la envolvente y el período del pitch, como se describe [48] y [49]. En esta tesis se parte de unidades básicas de informacibn para generar el fonema o sílaba, lo anterior implica una pérdida de informacibn, por lo que sólo se intenta tener inteligibilidad en la síntesis, sin embargo la principal ventaja es que la cantidad de información necesaria para generar un fonema o sílaba se reduce. Las herramientas y programas utilizados fueron realizados bajo el ambiente del paquete computacional Matlab y el toolbox Wavelab. Todas las señales de voz fueron grabadas en archivos de formato wav con una frecuencia de muestre0 de 22KHz.
O
-0.2
-0.4
-0.6
I 2400 2500 2600 2700 2800 2900
Figura 4.2. Arriba aparece una señal del fonema vocal "a" en dominio del tiempo, haciendo un acercamiento de algunos de los ciclos de la señal, se observa la similitud entre ellos.
4.3. PROCESO DE ANÁLISIS DE SENALES DE VOZ
4.3.1. Tipos de sonidos
Existe una diversidad de sonidos generados por el ser humano dependiendo de la articulación en la cavidad bucal, sin embargo cada idioma tiene determinados tipos de sonidos. Para nuestro idioma, el español, la fonética ha hecho una clasificación extensa dependiendo de la articulación y también dependiendo de las
42
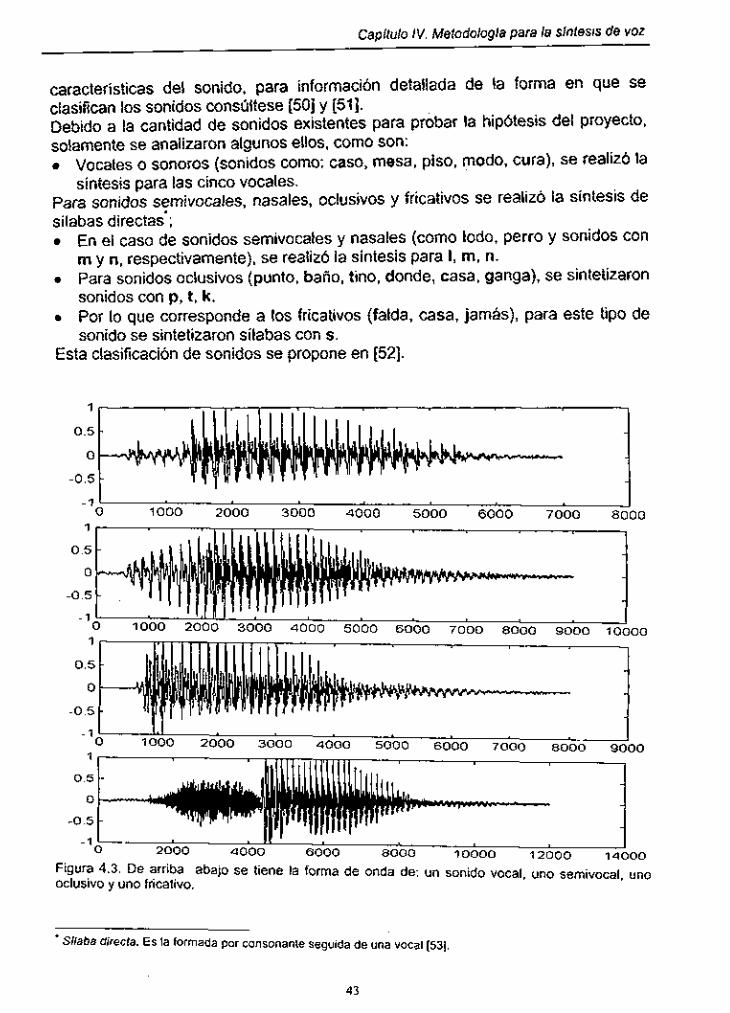
Capitulo IV. Metodologla para la síntesis de VOZ
características del sonido, para información detallada de la forma en que se clasifican los sonidos consúltese [50] y (511. Debido a la cantidad de sonidos existentes para probar la hipótesis del proyecto, solamente se analizaron algunos ellos, como son:
Vocales o sonoros (sonidos como: caso, mesa, piso, modo, cura), se realizó la síntesis para las cinco vocales.
Para sonidos semivocales, nasales, oclusivos y fricativos se realizó la síntesis de sílabas directas';
En el caso de sonidos semivocales y nasales (como lodo, perro y sonidos con m y n, respectivamente), se realizó la síntesis para I, m, n. Para sonidos oclusivos (punto, baño, tino, donde, casa, ganga), se sintetizaron sonidos con p, t, k. Por lo que corresponde a los fricativos (falda, casa, jamás), para este tipo de sonido se sintetizaron sílabas con c.
Esta clasificación de sonidos se propone en [52].
1
0.5
O
-0.5
-1 ' I O 1000 2000 3000 4000 5000 6000 7000 8000
1
0 5
O
-0 5
- 1 O 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000 1
0.5
O
-0.5 I. I
1000 2000 3000 4000 5000 6000 7000 8000 9000 J O 1
o 5
O
-0 5
-1
Figura 4.3. De arriba abajo se tiene la forma de onda de: un sonido vocal, uno semivocal. uno oclusivo y uno fricativo.
* Sllaba direcfa. Es la formada por consonante seguida de una vocal [53]
43
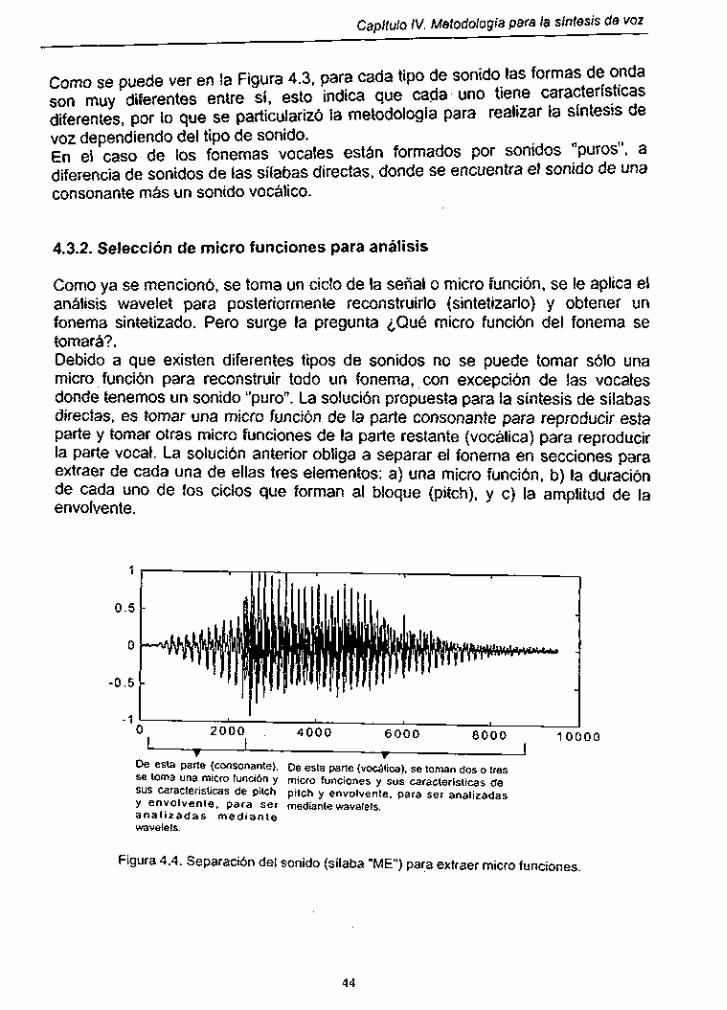
Capitulo lV. Metodología para la síntesis de VOL
Como se puede ver en la Figura 4.3, para cada tipo de sonido las formas de onda son muy diferentes entre sí, esto indica que cada uno tiene características diferentes, por lo que se particularizó la metodología para realizar la síntesis de voz dependiendo del tipo de sonido. En el caso de los fonemas vocales están formados por sonidos "pUrOS", a diferencia de sonidos de las sílabas directas, donde se encuentra el sonido de una consonante más un sonido vocálico.
4.3.2. Selección de micro funciones para análisis
Como ya se mencionó, se toma un ciclo de la señal o micro función, se le aplica el análisis wavelet para posteriormente reconstruirlo (sintetizarlo) y obtener un fonema sintetizado. Pero surge la pregunta ¿Qué micro función del fonema se tomará?. Debido a que existen diferentes tipos de sonidos no se puede tomar sólo una micro función para reconstruir todo un fonema, con excepción de las vocales donde tenemos un sonido "puro". La solución propuesta para la síntesis de silabas directas, es tomar una micro función de la parte consonante para reproducir esta parte y tomar otras micro funciones de la parte restante (vocálica) para reproducir la parte vocal. La solución anterior obliga a separar el fonema en secciones para extraer de cada una de ellas tres elementos: a) una micro función, b) la duración de cada uno de los ciclos que forman al bloque (pitch), y c) la amplitud de la envolvente.
I
6000 8000 10000 2000 . 4 0 0 0 I
O I I
7 I I De esta parte (consonante), De esta parte (vocáiica), se toman dos o tres se toma una micro funci6n y micro funciones y sus características de Sus caracteristicas de pitch pitch y envolvente, para ser analizadas y envolvente. para ser mediantewavelets. a n a l i z a d a s m e d i a n t e wavelets.
Figura 4.4. Separaci6n del sonido (silaba "ME) para extraer micro funciones
44
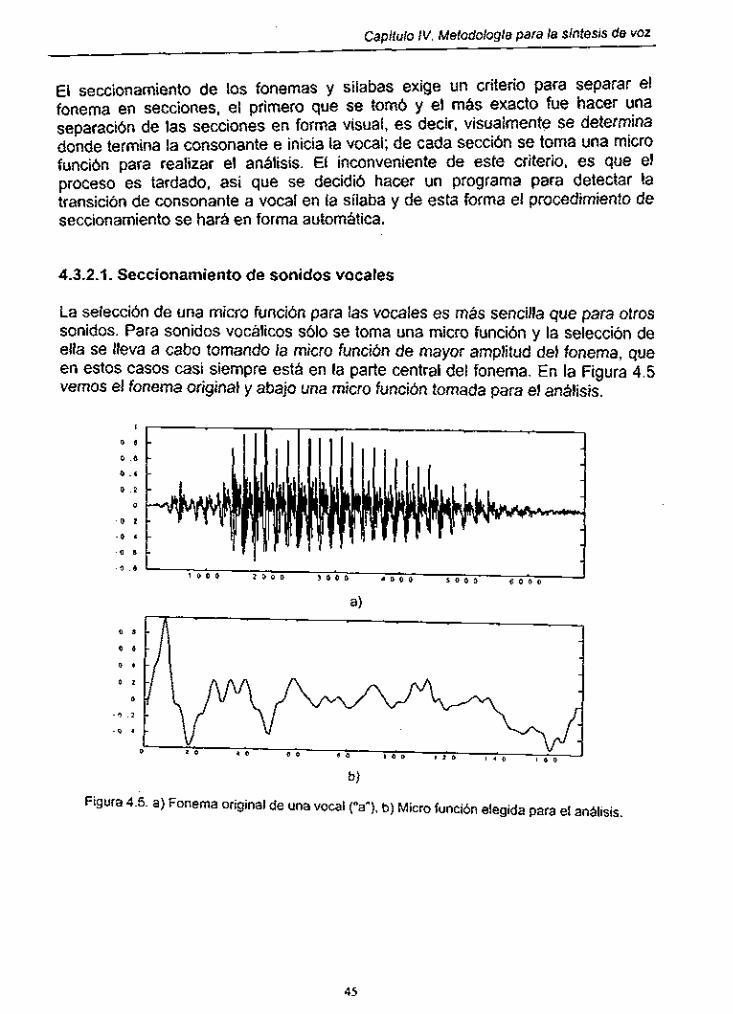
Capitulo IV. Metodologla para la síntesis de voz
El seccionamiento de los fonemas y sílabas exige un criterio para separar el fonema en secciones, el primero que se tom6 y el más exacto fue hacer una separaci6n de las secciones en forma visual, es decir, visualmente se determina donde termina la consonante e inicia la vocal; de cada sección se toma una micro función para realizar el análisis. El inconveniente de este criterio, es que el proceso es tardado, así que se decidi6 hacer un programa para detectar la transición de consonante a vocal en la sílaba y de esta forma el procedimiento de seccionamiento se hará en forma automática.
4.3.2.1. Seccionamiento de sonidos vocales
La selección de una micro función para las vocales es más sencilla que para otros sonidos. Para sonidos vocálicos sólo se toma una micro función y la selección de ella se lleva a cabo tomando la micro función de mayor amplitud del fonema, que en estos casos casi siempre está en la parte central del fonema. En la Figura 4.5 vemos el fonema original y abajo una micro función tomada para el análisis.
I
b)
Figura 4.5. a) Fonema original de una vocal ("a"), b) Micro función elegida para el análisis.
45
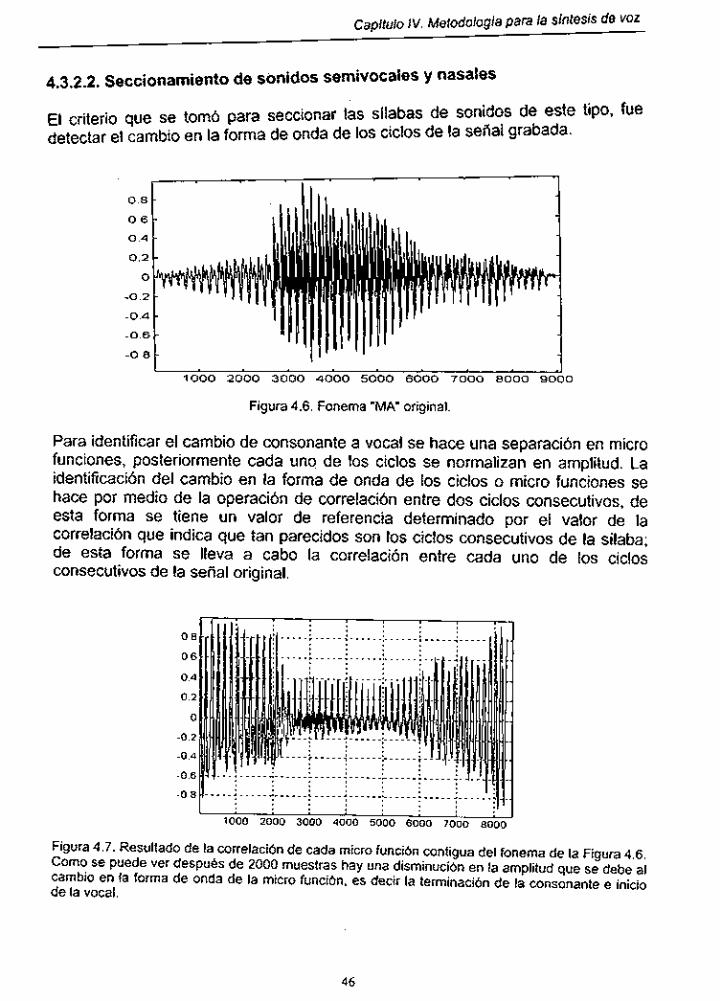
Capftulo IV. Melodologfa para la slntesis de voz
4.3.2.2. Seccionamiento de sonidos semivocales y nasales
El criterio que se tomó para seccionar las sílabas de sonidos de este tipo, fue detectar el cambio en la forma de onda de los ciclos de la señal grabada.
I
I I 1000 2000 3000 4000 5000 6000 7000 8000 9000
Figura 4.6. Fonema “MA“ original
Para identificar el cambio de consonante a vocal se hace una separación en micro funciones, posteriormente cada uno de los ciclos se normalizan en amplitud. La identificación del cambio en la forma de onda de los ciclos o micro funciones se hace por medio de la operación de correlación entre dos ciclos consecutivos, de esta forma se tiene un valor de referencia determinado por el valor de la correlación que indica que tan parecidos son los ciclos consecutivos de la sílaba; de esta forma se lleva a cabo la correlación entre cada uno de los ciclos consecutivos de la señal original.
I I 1000 2000 3000 4000 5000 6000 7000 8000
Figura 4.7. Resultado de la correlación de cada micro función contigua del fonema de la Figura 4.6. Como se puede ver después de 2000 muestras hay una disminución en la amplitud que se debe al cambio en la forma de onda de la micro función, es decir la terminación de la consonante e inicio de la vocal.
46
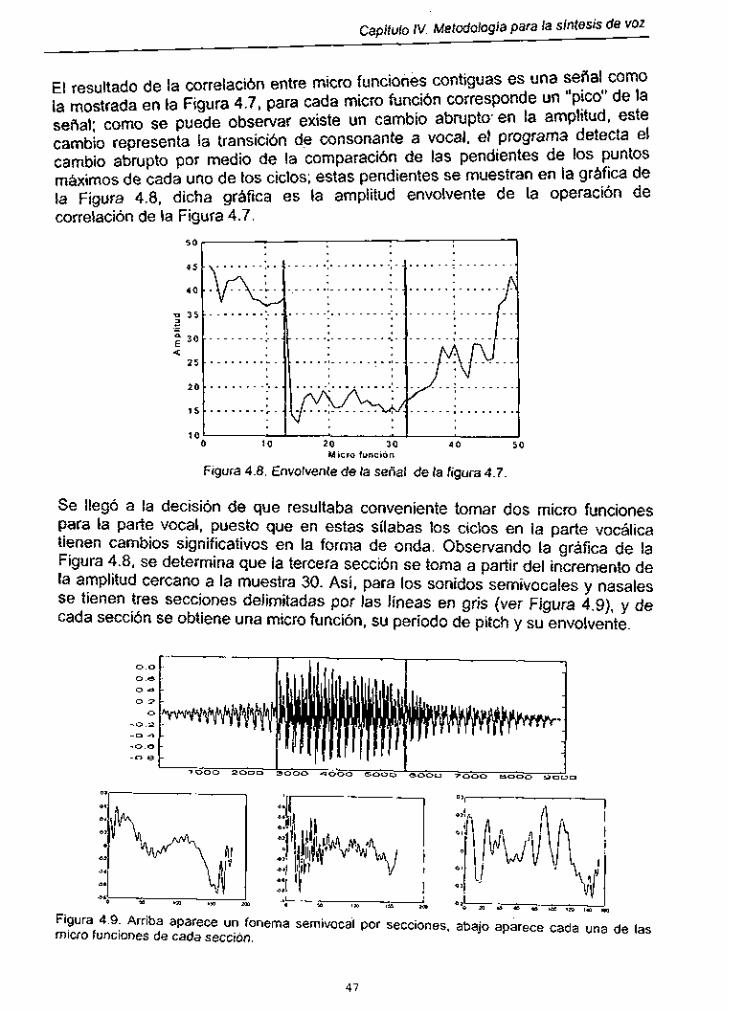
Capitulo IV. Metodologla para la sintesis de voz
El resultado de la correlación entre micro funciones contiguas es una Señal como la mostrada en la Figura 4.7, para cada micro función corresponde un "pico" de la setial; como se puede observar existe un cambio abrupto.en la amplitud, este cambio representa la transición de consonante a vocal, el programa detecta el cambio abrupto por medio de la comparación de las pendientes de los puntos máximos de cada uno de los ciclos; estas pendientes se muestran en la gráfica de la Figura 4.8, dicha gráfica es la amplitud envolvente de la operación de correlación de la Figura 4.7.
5 0
.................................
1 5 .........
1 0 O 10 2 0 30 4 0 5 0
Micro tuncion
Figura 4.8. Envolvente de la señal de la figura 4.7.
Se llegó a la decisión de que resultaba conveniente tomar dos micro funciones para la parte vocal, puesto que en estas sílabas los ciclos en la parte vocálica tienen cambios significativos en la forma de onda. Observando la gráfica de la Figura 4.8, se determina que la tercera sección se toma a partir del incremento de la amplitud cercano a la muestra 30. Así, para los sonidos semivocales y nasales se tienen tres secciones delimitadas por las líneas en gris (ver Figura 4.9), y de cada sección se obtiene una micro función, su período de pitch y su envolvente.
Figura 4.9. Arriba aparece un fonema semivocal por secciones, abajo aparece cada una de las micro funciones de cada sección.
47
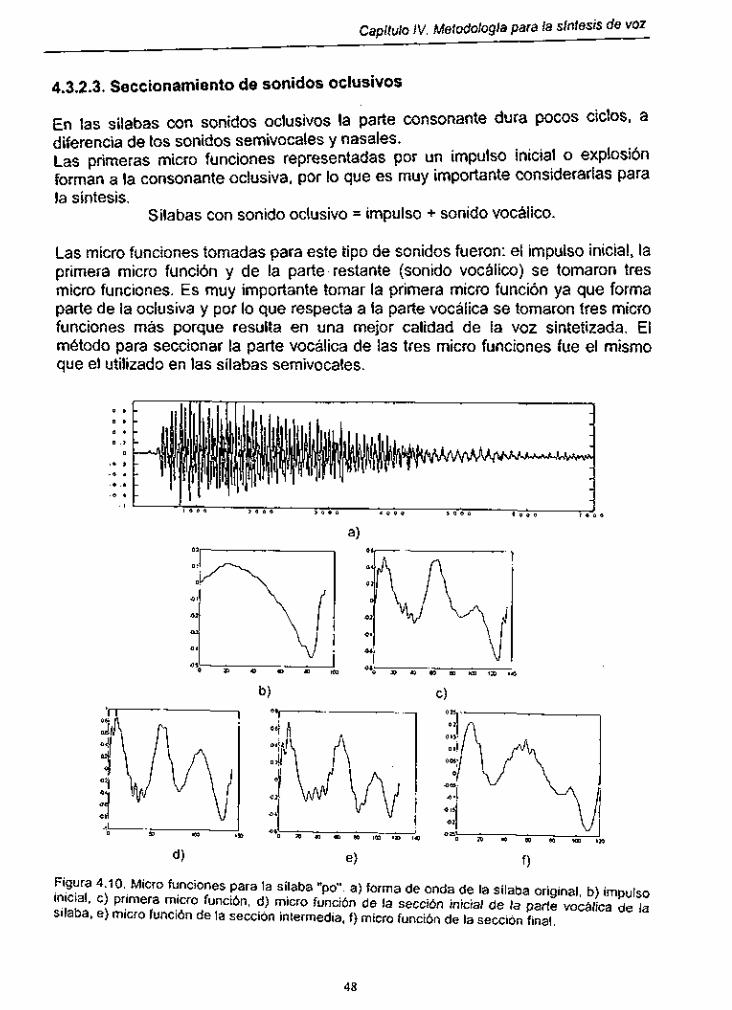
Capitu/o fv. Metodofogla para fa sintesis de VOZ
4.3.2.3. Seccionamiento de sonidos ~ClusivOS
En las sílabas con sonidos oclusivos la parte consonante dura pocos ciclos, a diferencia de los sonidos semivocales y nasales. Las primeras micro funciones representadas por un impulso inicial o explosión forman a la consonante ociusiva, por lo que es muy importante considerarlas para la sintesis.
Sílabas con sonido oclusivo = impulso + sonido vocálico.
Las micro funciones tomadas para este tipo de sonidos fueron: el impulso inicial, la primera micro función y de la parte restante (sonido vocálico) se tomaron tres micro funciones. Es muy importante tomar la primera micro función ya que forma parte de la oclusiva y por lo que respecta a la parte vocálica se tomaron tres micro funciones más porque resulta en una mejor calidad de la voz sintetizada. El metodo para seccionar la parte vocálica de las tres micro funciones fue el mismo que el utilizado en las sílabas semivocales.
o ., t
Figura 4.10. Micro funciones para la silaba "PO". a) forma de onda de la silaba original, b) impulso inicial, c) primera micro función, d) micro función de la sección inicial de la parte vocálica de la silaba, e) micro función de la sección intermedia, f) micro función de la sección final.
48
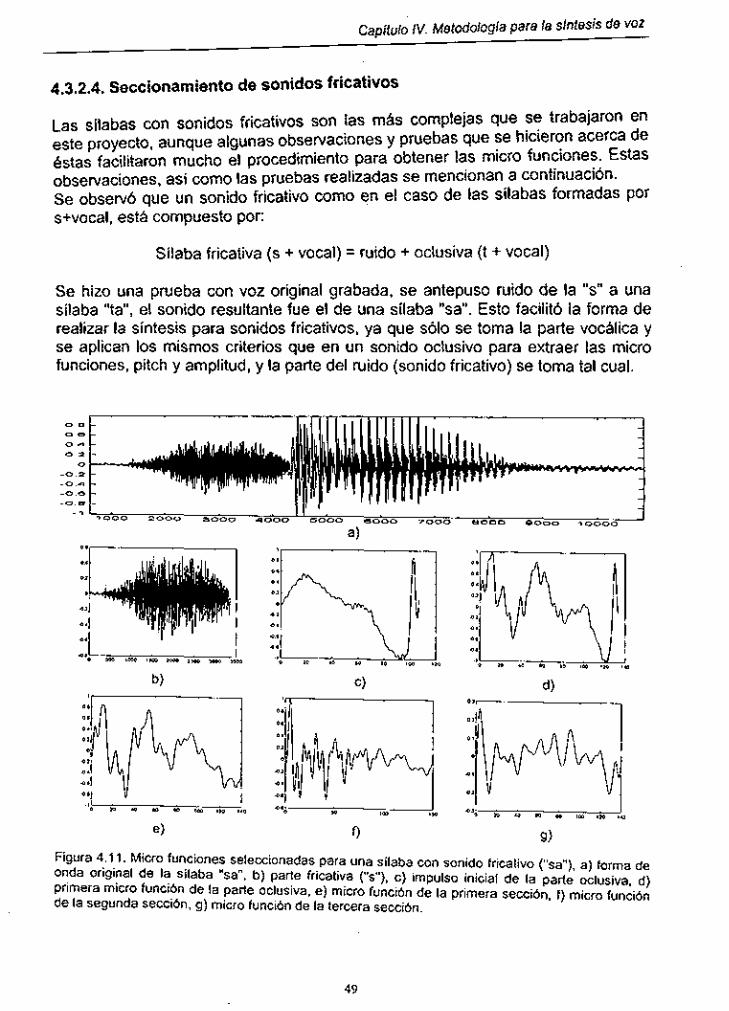
Capitulo IV. Metodologla para la slntesis de voz
4.3.2.4. Seccionamiento de sonidos fricativos
Las sílabas con sonidos fricativos son las más complejas que se trabajaron en este proyecto, aunque algunas observaciones y pruebas que se hicieron acerca de éstas facilitaron mucho el procedimiento para obtener las micro funciones. Estas observaciones, as¡ como las pruebas realizadas se mencionan a continuación. Se observó que un sonido fricativo como en el caso de las sílabas formadas por s+vocal, está compuesto por:
Sílaba fricativa (s + vocal) = ruido + oclusiva (t + vocal)
Se hizo una prueba con voz original grabada, se antepuso ruido de la "s" a una sílaba "ta". el sonido resultante fue el de una sílaba "sa". Esto facilitó la forma de realizar la síntesis para sonidos fricativos, ya que sólo se toma la parte vocálica y se aplican los mismos criterios que en un sonido oclusivo para extraer las micro funciones, pitch y amplitud, y la parte del ruido (sonido fricativo) se toma tal cual.
0.- - 0.0 - 0.4 -
- - -
O -0.2 . . -0.-
-0.0 -0.- -
._1
- - - -
7 0 0 0 2000 a000 4000
D I
O.
0 .
02
0 .
*I
a. a' 41
4,
4.
9..
91
o,
o 7
o / 0 .
0 1
0 % o1
4.
01
91
9 9) e)
Figura 4.1 1. Micro funciones seleccionadas para una sílaba con sonido fricativo ("sa"), a) forma de onda original de la silaba "sa". b) parte fricativa ("s"), c) impulso inicial de la parte octusiva, d) primera micro función de la parte oclusiva, e) micro función de la primera sección, f) micro función de la segunda sección, g) micro función de la tercera sección.
49
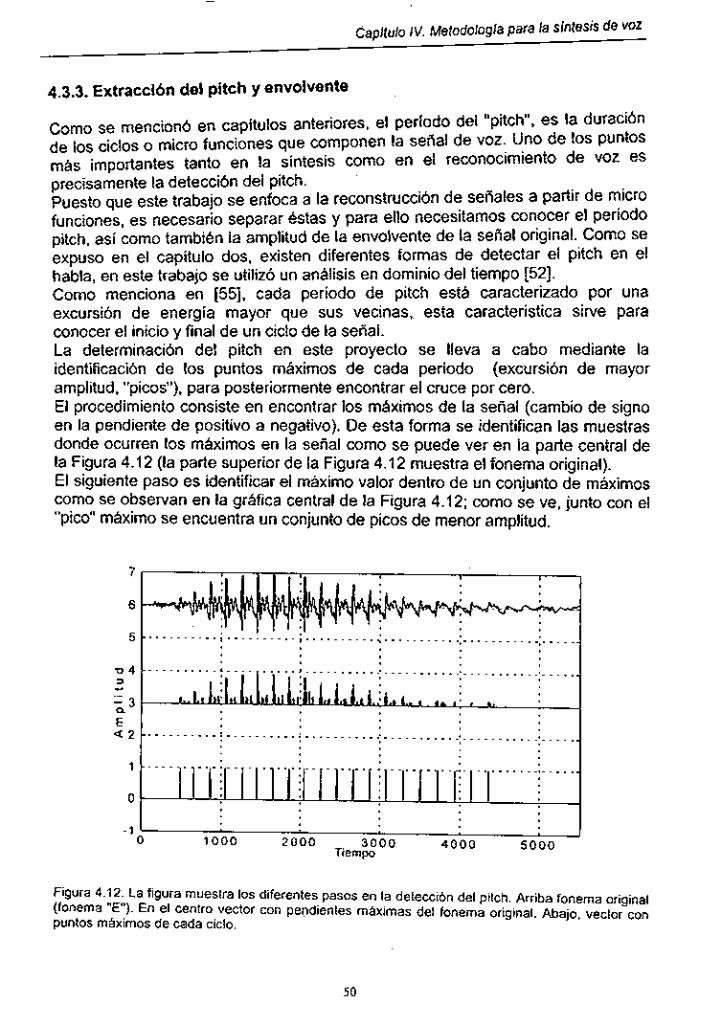
Capftufo IV. Metodofogfa para fa sfntesis de voz
Ivi-
4.3.3. Extracción del pitch y envolvente
Como se mencionó en capitulas anteriores, el periodo del "pitch", es la duracibn de los ciclos 0 micro funciones que componen la señal de VOZ. Uno de 10s Puntos más importantes tanto en la síntesis como en el reconocimiento de VOZ es precisamente la detecci6n del pitch. Puesto que este trabajo se enfoca a la reconstrucción de señales a partir de micro funciones, es necesario separar éstas y para ello necesitamos conocer el período pitch, así como también la amplitud de la envolvente de la señal original. Como se expuso en el capítulo dos, existen diferentes formas de detectar el pitch en el habla, en este trabajo se utilizó un análisis en dominio del tiempo [52]. Como menciona en [55], cada período de pitch está caracterizado por una excursión de energía mayor que sus vecinas,. esta característica sirve para conocer el inicio y final de un ciclo de la señal. La determinación del pitch en este proyecto se lleva a cabo mediante la identificación de los puntos máximos de cada periodo (excursión de mayor amplitud, "picos"), para posteriormente encontrar el cruce por cero. El procedimiento consiste en encontrar los máximos de la señal (cambio de signo en la pendiente de positivo a negativo). De esta forma se identifican las muestras donde ocurren los máximos en la señal como se puede ver en la parte central de la Figura 4.12 (la parte superior de la Figura 4.12 muestra el fonema original). El siguiente pas0 es identificar el máximo valor dentro de un conjunto de máximos cOn-10 se observan en la gráfica central de la Figura 4.12; como se ve, junto con el "Pico" máximo se encuentra un conjunto de picos de menor amplitud.
7
6
5
734
- 3 n E
3 .- ._
a2
1
O
-1
Figura 4.12. La figura muestra los diferentes pasos en la detecci6n del pitch. Arriba fonema original (fonema " E ) . En el centro vector con pendientes máximas del fonema original. Abajo, vector con puntos máximos de cada ciclo.
50
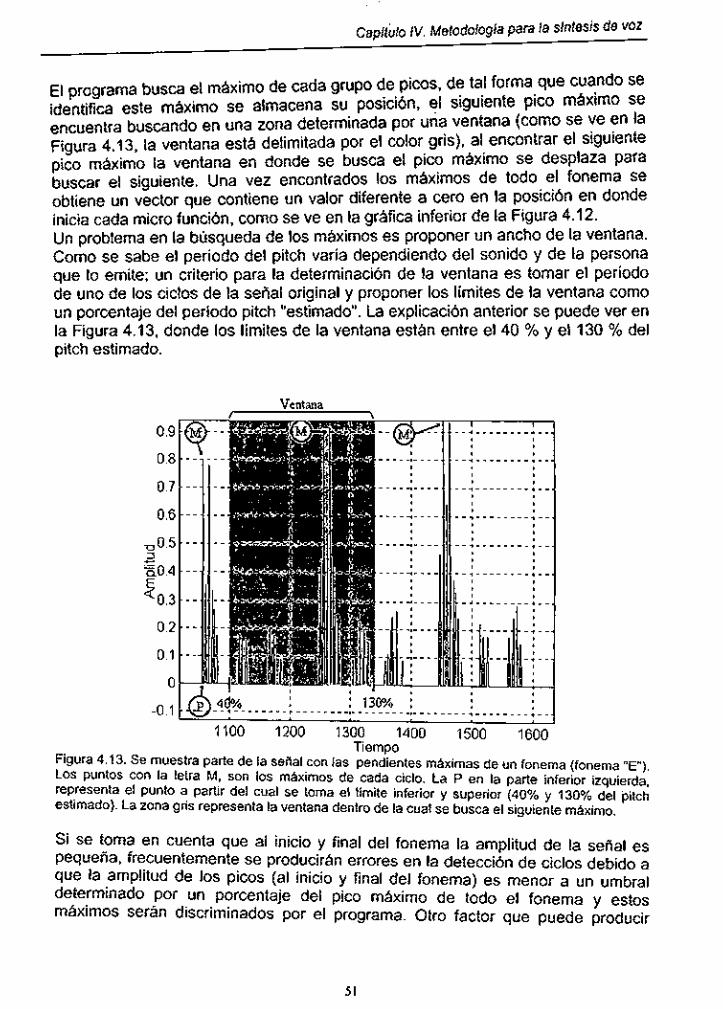
Capitihy IV. Metodofogla para la slntesis de VOZ
~1 programa busca el máximo de cada grupo de picos, de tal forma We cuando se identifica este máximo se almacena su posicibn, el siguiente pico máximo se encuentra buscando en una zona determinada por una ventana (como se ve en la Figura 4.13, la ventana está delimitada por el color gris), al encontrar el Siguiente pico máximo la ventana en donde se busca el pico máximo se desplaza para buscar el siguiente. Una vez encontrados los máximos de todo el fonema se obtiene un vector que contiene un valor diferente a cero en la posici6n en donde inicia cada micro funci6n, como se ve en la gráfica inferior de la Figura 4.12. Un problema en la búsqueda de los máximos es proponer un ancho de la ventana. Como se sabe el periodo del pitch varia dependiendo del sonido y de la persona que lo emite; un criterio para la determinación de la ventana es tomar el periodo de uno de los ciclos de la señal original y proponer los limites de la ventana como un porcentaje del periodo pitch "estimado". La explicación anterior se puede ver en la Figura 4.13, donde los límites de la ventana están entre el 40 Yo y el 130 % del pitch estimado.
Ventana
0.9
0.8
O .7
0.6
,0.5
a0.4 3 w .-
20.3
0.2
0.1
O
IIUU I LUU I3UU 14UU 1500 1600 Tiempo
Figura 4.13. Se muestra parte de la seilal con las pendientes máximas de un fonema (fonema "E) . Los puntos con la letra M, son los máximos de cada ciclo. La P en la parte inferior izquierda, representa el punto a partir del cual se toma el limite inferior y superior (40% y 130% del pitch estimado). La zona gris representa la ventana dentro de la cual se hi i sm el niniiienb rn6uirnn
Si se toma en cuenta que al inicio y final del fonema la amplitud de la señal es pequeña, frecuentemente se producirán errores en la detección de ciclos debido a que la amplitud de los picos (al inicio y final del fonema) es menor a un umbral determinado por un porcentaje del pico máximo de todo el fonema y estos máximos serán discriminados Dor el oroarama. Otro fñctnr nile ni iodo nrndi ipir
51
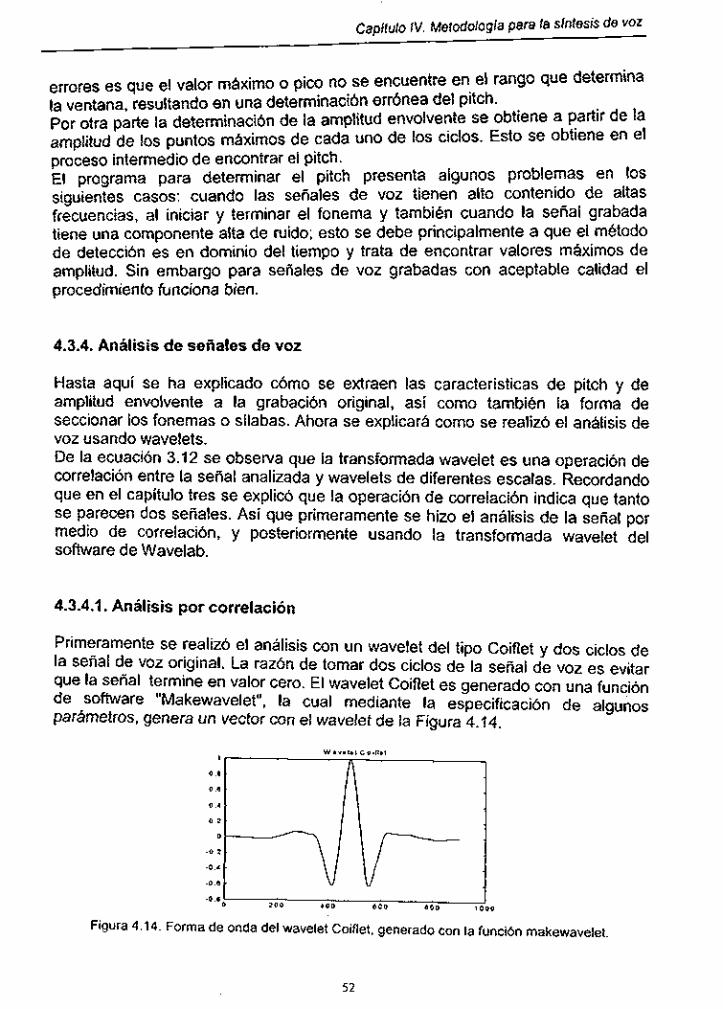
Capitulo Iv. Metodologla para la shtesis de VOZ
errores es que el valor máximo o pico no se encuentre en el rango que determina la ventana, resultando en una determinación err6nea del pitch. Por otra parte la determinación de la amplitud envolvente se obtiene a partir de la amplitud de los puntos máximos de cada uno de los ciclos. Esto se obtiene en el proceso intermedio de encontrar el pitch. El programa para determinar el pitch presenta algunos problemas en los siguientes casos: cuando las señales de voz tienen alto contenido de altas frecuencias, al iniciar y terminar el fonema y también cuando la señal grabada tiene una componente alta de ruido; esto se debe principalmente a que el método de detección es en dominio del tiempo y trata de encontrar valores máximos de amplitud. Sin embargo para señales de voz grabadas con aceptable calidad el procedimiento funciona bien.
4.3.4. Análisis de señales de voz
Hasta aquí se ha explicado cómo se extraen las características de pitch y de amplitud envolvente a la grabación original, así como también la forma de seccionar los fonemas o sílabas. Ahora se explicará como se realizó el análisis de voz usando wavelets. De la ecuación 3.12 se observa que la transformada wavelet es una operación de correlación entre la señal analizada y wavelets de diferentes escalas. Recordando que en el capitulo tres se explicó que la operación de correlación indica que tanto se parecen dos señales. Así que primeramente se hizo el análisis de la señal por medio de correlación, y posteriormente usando la transformada wavelet del software de Wavelab.
4.3.4.1. Análisis por correlación
Primeramente se realizó el análisis con un wavelet del tipo Coiflet y dos ciclos de la señal de voz original. La razón de tomar dos ciclos de la señal de voz es evitar que la señal termine en valor cero. El wavelet Coiflet es generado con una función de software "Makewavelet", la cual mediante la especificación de algunos parametros, genera un vector con el wavelet de la Figura 4.14.
W.rLlalCOi, l . ,
o .* I \
I .PO 6 0 0 8 0 0 1 0 0 0 2 0 0
Figura 4.14. Forma de onda del wavelet Coiflet, generado con la función makewavelet
52
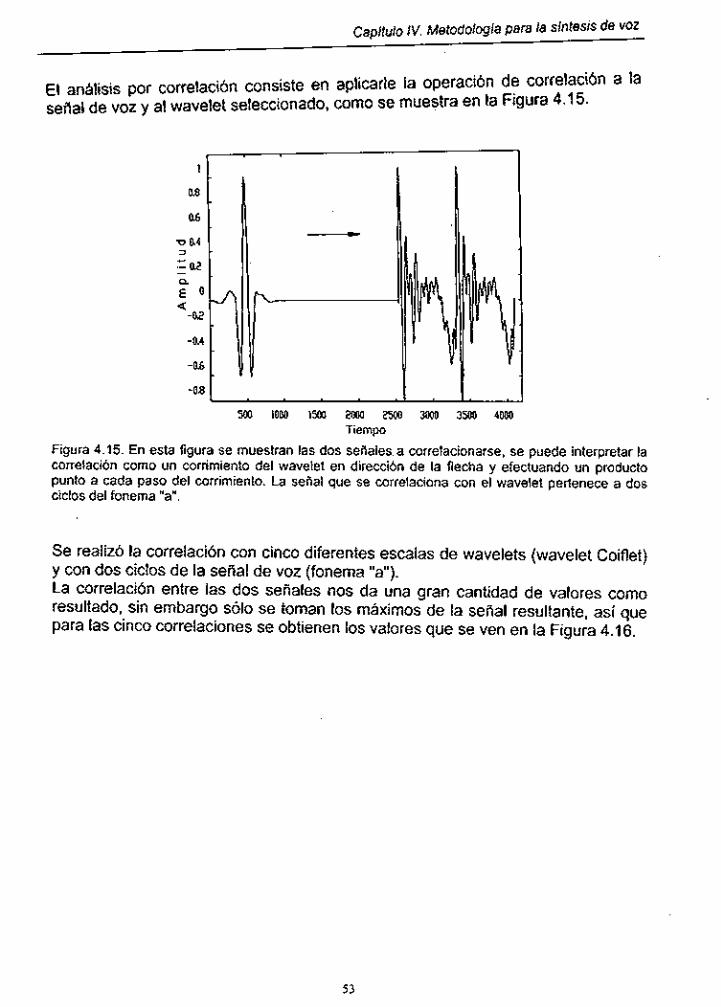
Capitulo IV. Metodologla para la slntesis de VOZ
El análisis por correlación consiste en aplicarle la operación de correlación a la señal de voz y al wavelet seleccionado, como se muestra en la Figura 4.1 5.
I 1
E O Q
-02
-0.4
-06
-0.81 , , , , , , , , , , ]
5w 1000 15w 2000 2500 3000 3500 4000 Tiempo
Figura 4.15. En esta figura se muestran las dos señales a correlacionarse. se puede interpretar la correlaci6n como un corrimiento del wavelet en direccibn de la flecha y efectuando un producto punto a cada paso del corrimiento. La señal que se correlaciona con el wavelet pertenece a dos ciclos del fonema "a".
Se realizó la correlación con cinco diferentes escalas de wavelets (wavelet Coiflet) y con dos ciclos de la señal de voz (fonema "a"). La correlación entre las dos señales nos da una gran cantidad de valores como resultado, sin embargo sólo se toman los máximos de la señal resultante, así que para las cinco correlaciones se obtienen los valores que se ven en la Figura 4.16.
53
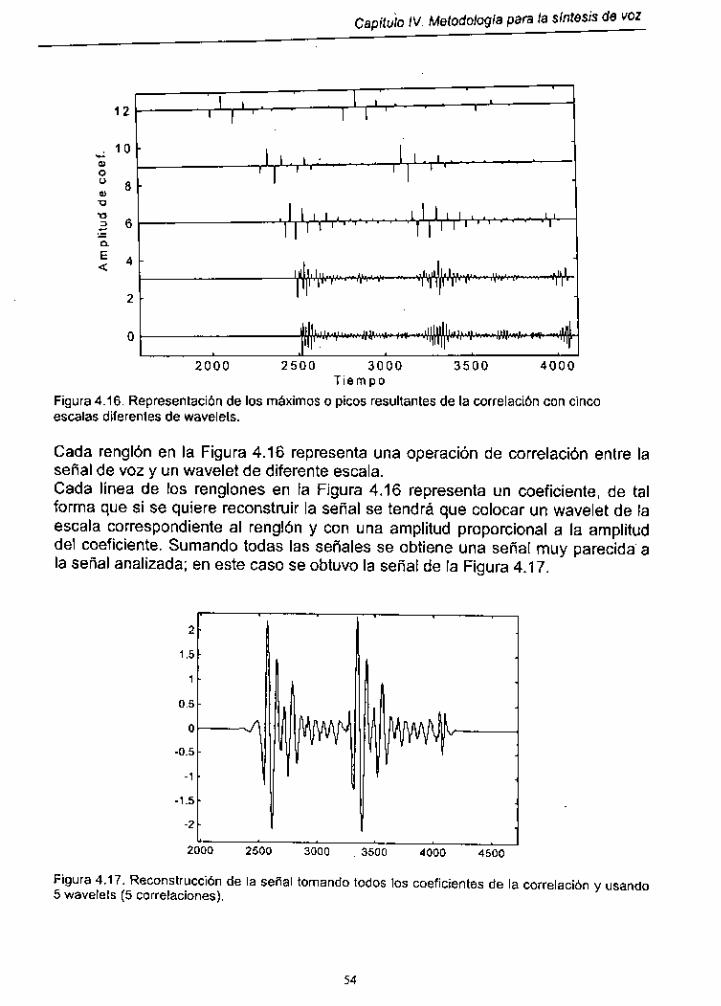
Capituio fV. Metodofogla para fa slntesis de voz
1 2 u 1 0 -
O I
o 0 -
= 6
i a 1 1 . 1 : 1 . 1 . . . , . I 1 1
@
U I I I 1 . ., ., ,. , I I 1 I I I , .,. A-
e ._ I " ' " E 4 -
Q
4
2 -
O
2 0 0 0 2500 3000 3500 4000 Tiempo
Figura 4.16. Representacibn de los mbximos o picos resultantes de la correlaci6n con cinco escalas diferentes de wavelets.
Cada renglón en la Figura 4.16 representa una operación de correlación entre la señal de voz y un wavelet de diferente escala. Cada línea de los renglones en la Figura 4.16 representa un coeficiente, de tal forma que si se quiere reconstruir la señal se tendrá que colocar un wavelet de la escala correspondiente al renglón y con una amplitud proporcional a la amplitud del coeficiente. Sumando todas las señales se obtiene una señal muy parecida a la señal analizada; en este caso se obtuvo la señal de la Figura 4.17.
2
1.5
1
0.5
O
-0.5
-1
-1.5
-2 I I 2000 2500 3000 . 3500 4000 4500
Figura 4.17. Reconstrucción de la señal tomando todos los coeficientes de la correlación y usando 5 wavelets (5 correlaciones).
54
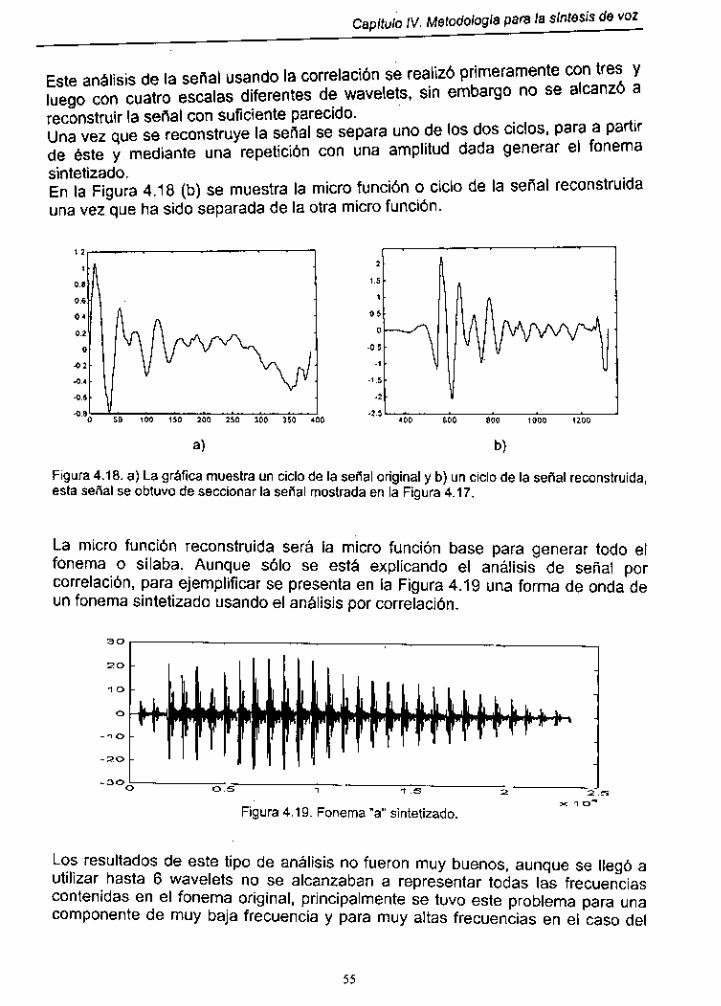
Capltulo lv. Metodologla para la slntesis de VOZ
Este análisis de la señal usando la correlación se realizó primeramente con tres y luego con cuatro escalas diferentes de wavelets, sin embargo no se alcanzó a reconstruir la señal con suficiente parecido. Una vez que se reconstruye la señal se separa uno de los dos ciclos, para a partir de éste y mediante una repetición con una amplitud dada generar el fonema sintetizado. En la Figura 4.18 (b) se muestra la micro función o ciclo de la señal reconstruida una vez que ha sido separada de la otra micro función.
2
1.5
1
0 5
O
-0.5
.I
. l .5
.2
.2.5 O 50 100 150 200 250 300 350 400 400 BOO BOO 1000 1200
a) b)
Figura 4.18. a) La gráfica muestra un ciclo de la señal original y b) un ciclo de la señal reconstruida, esta señal se obtuvo de seccionar la señal mostrada en la Figura 4.17.
La micro función reconstruida será la micro función base para generar todo el fonema o silaba. Aunque sólo se está explicando el análisis de señal por correlación, para ejemplificar se presenta en la Figura 4.19 una forma de onda de un fonema sintetizado usando el análisis por correlación.
, 1 .5 2 2.5 0.5
x 1 o- Figura 4.19. Fonema "a" sintetizado.
Los resultados de este tipo de análisis no fueron muy buenos, aunque se llegó a utilizar hasta 6 wavelets no se alcanzaban a representar todas las frecuencias contenidas en el fonema original, principalmente se tuvo este problema para una componente de muy baja frecuencia y para muy altas frecuencias en el caso del
55

Capitulo IV. Metodologla para la slntesis de VOZ
fonema "a"; pero se alcanza a entender el fonema sintetizado. Otro inconveniente es la cantidad grande de cálculos para una operación de correlación entre dos señales, lo que resulta en un tiempo de cálculo mayor en comparaci6n con el tiempo de cálculo usando la transformada wavelet.
4.3.4.2. Análisis por transformada wavelet
Debido a los inconvenientes del análisis por correlación se decidió utilizar la transformada wavelet. El uso de la transformada wavelet presenta algunas ventajas como:
Se usa una función software para calcular la transformada wavelet. Se dispone de varios wavelets. El algoritmo de cálculo es más rápido en comparación con el análisis por correlación.
El paquete de software utilizado para realizar el análisis wavelet, proporciona funciones para el cálculo de la transformada wavelet y transformada wavelet inversa, usando el algoritmo de codificación de sub-banda visto en el capítulo tres. El software proporciona diferentes tipos de wavelets como el Haar, Daubechies, Coifiet, Symmlet y el wavelet de interpolación promedio. En la Figura 4.20 se presenta la forma de onda de estos wavelets. Para el análisis de la señal mediante transformada wavelet se aplicó la transformada a un ciclo de la señal o micro función base. Aunque se aplica sólo a un ciclo, el vector de la señal a analizar tiene una longitud mayor a una micro función; la parte restante de la micro función está formada por pequeñas oscilaciones que tienen el propósito de no permitir un intervalo con valor de cero en el punto de traslape de micro funciones, esto se explicará con más detalle posteriormente.
56
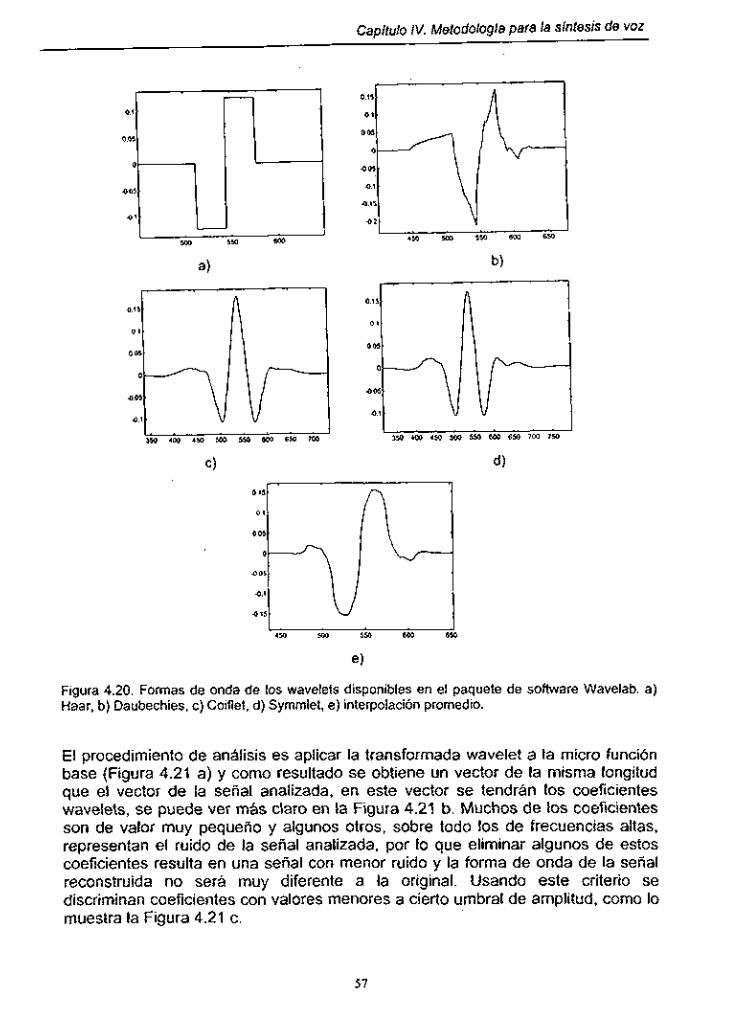
Capitulo IV. Metodologla para la sintesis de voz
O M
4.05
4.1
4.16 nl---v 1 I a 0 sw 5YI ew 650
e)
Figura 4.20. Formas de onda de los wavelets disponibles en el paquete de software Wavelab. a) Haar, b) Daubechies, c) Coiflet, d) Symmlet, e) interpolación promedio.
El procedimiento de análisis es aplicar la transformada wavelet a la micro función base (Figura 4.21 a) y como resultado se obtiene un vector de la misma longitud que el vector de la señal analizada, en este vector se tendrán los coeficientes wavelets, se puede ver más claro en la Figura 4.21 b. Muchos de los coeficientes son de valor muy pequeño y algunos otros, sobre todo los de frecuencias altas, representan el ruido de la señal analizada, por lo que eliminar algunos de estos coeficientes resulta en una señal con menor ruido y la forma de onda de la señal reconstruida no será muy diferente a la original. Usando este criterio se discriminan coeficientes con valores menores a cierto umbral de amplitud, como lo muestra la Figura 4.21 c.
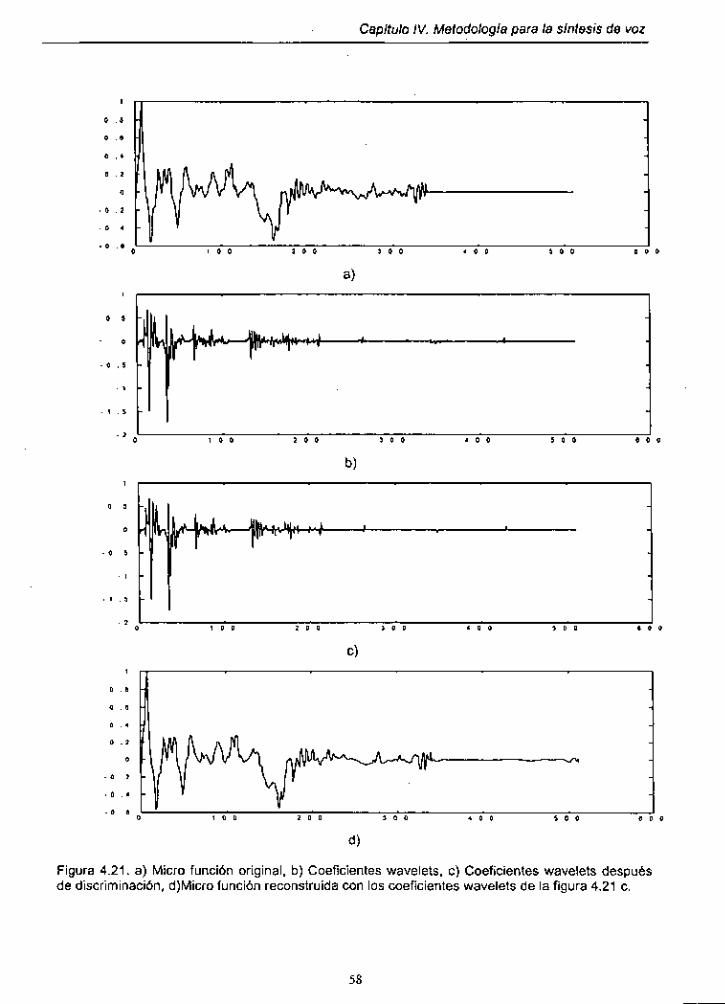
Capitulo lV. Metodologla para la slnfesis de VOL
Figura 4.21. a) Micro función original, b) Coeficientes wavelets, c) Coeficientes wavelets después de discriminación, d)Micro función reconstruida con los coeficientes wavelets de la figura 4.21 c.
58

C/apitu/o IV. Metodologia para la sintesis de voz
b Esta transformada se hizo con el wavelet Symmlet. Hay que aclarar que en la discriminación de coeficientes uno pro one con cuantos coeficientes se reconstruirá la señal, aunque el programa phede seleccionar todos o casi todos los coeficientes. El propósito de poner un limite de Coeficientes es reducir la cantidad de información necesaria para reconstruir la micro función base. La forma de determinar el número de coeficientes par i cada micro función es por prueba y error (se propone un número y se reconstruye la señal para ver qué tanto se parece a la señal original), con lo cual para cada tipo de fonema se obtiene el número adecuado de coeficientes. Por otra parte, la forma de seleccionar un wavelet que proporcione el menor número de coeficientes para la reconstrdcción de la señal es comparando el número de coeficientes necesarios para reconstruir la señal con varios tipos de wavelets. Se hizo el análisis con diferentes tipos de wavelets para diferentes fonemas y el resultado se muestra en la tabla siguiente.
I . .
Tabla 4.1. Tabla comparativa entre el numero de coeficientes necesarios para reconstruir fonemas usando wavelets diferentes.
Las cantidades representan el número de coeficientes necesarios para la reconstrucción de la señal, los fonemas con tres y hasta cinco cifras son aquellos que están seccionados en tres o cinco bloques. Una forma de saber si un wavelet resultará bueno para representar una señal, es decir, si el número de coeficientes será pequeño, es si la forma de onda del wavelet es parecida a la forma de onda de la señal analizada. Es por eso que no se hizo el análisis con el wavelet Haar, el cual tiene una forma de onda cuadrada (las señales de voz no tienen forma cuadrada). De la tabla se observa que para los wavelet Symmlet y de interpolación promedio son para los que se necesitan menor número de coeficientes para representar los fonemas, aunque la diferencia en número entre todos ellos no es muy grande. Debido a que se obtuvieron buenos resultados con el wavelet Symmlet y con el de interpolación promedio y también a que la diferencia en el número de coeficientes necesarios para representar una señal con ellos es pequeña, se decidió usar el wavelet Symmlet.
59

Cepltulo JV. Mefodologle para le slntesis d e VOZ
Una vez obtenido un vector con los coeficientes wavelets se puede aún reducir la cantidad de información que representa a la micro función base. Como se observa en la Figura 4.21 c, una buena parte de los coeficientes wavelets son de valor cero, utilizando un método sencillo de compresión se puede reducir el tamaño de este vector. El método que se utilizó es poner un dato "marca" en donde inicia una cantidad de ceros mayor a dos, de esta forma la "marca" indica que el siguiente dato es el numero de valores cero que siguen en el vector. Como ejemplo para la síntesis del fonema "a", se tiene un vector de 512 datos correspondiente a la micro lfunción base, al calcular la transformada wavelet se obtiene un vector de la ,misma longitud del cual sólo tomamos 60 valores diferentes de cero (60 coeficientes), el vector resultante es de aproximadamente 160 datos. Como se ve el vector se comprimió de 512 a 160 datos por el método de compresión descrito arriba y debido también a que muchos de los coeficientes de la transformada wavelet son de valor cero 0 cercanos a cero.
4.4. AJUSTE DEL PERIODO "PITCH" PARA LA S~NTESIS (GENERACI~N DE VOZ) I
Ahora se verá el proceso be generar la señal de voz sintética, primero, usando coeficientes wavelets y el propio wavelet se reconstruye la micro función base. A partir de ésta y mediante su repetición con una amplitud y desplazamiento (período) determinado por las características extraidas de la señal de voz original (período del pitch y amplitud de la envolvente) se genera el fonema sintetizado. El período de cada micro función del fonema original presenta variaciones y si se toma en cuenta que la micro función base tiene un período fijo, se puede observar que en el proceso de repetir la micro función base con un desplazamiento igual a cada uno de los períodos del pitch original para concatenarlas y formar el fonema sintético, sucederán dos cosas: a) si la duración de la micro función base es mayor que la duración del período pitch original habrá un traslape de la parte final de la primera micro función con la parte inicial de la siguiente micro función.; b) el otro caso sucede cuando la duración de la micro función base es menor que la duración del período pitch original, en este caso se presenta un efecto como el que se muestra en la Figura 4.22 b, donde por un cierto tiempo la señal sintetizada tendrá un valor de cero. Este efecto puede afectar la calidad de la voz sintetizada, por lo que se propusieron dos soluciones a este problema, que son: una concatenación de las micro funciones por traslape y la otra es una concatenación por interpolación de micro funciones.
60
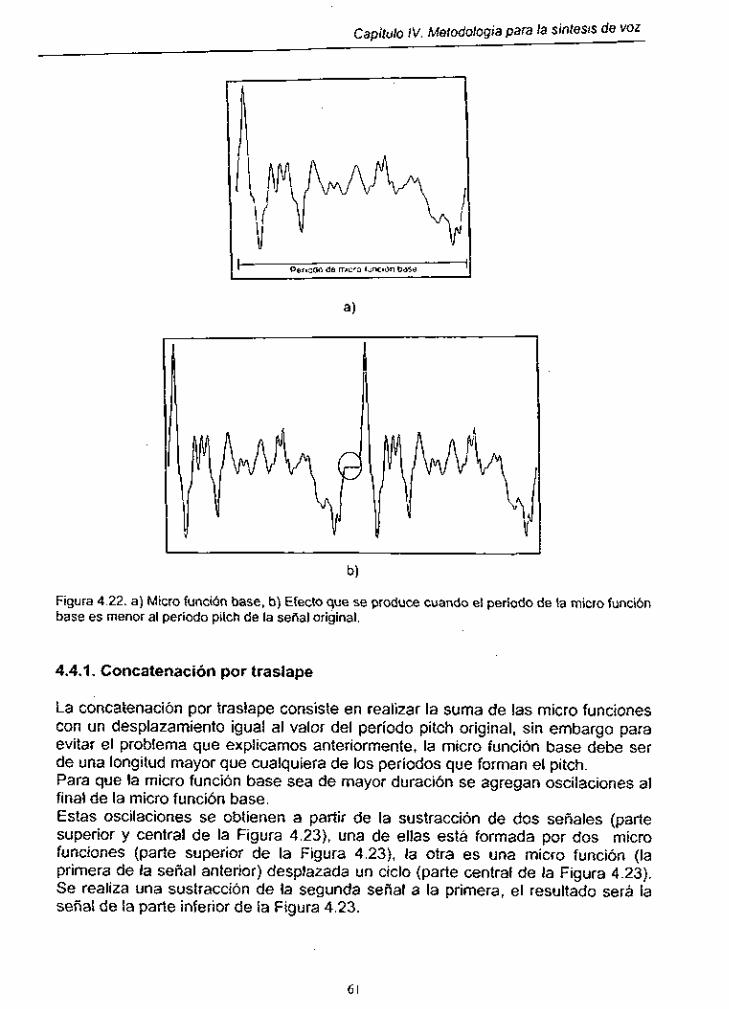
Capitulo IV. Metodologia para la sintes6 de VOZ
b)
Figura 4.22. a) Micro función base, b) Efecto que se produce cuando el periodo de la micro funcitm base es menor al periodo pitch de la seiial original.
4.4.1. Concatenación por traslape
La concatenación por traslape consiste en realizar la suma de las micro funciones con un desplazamiento igual al valor del período pitch original, sin embargo para evitar el problema que explicamos anteriormente, la micro función base debe ser de una longitud mayor que cualquiera de los períodos que forman el pitch. Para que la micro función base sea de mayor duración se agregan oscilaciones al final de la micro función base. Estas oscilaciones se obtienen a partir de la sustracción de dos señales (parte superior y central de la Figura 4.23), una de ellas está formada por dos micro funciones (parte superior de la Figura 4.23), la otra es una micro función (la primera de la señal anterior) desplazada un ciclo (parte central de la Figura 4.23). Se realiza una sustracción de la segunda señal a la primera, el resultado sera la señal de la parte inferior de la Figura 4.23.
61
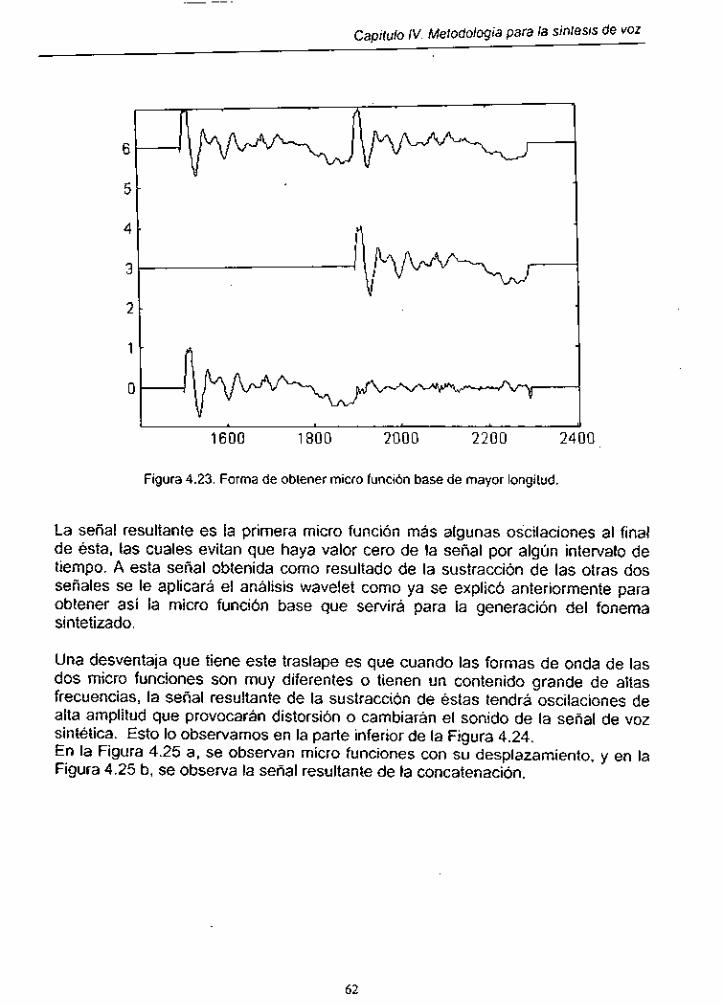
Capiiulo IV. Metodologia para la sintesis de voz
1
6
5 -
4 -
3 2 - \w\
Y
Figura 4.23. Forma de obtener micro función base de mayor longitud.
La señal resultante es la primera micro función más algunas oscilaciones al final de ésta, las cuales evitan que haya valor cero de la señal por algún intervalo de tiempo. A esta señal obtenida como resultado de la sustracción de las otras dos señales se le aplicará el análisis wavelet como ya se explicó anteriormente para obtener así la micro función base que servirá para la generación del fonema sintetizado.
Una desventaja que tiene este traslape es que cuando las formas de onda de las dos micro funciones son muy diferentes o tienen un contenido grande de altas frecuencias, la señal resultante de la sustracción de éstas tendrá oscilaciones de alta amplitud que provocarán distorsión o cambiarán el sonido de la señal de voz sintética. Esto lo observamos en la parte inferior de la Figura 4.24. En la Figura 4.25 a, se observan micro funciones con su desplazamiento, y en la Figura 4.25 b, se observa la señal resultante de la concatenación.
62
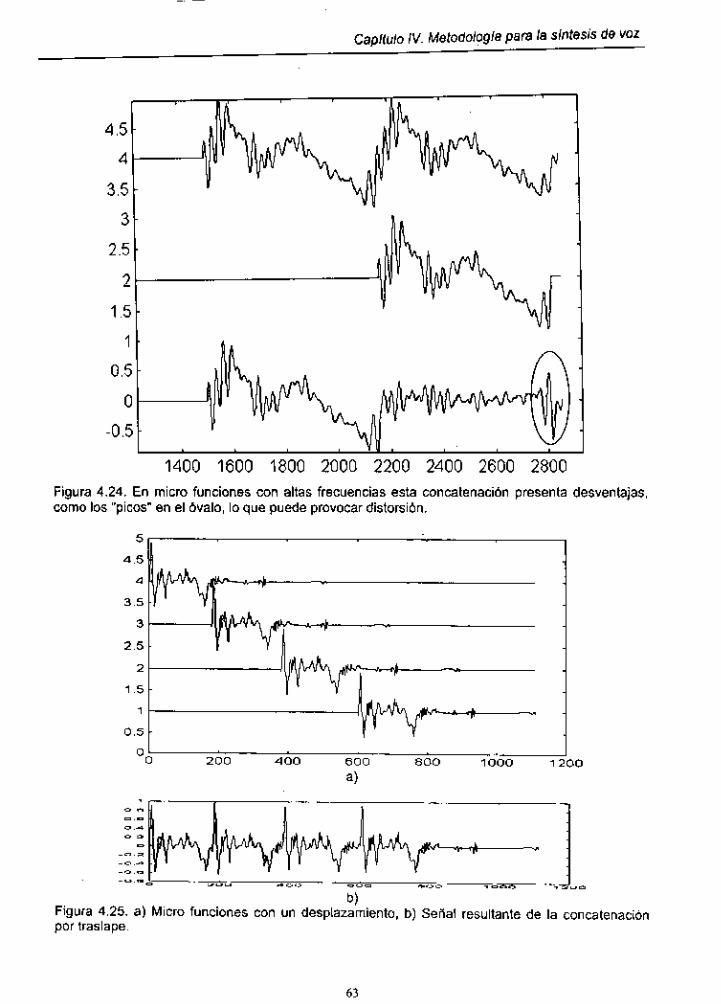
_ -
Capffulo /V. Metodologfa para /a sfntesis de VOL
1400 1600 1800 2000 2200 2400 2600 2800 Figura 4.24. En micro funciones con altas frecuencias esta concatenación presenta desventajas, como los "picos" en el óvalo, lo que puede provocar distorsi6n.
5
4 5
1 5 -
u
0 5 -
O O 200 400 600 800 1 O00 1200
a)
b) Figura 4.25. a) Micro funciones con un desplazamiento, b) Señal resultante de la concatenación por traslape.
63
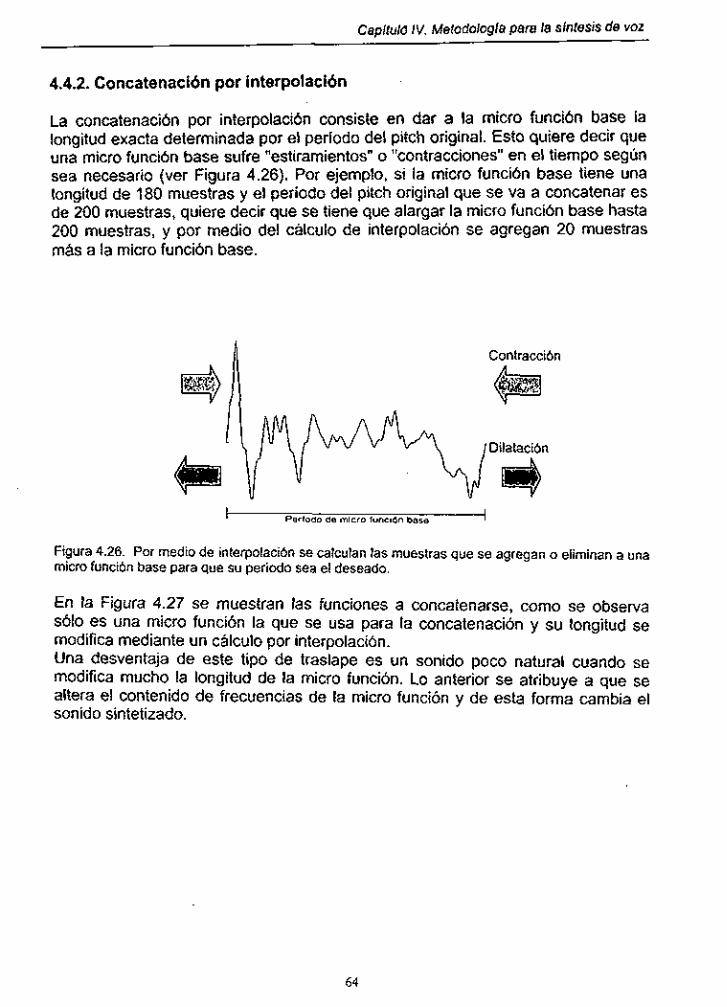
Caplfuld IV. Metodologla pera la slnfesis de VOL
4.4.2. Concatenación por interpolación
La concatenación por interpolación consiste en dar a la micro función base la longitud exacta determinada por el período del pitch original. Esto quiere decir que una micro función base sufre "estiramientos" o "contracciones" en el tiempo según sea necesario (ver Figura 4.26). Por ejemplo, si la micro función base tiene una longitud de 180 muestras y el período del pitch original que se va a concatenar es de 200 muestras, quiere decir que se tiene que alargar la micro función base hasta 200 muestras, y por medio del cálculo de interpolación se agregan 20 muestras más a la micro función base.
Contracción
I Perlodo de micro función base I
Figura 4.26. Por medio de interpolación se calculan las muestras que se agregan o eliminan a una micro función base para que su período sea el deseado.
En la Figura 4.27 se muestran las funciones a concatenarse, como se observa sólo es una micro función la que se usa para la concatenación y su longitud se modifica mediante un cálculo por interpolación. Una desventaja de este tipo de traslape es un sonido poco natural cuando se modifica mucho la longitud de la micro función. Lo anterior se atribuye a que se altera el contenido de frecuencias de la micro función y de esta forma cambia el sonido sintetizado.
64
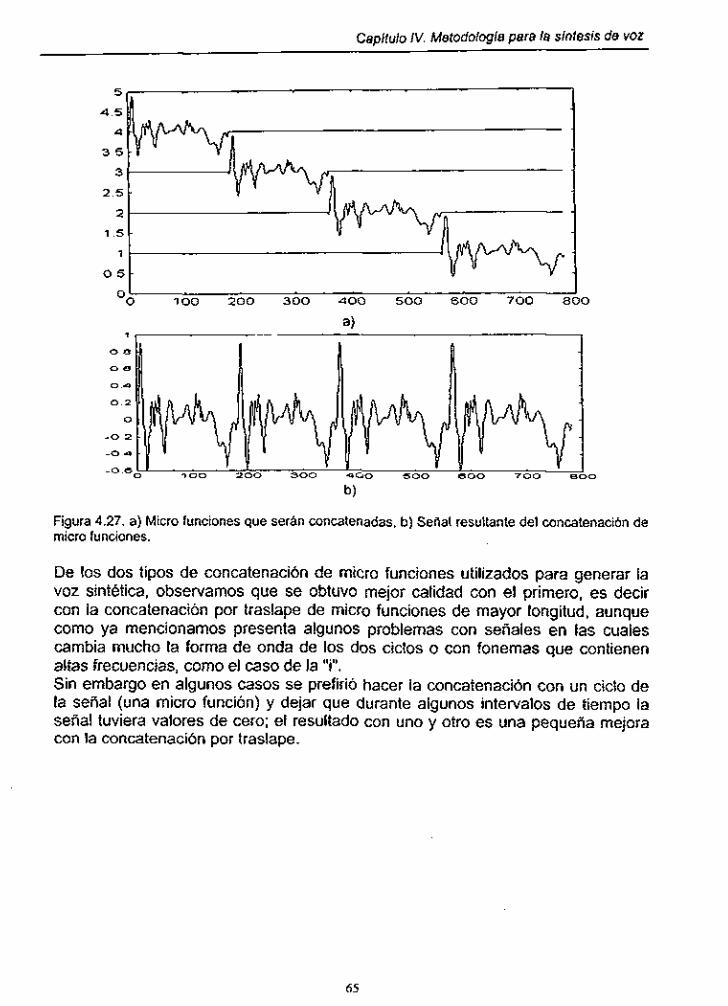
Capltulo IV. Metodologla para le síntesis de voz
2 5 -
1 5 -
0 5 - I
0; 100 200 300 400 500 600 700 800
a)
700 800 - 0 0 200 300 400 500 goo
b)
Figura 4.27. a) Micro funciones que serán concatenadas. b) Señal resultante del concatenación de micro funciones.
De los dos tipos de Concatenación de micro funciones utilizados para generar la voz sintética, observamos que se obtuvo mejor calidad con el primero, es decir con la concatenación por traslape de micro funciones de mayor longitud, aunque como ya mencionamos presenta algunos problemas con señales en las cuales cambia mucho la forma de onda de los dos ciclos o con fonemas que contienen altas frecuencias, como el caso de la "i". Sin embargo en algunos casos se prefirió hacer la concatenación con un ciclo de la señal (una micro función) y dejar que durante algunos intervalos de tiempo la señal tuviera valores de cero; el resultado con uno y otro es una pequeña mejora con la concatenación por traslape.
65

Capitulo IV. Melodologia para la síntesis de voz
4.5. METODOLOGiA PROPUESTA PARA LA SiNTESlS DE VOZ
Finalmente en esta sección se presenta la metodologia propuesta para el proceso de sintesis. Primeramente en la parte de análisis de voz, se hace una extracción del período del pitch y de la amplitud de la envolvente de la forma en que se explicó en la sección 4.3.3 (ver Figura 4.28, bloque SI), estos dos parámetros son almacenados en vectores que contienen, en el caso del periodo del pitch, la duración (en muestras) de cada ciclo de la señal; en el caso del vector de la amplitud de la envolvente cada elemento de dicho vector representa la amplitud máxima de cada ciclo. El siguiente paso es hacer un seccionamiento de la señal de voz (bloque 82 en la Figura 4.28), con la finalidad de tomar una micro función de cada sección y aplicarle el análisis wavelet. Dependiendo del tipo de sonido se hace un seccionamiento como se explicó en la sección 4.3.2, para realizar el seccionamiento es necesario conocer la duración de cada ciclo de la señal, es por eso que es importante extraer el período del pitch con anterioridad a este proceso. AI igual que el procedimiento usado en el seccionamiento de la señal de voz, el número de secciones de la señal está determinado por el sonido a sintetizar. A cada micro función seleccionada de cada sección se le aplica la transformada wavelet usando el wavelet Symmlet y posteriormente se hace una discriminación de coeficientes como se explica en la sección 4.3.4.2 (bloque 83 en Figura 4.28), el resultado de este proceso es obtener los coeficientes wavelets de una micro función base, además de un vector con el período del pitch y otro con la amplitud de la envolvente.
Se de ' -
en bloques
Micro función base del bloque n
Bloque 5
Coeficientes
Transformada
coeficientes
Detecci6n del periodo y waveiety micro funci6n amplitud discriminacion de base del
bloque n
Figura 4.28. Diagrama a bloques del proceso de análisis de voz
En la parte de síntesis, se aplica la transformada wavelet inversa a los coeficientes wavelets de una micro función base (bloque en la Figura 4.29) se obtiene una micro función base sintetizada o "prototipo". generación de un sección de la señal sintetizada se lleva a cabo media la concatenación por traslape (explicada en la sección 4.4.1) de la micro base sintetizada y usando el período del pitch y la envolvente de la original (bloque B5 en la Figura 4.29).
66

Capitulo IV. Metodologia para la síntesis de voz
Coeficientes wavelet de, micro funci6n base del bloque n
Finalmente los bloques se unen para formar el sonido sintetizado (bloque 66 en la Figura 4.29).
Bloque n 84 Micro funci6n 81 base
Transformada sintetizada ConcatenacjOn reconsiruido wavelet inversa. ’ por trasiape
bloques
Bloque 5
Figura 4.29. Diagrama a bloques del proceso de síntesis.
4.6. RESULTADOS
Debido al cambio en la forma de onda de los sonidos (fonemas o sílabas), incluso de micro función a micro función y a que no se encontró una regla que determine este cambio, es necesario el procedimiento para seccionar el fonema o sílaba para llevar a cabo un análisis de las señales de voz por bloques. El procedimiento de seccionamiento para fonemas semivocales tiene buenos resultados, pero depende en gran medida del cambio significativo en la forma de onda de los ciclos de la señal de voz, es decir, para lograr un buen seccionamiento mediante este procedimiento es necesario que el cambio de la forma de onda (de consonante a vocal) sea marcado, de esta forma la operación de correlación tendrá un valor pequeño en los ciclos donde se presenta la transición de consonante a vocal. De no haber un cambio significativo en la forma de onda el procedimiento de seccionamiento no detectará el cambio de consonante a vocal y como procedimiento alternativo tendrá que dividir el fonerna o sílaba en tres secciones de igual longitud. Este procedimiento de seccionamiento se aplicó a las partes vocálicas de sonidos explosivos y fricativos con buenos resultados, ya que al tomar tres micro funciones para analizar la parte vocálica se obtienen sonidos con mejor inteligibilidad. Lo anterior implica que mientras mayor sea el número de micro funciones que se tomen para el análisis mejor será la calidad de la señal sintetizada; aunque al tomar más micro funciones se tiene el inconveniente de que la cantidad de información para generar un sonido sintético aumenta. El procedimiento de extracción del período pitch y de la amplitud envolvente usado en este proyecto está basado en un análisis en dominio del tiempo. por lo que presenta errores en la detección de la duración de los primeros y últimos ciclos de la señal (ciclos de menor amplitud), esto se debe a que es necesario proponer un
67

Capitulo IV. Mefodoiogia para la sinfests de voz
de amplitud umbral Para discriminar señales que podrian ser ruido y algunas este valor es mayor a la amplitud de los "picos" maximos de algunos ciclos,
por 10 que son discriminados: este.problema tambibn se presenta cuando el sonido está compuesto de altas frecuencias. Sin embargo el procedimiento funcionó en forma aceptable para grabaciones de VOZ con niveles bajos de ruido. Para el análisis se usó la transformada wavelet ya que el algoritmo es más rápido, realiza menos operaciones y se disponen de las herramientas de software suficientes. Existe poca variación entre el número de coeficientes necesarios para reconstruir una señal con los wavelets utilizados, sin embargo la menor cantidad de coeficientes se obtuvo con los wavelet de interpolación promedio y Symmlet. Debido a que la diferencia entre el número de coeficientes con estos dos últimos es pequeña, se decidió usar el wavelet Symmlet para el análisis de los fonemas sintetizados. La herramienta de los wavelets resultó satisfactoria para analizar las señales de voz. Un ejercicio que muestra la bondad de esta herramienta es que se sintetizó una grabación de voz del fonema "a" y se aplicó la transformada wavelet a toda la señal de voz, posteriormente se discriminó un cierto número de coeficientes y se aplicó la transformada inversa. La señal obtenida fue de una calidad buena, casi idéntica a la señal original y con muy buena inteligibilidad. De las dos formas de concatenar micro funciones, la concatenación por traslape presentó mejores resultados en comparación con la concatenación Por interpelación. Esta última presenta un sonido poco natural cuando se Presenta un cambio grande entre el valor del período del pitch.
4.6.1. Generación de fonemas y sílabas
Como ya se dijo antes, la idea fue partir de micro funciones con el fin de reducir la cantidad de información necesaria para generar voz artificial sacrificando la calidad de la voz sintetizada pero con suficiente inteligibilidad. Una micro función tiene una duración variable dependiendo de varios factores, generalmente su duración está alrededor de 180 y 250 muestras (a 22 KHz de frecuencia de muestreo) más la duración de la oscilación de Concatenación descrita en la sección 4.4.1. En este trabajo se propuso una duración para cualquier micro función base de 512 muestras, de tal forma que si la micro función base analizada es menor de 512 muestras se insertan valores cero para completar un vector de 512 muestras. El proceso de análisis da un vector que contiene los coeficientes wavelets, la longitud de éste es la misma que la señal analizada, pero el número de coeficientes diferentes de cero es mucho menor a 512 valores. De lo anterior tenemos que la cantidad de información necesaria para generar voz sintetizada es un vector menor a 512 muestras (vector de coeficientes wavelets), más dos vectores de amplitud y período del pitch con longitud variable dependiendo del número de ciclos en el fonema o sílaba grabada.
68

Capitulo IV. Metodologia para la sinlesis de voz
Como ejemplo se tiene que para el fonema "a" de 8192 muestras se obtiene un vector de los coeficientes wavelets con una longitud de 160 datos ya comprimido, además de un vector con el período del pitch y otro de amplitud de la envolvente con 30 y 31 datos respectivamente; esto da como resultado 220 datos para generar el sonido de la "a" en forma sintetizada, que representa una compresión de aproximadamente 37 veces, claro que sin la misma calidad que la señal original. Para el caso de un fonema fricativo como "sa" con una longitud de 12000 muestras de datos, se extraen cinco micro funciones más el ruido inicial, que resulta en 4025 datos, por lo que se tiene una compresión de aproximadamente de 3 veces. Se hizo el experimento de aplicar la transformada wavelet a todo un fonema (el fonema "a") y discriminar algunos de los coeficientes wavelets menos representativos, de tal forma que no se afectara la calidad de la señal de voz y se obtuvo como resultado una compresión aproximada a 5 veces con una calidad muy parecida a la señal original.
4.6.2. Generación de palabras
Como validación de la metodologia y para observar la calidad de la síntesis de voz se formaron palabras sintetizadas. Hasta aqui la metodologia permite solamente sintetizar sonidos de fonemas o sílabas; se intentó articular palabras mediante la concatenación de sonidos sintetizados a partir de grabaciones de fonemas y sílabas aisladas. El resultado no fue satisfactorio (no hay suficiente inteligibilidad), puesto que las sílabas no tienen las características de pitch y envolvente que tendría una sílaba extraída dentro del contexto de la palabra. Por otra parte se tomaron las sílabas extraídas de una palabra y se les aplicó la metodología propuesta en este trabajo, el resultado fue una síntesis con suficiente inteligibilidad.
Palabra 'casa" -
Sllaba'ca- C o d wavelets. pi,ch y Generación de sintetizada
análisis para 1-4 voz sintetica I palabra sonidos .Cas$
II
Generación de voz sintética
sonidos
fricativos I U
Figura 4.30. Proceso de síntesis para la palabra "casa" tomando las sílabas de la grabacibn de "casa".
Por lo anterior, concluimos que se pueden sintetizar fonemas y sílabas a partir de grabaciones aisladas mediante 'la metodología propuesta y obtener suficiente inteligibilidad, pero cuando dichos fonemas y sílabas formen parte de una
69
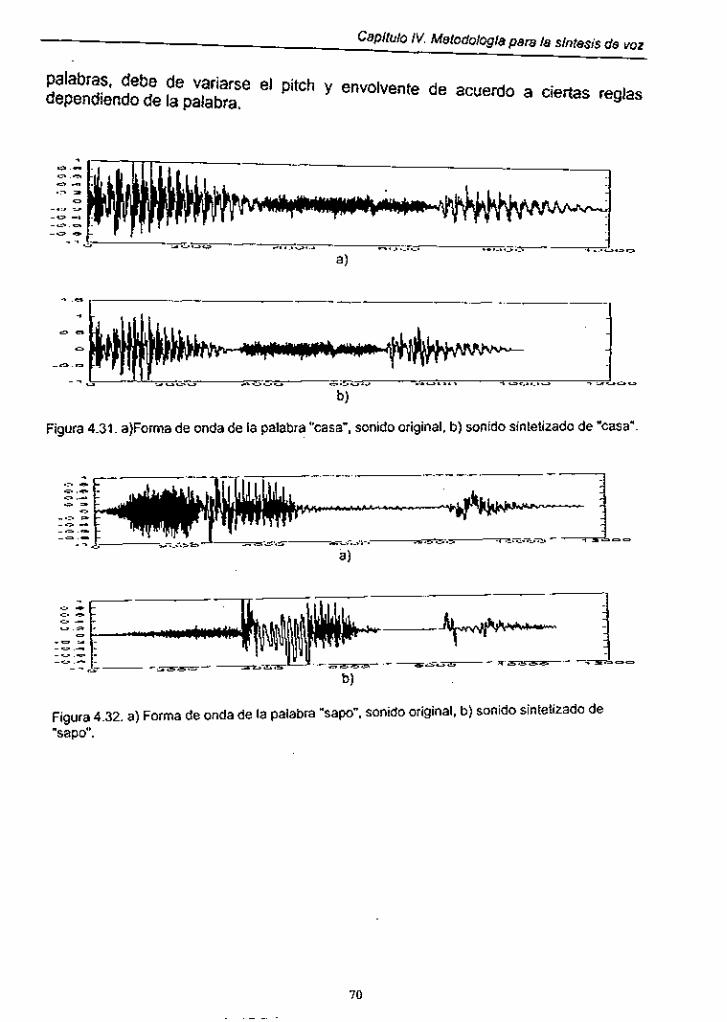
Cepltulo IV. Metodologle pare le slnfesis de voz
palabras, debe de variarse el pitch y envolvente de acuerdo a ciertas reglas dependiendo de la palabra.
1 _____- I _. .-
Figura 4.31. a)Forma de onda de la palabra "casa", sonido original, b) sonido sintetizado de "casa".
Figura 4.32. a) Forma de onda de la palabra "sapo", sonido original, b) sonido sintetizado de "sapo".

Capitulo V. Conclusiones
CAPíTULO V CONCLUSIONES
5.1 CONCLUSIONES
De los resultados obtenidos se puede concluir que la aplicación de los wavelets a señales de voz presentó buenos resultados debido a que se obtiene una disminución en la cantidad de información necesaria para reconstruir la señal de voz; sin embargo la calidad de la voz sintetizada no es muy buena, esto se debe a dos factores: la primera causa es que como se esperaba al tomar algunas micro funciones para generar un fonema se discrimina gran parte de la variación del espectro de frecuencia de la señal de voz, y es por eso que la metodología propuesta funciona mejor para sonidos con espectros de frecuencias más o menos constantes (como en el caso de las vocales). La segunda causa es que el método de concatenación por traslape puede distorsionar la forma de onda de la señal sintetizada cuando se hace la suma de micro funciones. Las principales aportaciones del trabajo son:
Se propone una metodología para realizar la síntesis de voz a partir de micro funciones. Se propuso una metodología para seleccionar micro funciones base utilizadas en el proceso de análisis de las señales de voz (seccionamiento del fonema).
71

Capitulo V. Conclusiones
Se desarrollaron herramientas para posteriores trabajos sobre el tema.
Puesto que aún existen aspectos que se pueden mejorar en este trabajo, a continuación se recomiendan algunos trabajos futuros,
5.2 TRABAJOS FUTUROS
Para mejorar la calidad se requiere un mejor método de concatenación de micro funciones, as¡ como también encontrar una regla que permita reproducir la variación de la forma de onda de las micro funciones, es decir la variación del contenido de frecuencias en la señal de voz.
coeficientes
Figura 5.1. Esta gráfica muestra la variación de los coeficientes wavelets de cada ciclo o micro función que forman al fonema "a". El eje de amplitud de coeficientes representa la amplitud relativa de los coeficientes wavelets, el eje de No. de micro función representa la micro función del fonema y el eje restante es el coeficiente wavelet.
Obtener las reglas que permitan conocer el comportamiento del pitch y envolvente en las palabras a sintetizar, para de esta forma dar la adecuada entonación a la palabra.
Realizar un sistema capaz de procesar cadenas de texto para traducirlas a información fonética, y de esta forma completar un sistema TTS. Principalmente establecer las reglas que permitan seleccionar adecuadamente el sonido correspondiente a determinado carácter o símbolo fonético, esto resultará en una mayor inteligibilidad.
72

Referencias
REFERENCIAS
[ I ] Alan V. Oppenheim, Aplications of Digital Signal Processing, Prentice Hall, U.S.A., 1978, p. 117
[2] Ibidem, p. 118
[3] Thomas Parsons, Voice and speech processing. McGraw-Hill, U.S.A., 1987, pp. 277-281
[41 T. Dutoit, "A short introduction to TTS Synthesis", disponible en: httP://tcts.fPms.ac.be/synthesis/introtts.html. Consultado en diciembre 1997
[SI Olivier Rioul Y Martin Vetterli, "Wavelet and signal Processing" , Signa/ processing magazine. Octubre 1991, pp.14-15
(61 Andrew Bruce, "Wavelet Analysis", Spectrum. Octubre 1996, p. 26
[7] idem
[8] ibidem, p. 27
[9] I. Daubechies, Ten lectures on wavelets, SIAM, U.S.A., 1992.
[IO] M. Kobayashi, "Wavelet analysis used in text - to - speech synthesis", IBM Japan. Septiembre 1995, pp 1-13.
[ I l l "Speech segment coding and pitch control methods for speech synthesis systems", R. Lee Chong y K. P. Yong, U.S.A.: Patent No. 5617507. April 1997.
[I21 M. Kobayashi, op. cit., p. 5.
[13] Thomas Parsons, op. cit.,pp. 59-66.
[I41 idem
[I51 B.H. Juang, "The past, present, and future of specch processing", Signal processing magazine. Mayo 1998, pp.25-26
[ I 61 Yoshinori Sagisaka, "Spoken output technologies: A global view of synthesis research" en: Ronald A. Cole, Center for spoken languaje understanding, Survey of the state of the art in human languaje tecnology, Oregon Graduate Institute, Noviembre 1995, pp. 189-190, Consultado en:http://cslu.cse.ogi.edu/learn/. Diciembrel998.
73

Referencias
7l d'Alessandro Christophe Y Lienard Jean-Sylvgin, "Spoken output technologies: Synthetic speech generation" en: Ronald A. Cole, Center for spoken languaje understanding, su"W of the state of the art in human languaje tecnology, Oregon Graduate Institute, Noviembre 1995, pp. 196-1 97, Consultado en: http://cslu.cse.ogi.edu/learn/.. Diciembre 1998.
[I81 Real Academia Española, D'iccionario de la lengua española, vigésima primera edición,l992, España, p. 407.
[I91 Yoshinori Sagisaka, op. cit., p. 191
[20] S. Nakajima y H. Hamada,"Automatic generation of synthesis units based on context oriented clustering", Proceedings of tehe 7988 lnfernafional Conference on Acoustics, Speech and Signal Processing, IEEE, Nueva York, pp.659-662.
[21] K. Takeda, K. Abe e Y. Sagisaka, "The basic' scheme and algorithms in non- uniform units speech synthesis", en: G. Bailly y C. Benoit, Talking Machines: Theories, Models and Designs, Elsevier Science, pp. 287-304.
(221 Y.Sagisaka y N. Kaiki, "ATR v-Talk speech synthesis system", Proceedings of the 7992 lnternafional Conference on Spoken Language Processing, Vol. 1, Banff Alberta, Canada, pp. 483-486.
[23] Yoshinori Sagisaka, op. cit., p. 192
[24] Thomas Parsons, op. cit., pp. 197-204.
[25] idem
[26] M. Sondhi, "New methods of pitch extraction", /€€E Trans., Vol. AU-16, NO. 2, Junio 1968, pp. 262-266.
[27] A. M. Noli, "Cepstrum pitch determination", J ASA, Vol. 41, No. 2, Febrero
[28] B. Gold y L. Rabiner, "Parallel processing techniques for estimating pitch periods of speech in the time domain", J ASA, Vol. 46, No. 2, Agosto 1969, pp.
[29] N. J. Miller, "Pitch detection by data reduction", /€€E Trans., Vol. ASSP-23, No. 1, Febrero 1975, pp. 72-79.
[30] John G. Proakis, Digital signal processing: principles, algorithms and aplications, Tercera edición, Prentice Hall, U.S.A., 1996, pp.118-I24
[31] Jose E. Torres Fernández, "Diseño y realización de un sistema de síntesis de señales de voz", (Tesis, Facultad de ingeniería, UNAM, México, 1995) p. 12
1967, pp. 739-746.
442-448.
1 4

! Referencias
I
I , [32] Alan V. Oppenheim y Alan S. Willsky, Señales y sistemas, Prentice Hall, México,l994, pp.176
[33] Hwei P. HSU, Análisis de Fourier, Primera Edición, Adisson-Wesley Iberoamericana, U.S.A., 1970, p. 4
[34] Alan V. Oppenheim y Alan S. Willsky, op. cit., p. 200
[35] Gerald Kaiser, A friendly guide to wavelets, Primera Edición, Birkhauser, U.S.A., 1994, p. 52
[361 R. Polikar, "Wavelet Tutorial part 111, Multiresolution analysis and the continous Wavelet transform", disponible en: http://www.public.iastate.edu/-rpolikarNVAVELETNVTpart3. html. Consultado en Diciembre 1998, p. 1
[37] Gerald Kaiser, op. cit., p. 44
[38] Andrew Bruce, op. cit., p. 28
[39] Olivier Rioul y Martin Vetterli, op. cit., p.17
[40] R. Polikar, op. cit., pp. 23-25
(411 Olivier Rioul y Martin Vetterli, op. cit., pp. 20-27
[42] ibidem, pp. 27-29
[43] Mac A. Cody, "The fast wavelet transform beyond Fourier transform", Dr. Dobb's Journal. Abril 1992, p. 4
[44] R. Polikar, op. cit., pp. 1-10.
[45] Kannan Ramchandran y Martin Vetterli, "Wavelets, subband coding, and best bases", Proceedings of /€€E, Vol. 84, No.4. Abril 1996, PP. 542-543
[46] Mac A. Cody, op. cit., pp. 3-4
[47] Jonathan Buckheit, Shaobing Chen, David Donoho, Ian Johnstone, Wavelab Reference Manual, Stanford University and Nasa-Ames Research Center, versión 0.700. Diciembre 1995, Disponible en: http://playfair.stanford.edu/-wavelab. Consultado en abril 1998, pp. 153,158,162.

Referencias
[481 Ben Serridge Y Alejandro Barbosa, "Creating a mexican Spanish version of the CSLU toolkit". Universidad de las Amkricas, Puebla, México and the Center for Spoken Languaje Understanding, Oregon Graduate Institute of Science and Tecnology.
[49] M. Kobayashi, op. cit.
[SO] Comisión de gramática de la real academia española, Esbozo de una nueva gramática de la lengua española, Espasa,1998, España, pp.8-159.
[51] Manuel Seco, Gramática Esencial de la lengua española, Espasa, 1998, España, pp. 69-96
[52] ASCII Phonetic symbols for Mexican Spanish. Consultado en: http://info.pue.udlap.mx/-sistemas/tlatoa/labels.html. Noviembre de 1998.
[53] Real Academia Española, Op. Cit., PP. 694,1332.
[54] Thomas Parsons, op. cit., pp. 197-204.
[55] N. J. Miller, op. cit., pp. 72-79.
16

Apéndice A
APÉNDICE A DOCUMENTACIÓN DE FUNCIONES DE SOFTWARE
Este apendice tiene el propósito de explicar la forma de usar las funciones de software desarrolladas en esta tesis. Todos los programas fueron desarrollados para su ejecución bajo el ambiente del paquete Matlab versión 4.2, además debe incluirse el toolbox Wavelab versión 7, el cual se puede obtener de internet en la dirección: http://playfair.stanford.edu/ -wavelab.
Señales de voz Las señales de voz que se manejan dentro del ambiente del paquete Matlab, son importadas de archivos de sonido con extensión wav, por medio de la función que incluye Matlab: wavread.
Sintaxis: [y] = wavread ('archivo')
Variables: 'archivo' = Nombre del archivo con extensión wav y = vector con la señal de sonido
El vector con la señal de salida tiene un nivel de desplazamiento (un valor de 128), debido al formato en que se almacenan los datos en los archivos de sonido, para manejar estas señales de voz es necesario hacer una sustracción:
senal-voz = y -128;
Finalmente para tener el vector con la señal de voz de una manera adecuada para su manipulación se hace una normalización de la señal usando la función normaliz.
Sintaxis: fonerna = normaliz (senal-voz);
Variables: Senal-voz = señal a normalizar Fonema = señal normalizada
77

. I Apéndice A
I A.1. FUNCIONES PRINCIPALES I
Fonema “ A “ E “ I“
“ O “U“
I
La función sintevoc realiza todo el proceso de análisis y sintesis para un sonido vocálico, de tal forma que dados los pará’metros de entrada se obtiene una señal sintetizada al término de la ejecución del programa.
Función para síntesis de vocales I
I Opción I 1
2 3 4 5
\
I - I Sintaxis:
[Coefw, Microf-s, Fon-sl, Fon s2] = sintevoc (Fonerna,Opción)
I Variables: Fonema = señal de voz original. Opción = número correspondibnte a la vocal (ver tabla A.l) . Coefw = vector con coeficientes wavelets normalizados, de O a 255, donde el valor de 128 represehta el cero. Microf-s = vector con micro función base sintetizada. Fon-sl = vector con la señal de voz sintetizada usando el procedimiento de concatenacih por traslape. Fon s2 = vector con la señal de voz sintetizada usando el pro&dimiento concatenación $or interpolación.
I
I I Microf s, Funcióh Fonemad
I
I
sin te voc
Figura A.1. Diagrama a bloques.
78

Apéndice A
Función para síntesis de sernivocales La función SifJteSem realiza el proceso de análisis y sintesis para sonidos semivocales y nasales. con la señal de voz original se obtiene una señal sintetizada al término de la ejecución del programa.
Sintaxis: [Fon - SI, Fon - s2]=sintesern (Fonema);
Variables: Fonema = señal de voz original. Fon SI = vector con la señal de voz sintetizada usando el procedimiento de concatenación por traslape. Fon-s2 = vector con la señal de voz sintetizada usando el procedimiento concatenación por interpolación. -
Función sintesem .
Figura A.2. Diagrama a bloques,
Función para síntesis de explosivas u oclusivas La función sintexp ai igual que las anteriores, realiza un análisis y síntesis para los sonidos oclusivos.
Sintaxis: [Fons l , Fon-s2] = sintexp (Fonema);
Variables: Fonema = señal de voz original. Fon-sl = vector con la señal de voz sintetizada usando el procedimiento de concatenación por traslape. Fon-s2 = vector con la señal de voz sintetizada usando el procedimiento concatenación por interpolación.
u Figura A.3. Diagrama a bloques
19

Apéndice A
Función para sintesic de fricativas La funci6n S M f i sintetiza sonidos fricativos dado un vector de entrada, el cual es el vector de voz original.
Sintaxis: [fon-sl , fons21 = sintfri (fonema);
fonema = señal de voz original. fon-sí = vector con la señal de voz sintetizada usando el procedimiento de concatenación por traslape. fon-s2 = vector con la señal de voz sintetizada usando el procedimiento concatenación por interpolación.
Variables:
I I
Figura A.4. Diagrama a bloques
A.2. FUNCIONES UTILIZADAS POR FUNCIONES PRINCIPALES
Función maxis. Identifica los puntos máximos y mínimos en una forma de onda (detecta los cambios en el signo de las pendientes).
[maximos] = maxis(sena1);
sena1 = vector con la señal de entrada. maximos = vector con los puntos máximos.
Sintaxis:
Variables:
Función buscap25. Extrae el período del pitch, la amplitud de la envolvente de un fonema, además de una micro función con su posición de inicio y fin.
Sintaxis: [pitch,vec~amp,microfun,inicio,inter,final,puntos] = buscap25(onda,fonema);
80

Apdndice A
Variables: onda = máximos del fonema(resu1tado de la función maxis). fonema = Señal de voz. pitch = vector con el periodo del pitch . vecamp = vector de amplitud de la señal. microfun = dos ciclos de la señal original. inicio = Posición inicial de la micro función. inter = Posición intermedia de la micro función. final = Posición final de la micro función. puntos = vector con inicio y fin de los ciclos.
Función ressen. Realiza un desplazamiento en una micro función y resta la segunda micro función como lo explica el procedimiento de concatenación por traslape.
Sintaxis: [micro,microt] = ressen(micro-F,inic,int,fin);
micro-F = micro funciones de entrada. ink = inicio de la primera micro función. int = fin de la primera micro función. fin = fin de la segunda micro función. micro = contiene la señal resultante de la resta. microt = contiene la primera micro función sin cambios.
Variables:
Función Anv. Este programa realiza el análisis y reconstrucción de una señal utilizando la .~ transformada wavelet.
Sintaxis: [wc,recons] = Anv(sena1,op);
sena1 = señal de entrada. op = opción dependiendo de la letra. wc = coeficientes wavelets. recons = micro función reconstruida.
Variables:
81

Apéndice A
Función norrn256. Normaliza un vector con valores positivos y negativos a valores positivos con un desplazamiento de 128, es decir, valores de O a 255.
Sintaxis: [sal] = norm256(vec);
Variables: vec = vector a normalizar. sal = vector normalizado.
Función cctv. Concatena micro funciones por el método de traslape.
Sintaxis: [sen] = cctv (suma, amplitud, pitch);
suma = micro función base. amplitud = vector de la amplitud de la envolvente. pitch = vector con el periodo del pitch. sen = señal concatenada.
Variables:
Función ccfsrnod. Esta función concatena micro funciones por el procedimiento de interpolación.
Sintaxis: [sen,pot,amp] = cctsmod(suma,amplitud,pitch)
Variables: suma = micro función base. amplitud = vector de la amplitud de la envolvente. pitch = vector con el período pitch. sen = señal concatenada. pot = potencia de la señal. amp = vector amplitud.
Función carnbiouf. Realiza la correlación entre micro funciones continuas para conocer la variación de la forma de onda de micro función a micro función. Es usada para el seccionamiento de sonidos.
Sintaxis: [picos-m] = cambiouf(pitch,pts,fonema);
82

Apéndice A
Variables: pitch = vector con período del pitch. pts = vector con posición de inicio y fin de los ciclos. fonema = vector con señal de voz. picos-m = vector con variación de forma de onda.
Función maymes. Encuentra la posición del mayor cambio en la forma de onda de micro funciones contiguas.
Sintaxis: [mes~val,mes~pos,temporal] = maymes(senia1);
Variables: Senial = señal proveniente de cambiouf. mes-val = valor del cambio de pendiente. mes-pos = posición de la pendiente abrupta temporal = variaciones en ceros y unos.
Función Ansem. Este programa realiza el análisis de una señal y su reconstrucción utilizando la transformada wavelet.
Sintaxis: [wc,recons] = Ansem(sena1,op);
sena1 = señal de entrada. op = opción dependiendo de la letra. wc = coeficientes wavelets. recons = micro función reconstruida.
Variables:
Función selexp. Selecciona los coeficientes que corresponden a cada fonema.
Sintaxis: [II,12,13,14,15,n-l] = seiexp(1etra);
Variables: Letra = identificador del fonema. 11 ... 15 = número de coeficientes wavelet en cada nivel de resolución.
83

Apéndice A
Función cct03. Función para concatenar sonidos oclusivos.
Sintaxis: [sen,p]=cct03(suma,suma2,suma3,arnplitud,pitch);
Variables: suma = micro función del impulso inicial. suma2 = primera micro función. suma3 = siguiente micro función. amplitud = vector de amplitud de la envolvente pitch = vector del periodo del pitch. sen = señal concatenada. p = longitud del bloque concatenado.
Función cornpriv. Comprime una señal
Sintaxis: [vect] = compriv(sena1);
sena1 = vector con datos a comprimir. vect = vector comprimido.
Variables:
Función descornp. Descomprime señales comprimidas con la función compriv.
Sintaxis: [vecdes] = descomp(vecc);
vecc = vector comprimido. vecdes = vector descomprimido.
Variables:
Función coefmx. Este programa toma los coeficientes mas grandes de cada dyad(2)
Sintaxis: [posicion] = coefmx(vectemp,no-coef);

ApBndice A
Variables: vectemp = vector con los coeficientes. no-coef = número de coeficientes a tomar. posicion = posición de los coeficientes máximos.
Función modpitch. Este programa modifica la duración de una micro función.
[senal]=modpitch(suma,ptmp);
suma = micro función base. ptmp = duración del pitch deseado. sena1 = micro función modificada.
Sintaxis:
Variables: